本文主要是介绍话说校验和(checksum),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
转载自:https://blog.51cto.com/fengyun/472114
话说校验和(checksum)
推荐 原创
拿贝马凡2011-01-05 10:51:16©著作权
文章标签 职场 tcp/ip 休闲 文章分类 tcp/ip协议 阅读数 40512
| 好久没有写博文了,貌似不是没有时间,而是我比较懒,懒得打字,懒得动手。 |
这几天正在学习tcp/ip,一心血来潮,来看看校验和吧,检验和在链路层有,网络层有,传输层也有(udp与tcp都有,只不过tcp的是必须的,udp是可选的字段)。
注:ipv4版本有ip header 的checksum,而ipv6取消ip header的checksum,所以他的上层传输层就必须要有checksum(ipv4中的上层udp的checksum是可选字段)
先来看看链路层的frame format吧:标准的ethernet II的frame,rfc894定义的:
| destination mac address | source mac address | type | data | fcs |
source 与destination mac address各占6个字节,type占2个字节,fcs就是frame checksum seq占4个字节
在这里说下:最小的data部分为46个字节
The minimum length of the data field of a packet sent over an
Ethernet is 46 octets.
不管是router还是各个操作系统,如果data不足会不让你发送的,router我记得是36个字节,不足的他添加垫片
。抓个包看看吧:
- C:\>ping -l 1 192.168.1.1
- Pinging 192.168.1.1 with 1 bytes of data:
- Reply from 192.168.1.1: bytes=1 time<1ms TTL=255
- Reply from 192.168.1.1: bytes=1 time=12ms TTL=255
- Reply from 192.168.1.1: bytes=1 time=10ms TTL=255
- Reply from 192.168.1.1: bytes=1 time=10ms TTL=255

看到了吧,这么算下,一个packet最少为64个字节,减去frame header 14个字节(source与destination各6个字节,type字段2个字节)与fcs 4个字节,为64-18=46个字节。
上图中增加17个字节的垫片,加上ip header length为20个字节,icmp为8个字节,1个字节的数据部分
20+8+1+17=46个字节。(插一句话:一个switch的检测收到的frame一般就是检测前64个字节后转发)
另外链路层如何知道一个frame是ip,arp,rarp是根据type字段来的。然后在做相应的处理,比如说type为0806.就知道这个是个arp frame,交给arp好了,如果是这个0800,往上层网络层交就可以了。至于他怎么处理,那就不管我的事情,你网络层去解决吧。
看完链路层,在看看网络层把,网络层的协议太多了,ip,ipx,appletalk做为运载工具,为什么ip能做为tcp/ip协议栈的核心,所有的tcp,udp,icmp,igmp数据都由ip数据包格式来传输。
看看ip数据包格式吧
| Version | Header length | Tos | Total length | ||||
| 标识符 | df | Mf | 偏移位 | ||||
| Time to live | Protocol | Checksum | |||||
| Source address | |||||||
| Destination address | |||||||
| Option | |||||||
ip 数据报的字段为:
4个bit的version
4个bit的header length(ipv6中没有这个字段,因为ipv6固定为40个字节)因为有ipv4 数据报头部固定为20个字节,但是有option这个选项。所以用于标识ip header length)
8个bit的tos,前3位用于优先级(现在用的很少,主要用于qos)---这个字节我也不是很清楚。有那位精通,欢迎指教。
16个bit的报文总长度。
16个bit的标识符与16个bit偏移位(加有3个bit标志),主要用于报文分片。
8个bit的ttl值,本来是指经过一台设备所需要的时间,用1s就减去1s,现在是指跳数,经过一台router就减去1.
