本文主要是介绍Python往事:ElementTree的单引号之谜,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近在针对某款设备的界面xml进行更新过程中,被告知回稿的字串放在了一个excel文件中,而我要上传到服务器的界面用语是用xml文件封装的。再经过详细求证了翻译组提供excel文件的原因后,我决定用python来完成界面用语xml的更新,但是在使用ElementTree库的时候,却发现这个库有点小瑕疵。就是会将xml文件的表头<xml/>这段中的双引号换成了单引号,虽然单双引号在解析xml上没有影响。但是如果上提交代码时有强校验的门禁处理等规则的话,就需要额外解释了。为此针对这个问题,查看了下源码并分享一种修改方案。
我遇到的情况如下图所示,原本要替换message的信息,结果执行完替换脚本后,发现xml声明表头也被替换了。这个变更在比较软件中会显得很明显。

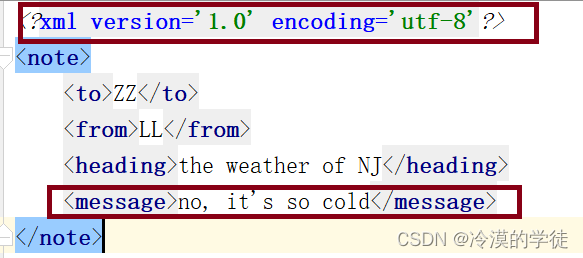
发生这种事情的原因在于EelementTree#write()中将表头的格式默认写成了单引号。如下源码展示了write()的实现,可以发现在_get_wirte()的with循环体中直白的执行了一句写入操作:
<?xml version='1.0' encoding='%s'?>
def write(self, file_or_filename,encoding=None,xml_declaration=None,default_namespace=None,method=None, *,short_empty_elements=True):"""Write element tree to a file as XML.Arguments:*file_or_filename* -- file name or a file object opened for writing*encoding* -- the output encoding (default: US-ASCII)*xml_declaration* -- bool indicating if an XML declaration should beadded to the output. If None, an XML declarationis added if encoding IS NOT either of:US-ASCII, UTF-8, or Unicode*default_namespace* -- sets the default XML namespace (for "xmlns")*method* -- either "xml" (default), "html, "text", or "c14n"*short_empty_elements* -- controls the formatting of elementsthat contain no content. If True (default)they are emitted as a single self-closedtag, otherwise they are emitted as a pairof start/end tags"""if not method:method = "xml"elif method not in _serialize:raise ValueError("unknown method %r" % method)if not encoding:if method == "c14n":encoding = "utf-8"else:encoding = "us-ascii"enc_lower = encoding.lower()with _get_writer(file_or_filename, enc_lower) as write:if method == "xml" and (xml_declaration or(xml_declaration is None andenc_lower not in ("utf-8", "us-ascii", "unicode"))):declared_encoding = encodingif enc_lower == "unicode":# Retrieve the default encoding for the xml declarationimport localedeclared_encoding = locale.getpreferredencoding()write("<?xml version='1.0' encoding='%s'?>\n" % (declared_encoding,))if method == "text":_serialize_text(write, self._root)else:qnames, namespaces = _namespaces(self._root, default_namespace)serialize = _serialize[method]serialize(write, self._root, qnames, namespaces,short_empty_elements=short_empty_elements)
可能这是ElementTree在设计初为了方便在双引号中引用字串才将version和encoding改为用单引号展示。因为write()中没有复杂的间接依赖,可以直接将该方法复制到自己的工程里。为此,针对该处的修改就是重写ElementTree#write()。重新方案如下,先将源代码中的<?xml version='1.0' encoding='%s'?> 替换成 <?xml version=\"1.0\" encoding=\"%s\"?>。
同时针对提示引用缺失的方法,增加ElementTree前缀来指明调用路径。这样就可以保证整个write()也可以在自己的工程中被执行。修改后的代码如下:
def fix_write(self, file_or_filename,encoding=None,xml_declaration=None,default_namespace=None,method=None, *,short_empty_elements=True):if not method:method = "xml"elif method not in ElementTree._serialize:raise ValueError("unknown method %r" % method)if not encoding:if method == "c14n":encoding = "utf-8"else:encoding = "us-ascii"enc_lower = encoding.lower()with ElementTree._get_writer(file_or_filename, enc_lower) as write:if method == "xml" and (xml_declaration or(xml_declaration is None andenc_lower not in ("utf-8", "us-ascii", "unicode"))):declared_encoding = encodingif enc_lower == "unicode":# Retrieve the default encoding for the xml declarationimport localedeclared_encoding = locale.getpreferredencoding()write("<?xml version=\"1.0\" encoding=\"%s\"?>\n" % (declared_encoding,))if method == "text":ElementTree._serialize_text(write, self._root)else:qnames, namespaces = ElementTree._namespaces(self._root, default_namespace)serialize = ElementTree._serialize[method]serialize(write, self._root, qnames, namespaces,short_empty_elements=short_empty_elements)
修改后,将原来调用ElementTree#write()的地方改成使用fix_write即可,同时不要忘了,将当前工程的elementTree对象作为第一入参穿进去。修改后的运行结果就会发现没有额外的格式变更了。
def update_fix():tree = ET.parse('element_test.xml')root = tree.getroot()messages = root.findall('message')messages[0].text = "no, it's so cold,let's take a shower"fix_write(tree, 'element_test_update_fix.xml', encoding="utf-8", xml_declaration=True)
这篇关于Python往事:ElementTree的单引号之谜的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




