本文主要是介绍谷歌排名影响因素最新研究(SEM RUSH版),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
谷歌排名影响因素,关于这块的研究在国外有很多,一全老师(www.yiquanseo.com)以前也专门翻译整合过两篇,分别是Backlinko的《谷歌排名影响因素权威报告(研究了数百万谷歌网站得出的结论)》以及MOZ+ahrefs的《专业必读:Moz和ahrefs对谷歌排名影响因素的详细研究》。但这些显然还不够,所以,今天一全老师再来给大家解读一下SEO界大名鼎鼎的Sem Rush关于谷歌排名影响因素的权威研究。
本文介绍的Sem Rush研究报告是2017年发布的,最后一次更新时间是2017年11月份,可以说是,当下权威研究报告中最新的一份了。
研究使用当下最先进的人工智能手段(关于研究结论、研究方法等详细内容可以看英文原文:https://www.semrush.com/blog/semrush-ranking-factors-study-2017-methodology-demystified/),得到的结论也是与传统研究因素有所差距,总体来说,还是很有参考价值的。
17项最重要的谷歌排名影响因素
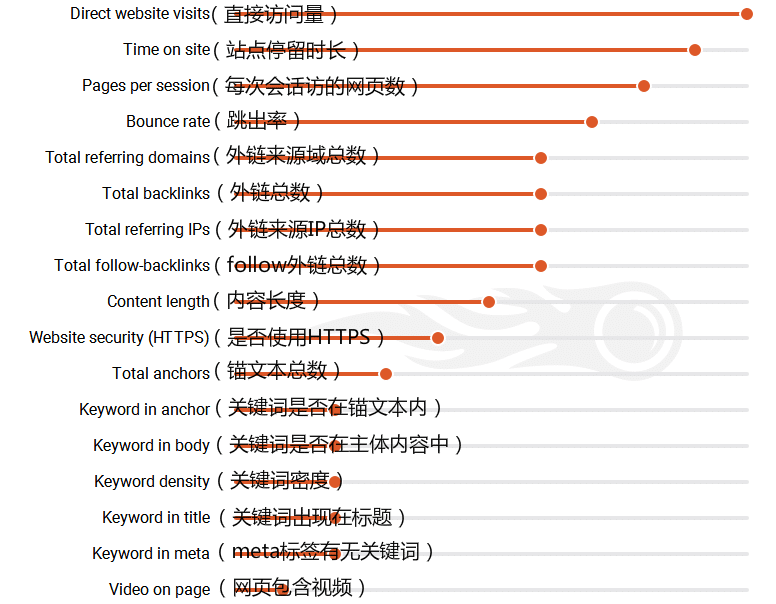
从上面报告可以看出,影响谷歌排名最重要的因素是Direct website visits(就是直接从浏览器输入网址访问网页的用户量,收藏了你网页,然后点击浏览器收藏直接到网页的用户,也会被计算进去),也就是说直接通过浏览器访问你网页的人越多,你网站在谷歌获得的排名就越好。
这个逻辑也比较好理解,如果很多用户都是直接访问你网站,连搜索都省了,那说明你的网站质量足够高,客户相信你的网站能解决他想了解的所有问题,根本无需搜索其他类似网站,这样当其他用户搜索类似话题的时候,谷歌自然会考虑将你的排名放的更靠前一点。(可能很多同学会问,谷歌怎么会知道有多少人直接访问我的网站,这个其实很容易理解,非常多的网站会添加谷歌分析,另外呢,世界上50%以上的客户都是用谷歌浏览器,所以真的很好统计。)
关于这一点,一全老师的建议是,踏踏实实把网页内容做好,然后尽量的让用户能收藏你的网站,增加网站直接访问量。
接下来Time on site(用户在网站的停留时间)、Pages per session(每个用户查看了几个页面)、Bounce rate(跳出率),属于第二梯队的重要因素,很明显,这些都属于谷歌用来评判页面质量的用户体验数据,用用户的行为来衡量网站是好是坏显然比单纯的判断文字数量、是否包含关键词等靠谱的多。
然后第三梯队是外链数据:Total referring domains(外链来源域数量)、Total backlinks(外链总数)、Total referring IPs(外链来源IP总数)、Total follow-backlinks(dofollow外链总数)再加上靠后一些的Total anchors(锚文本总数)及Keyword in anchor(关键词在锚文本中出现)。可以看出,sem rush研究结果中外链数据对谷歌排名的影响跟其他机构的研究报告基本一致。
至于第四梯队:Content length(内容长度)、Website security (HTTPS)(网站安全,是否使用https)、Keyword in body(关键词出现在主体内容中)、Keyword density(关键词密度)、Keyword in title(关键词出现在标题中)、Keyword in meta(关键词出现在meta标签中)、Video on page(网页上是否有视频)都属于页内SEO的因素,综合其他几份报告,我们可以发现现在页内SEO已经可以划归边缘因素了。(这里插一句,边缘因素是对老外来说,对我们来说并不成立,后面会讲为什么)
这样,如果sem rush的研究结果是非常准确的,我相信聪明的同学已经能够看出内容和外链到底谁更重要了,真正高质量的网站,符合用户体验的内容,真正能解决用户搜索目的,这些才是能让你网站排名能超过所有竞争对手的根本因素,第二部分才是外链,第三部分是常规的页内SEO。
但是必须说一句,这项研究采样数据在国外属于正常搜索量和正常SEO难度,但是对于大部分做外贸的同学来说,这些却属于高搜索量和超高难度,因为大部分同学做的产品,主要竞争对手来自中国或者其他发展中国家,这些竞争对手通常网站都做的很有问题,更别说SEO了,所以这些词如果让美国人来看,完全属于难度特别低的词,在他们的样本里,这样的内容是极少的,所以这样的研究结果对国外SEOer价值很大,但是对于我们来说,如果完全按这个理解,会有偏差的。
为什么?因为按一全老师的实践经验来看,现在很多低搜索量和低难度的词,谷歌现在的人工智能依旧没有吃透,依靠的还是原先的TDK+内容关键词的判断方式,简单来说,如果你的标题和内容中包含了关键词,要比标题和内容中关键词一次没出现的网页排名好太多。
简而言之一句话,在低搜索量、低竞争领域(也可以说是谷歌人工智能的边缘领域)页内SEO依旧是很重要的因素,然后外链,尤其是锚文本外链,则会在很大程度上决定,页内SEO做的差不多的网页谁的排名更好一点,最后则是用户体验数据,决定后续最终排名的稳定性。
OK,影响因素完了,还有Sem Rush的一些数据结论一并分享给大家:

以上结论的翻译:
- 排名前三的网页文字内容比排名第20的网页多45%。
- 竞争高搜索量关键词的网站65%都使用了HTTPS。
- 高搜索量领域,谷歌排名第二的网页在外链来源域数量上,比排名第十的网页多1W个。
- 排名谷歌前三的网站跳出率一般控制在49%以内。
- 高指数词的竞争网站,页面主体内容不包含关键词概率为18%。
- 当用户通过谷歌搜索进入网站,平均会访问3-3.5个页面。
- 排名第二的网页外链来源域比排名第一的网页多20%(品牌关键词拉低了第一名的数据?还是样本排除了品牌关键词?)(不是很确定branded keywords drop在这里的准确意思)。
- 排名谷歌第一的网页外链总数是排在第二位的2倍(峰值数据)。
- 3%的外链在锚文本中包含关键词。
OK,结论就是这些,至于从结论中能得到那些有用的东西,这就需要大家好好思考了。
这篇关于谷歌排名影响因素最新研究(SEM RUSH版)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