8个bit的protocol号,这个是标识协议的,是指为谁的数据进行传输,协议号6标识是tcp,17是udp,这时ip包就将数据向传输层交了,由上层的tcp与udp来处理了,如果是1,就交由icmp来处理。跟链路层的type意义差不多。
16个bit的校验和,---今天的重点。
32个bit的source ip address
32个bit的destination ip address
最大40个字节的option选项
里面记录经过的路由(只能记录9个ip 爱到底,因为最大只有40个字节,一个ip地址占4个字节,还有3个字节的指针),指针等等,抓个包看看
- C:\>ping -r 9 220.181.111.85
- Pinging 220.181.111.85 with 32 bytes of data:
- Reply from 220.181.111.85: bytes=32 time=46ms TTL=53
- Route:
- 61.190.244.97 ->
- 118.84.1.1 ->
- 202.97.66.69 ->
- 220.181.16.13 ->
- 10.65.190.164 ->
- 10.65.190.21 ->
- 220.181.111.85
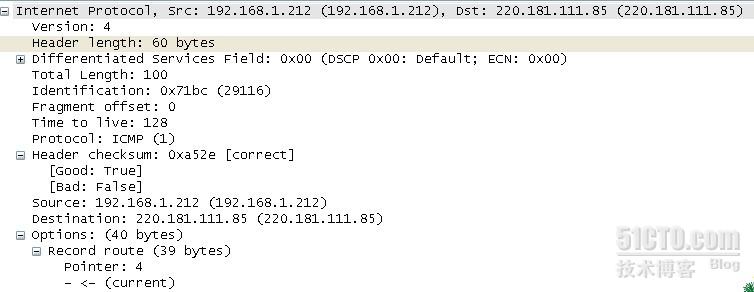
看到没有最大的ip header length为60个字节。
来说校验和,校验和应该叫16进制反码求和,就是将所有的字节加起来,再由ffff来减得到的值。
我这来计算ip header 的checksum,其他的校验和计算方式一样的
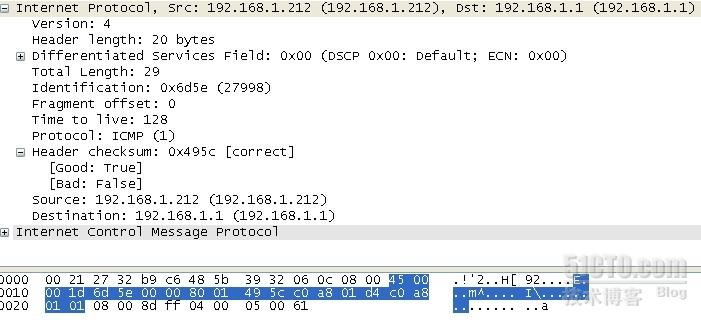
看header checksum为0X495c
整个ip header去除49 5c,为45 00+00 1d+6d 5e+80 01+c0 a8+01 d4+c0 a8+01 01=2B6A1(至于为什么00 00不加不解释)
2B6A1=B6A1+2=b6a3
ffff-b6a3=495c
看结果出来了吧,校验和是个很粗糙的计算方式(与md5相比),如果你source 与destination调换一下,结果相同,在链路层计算正确后到达网络层,经过ip头部校验可能还会出错,到达tcp或者udp也还可能出错,只是方便了网络设备的计算。当然你从source发往destination与destination发往source校验和肯定不会相同,应该里面的ttl与标识符会有差别。
在说下分片
分片的大小看接口的mtu值,而ethernet II的frame格式,data部分为1500个字节(这个data字段包括高层的信息与data)
咱来ping个大点的数据报,看操作系统是怎么处理的,ip header那些字段会有变动
- C:\>ping -l 6000 192.168.1.1
- Pinging 192.168.1.1 with 6000 bytes of data:
- Reply from 192.168.1.1: bytes=6000 time=3ms TTL=64
- Reply from 192.168.1.1: bytes=6000 time=3ms TTL=64
- Reply from 192.168.1.1: bytes=6000 time=2ms TTL=64
- Reply from 192.168.1.1: bytes=6000 time=2ms TTL=64
- Ping statistics for 192.168.1.1:
- Packets: Sent = 4, Received = 4, Lost = 0 (0% loss),
- Approximate round trip times in milli-seconds:
- Minimum = 2ms, Maximum = 3ms, Average = 2ms
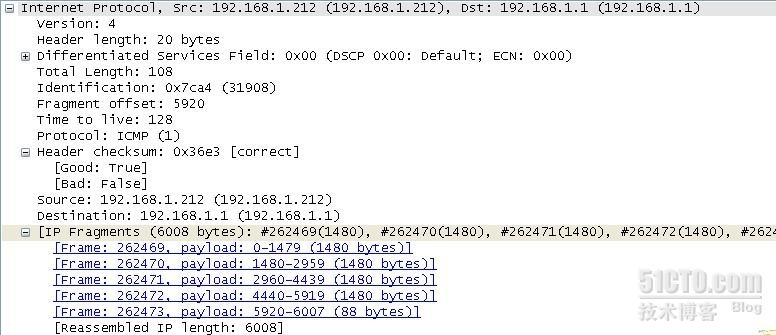
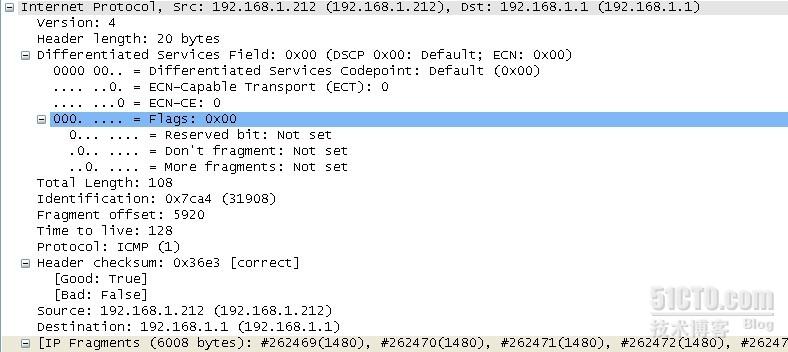
分片的目的是数据包太大,超过了接口的mtu值,所以必须将传输的数据包分成小于接口mtu值的大小传输。
destination设备为什么知道他分片,怎么将那几个片组合成一个数据包,靠的就是ip 头部中的标识符,标志与偏移位。(这里为什么ip数据报为6008,而不是我指定的6000字节,因为增加了8个icmp的头部)
一个完整的数据报别分片,但是每片的标识位都是一样的,这样目的设备知道了这时同一个数据报的分片。
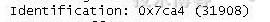
虽然抓的这个是最后一个分片,但是前面每个分片的这个字段都是一致的
另外看标志(flags)
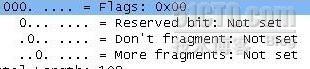
第3个比特没有啥用途,或者是我不知道
第2个比特是标识是否分片。如果是1就是不分片,0为分片
第3个比特是标识是否有下一个分片。只有最后一个分片这位为0,其他的都为1.
这个是不允许分片的结果
- C:\>ping -f -l 1600 192.168.1.1
- Pinging 192.168.1.1 with 1600 bytes of data:
- Packet needs to be fragmented but DF set.
- Packet needs to be fragmented but DF set.
- Packet needs to be fragmented but DF set.
- Packet needs to be fragmented but DF set.
- Ping statistics for 192.168.1.1:
- Packets: Sent = 4, Received = 0, Lost = 4 (100% loss),
偏移位(Fragment offse)标识(前面)发送了多少个字节的数据,这里是5920,即前面已经发送5920个字节,这里是最后一个分片,5920+88=6008.
如果分片会有那些字段改变呢,
看上面ip header的图
第一片
| ip header | option | protocols | 上层port | data |
其他片
| ip header | data |
首先,version是不会改变,不会从v4版本变成v6版本的
header length肯定会发生变化,比较你增加了option,header length会增加,而在分片时第一片会携带这个,但是后面的每片都不携带这个选项。
tos不会发生变化
total length会发生变化,最后一个分片除非正好与其他片的一样大(这样的比较巧合)
标识符(Identification)不会发生变化,只有下一个数据报才会发生变化,一变化就不是同一数据包的了
标识(flags)会发生变化,主要是mf,让目的知道最后一片
偏移位(Fragment offse)会发生变化,知道传了多少个字节了
生存时间(time-to-live)不会发生变化,你每个片除非经过不同的路径
协议号(protocol)不会发生变化,变化就乱了,我ip为谁传输来着
校验和(checksum)会发生变化,option选项都不加了,肯定有
source ip address:不会发生变化,参考协议字段
destination·ip address:不会发生变化,参考协议字段
在看看udp的格式
| Source port | Destination port |
| Length | checksum |
2个字节的source port
2个字节的destination port
2个字节的长度,这里包括了整个udp头部与数据部分
2个字节的checksum(可选字段)
所以说udp的最小为8个字节
这篇关于话说校验和(checksum)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




