本文主要是介绍mysql db_owner_mysql,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
sql是Structured Query Language(结构化查询语言)的缩写。sql是专为数据库而建立的操作命令集,是一种功能齐全的数据库语言。
sql规范
在数据库中,sql语句不区分大小写(建议用大写)。但字符串常量区分大小写。建议命令大写,表名库名小写
sql语句可单行或多行书写,以;结尾。关键词不能跨多行或简写
用空格和缩进来提高语句的可读性。字句通常位于独立行,便于编辑,提高可读性
注释:单行注释:--
多行注释:/*.....*/
DDL,DML和DCL
-- --SQL中 DML、DDL、DCL区别 .-- --DML(data manipulation language):--它们是SELECT、UPDATE、INSERT、DELETE,就象它的名字一样,这4条命令是用来对数据库里的--数据进行操作的语言--
-- --DDL(data definition language):--DDL比DML要多,主要的命令有CREATE、ALTER、DROP等,DDL主要是用在定义或改变表(TABLE)--的结构,数据类型,表之间的链接和约束等初始化工作上,他们大多在建立表时使用--
-- --DCL(Data Control Language):--是数据库控制功能。是用来设置或更改数据库用户或角色权限的语句,包括(grant,deny,revoke等)--语句。在默认状态下,只有sysadmin,dbcreator,db_owner或db_securityadmin等人员才有权-- 力执行DCL
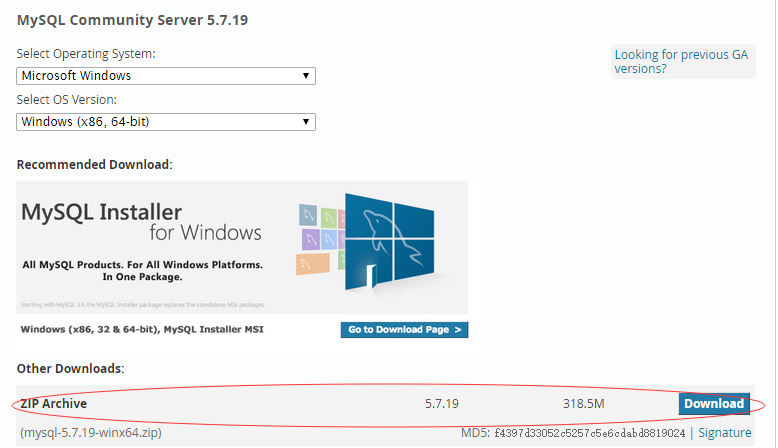
下载
https://dev.mysql.com/downloads/mysql/
安装
解压到任意目录
初始化服务端

启动服务端

客户端连接

密码默认为空
查看内置的文件夹:show databases;
创建目录:create database db1;
设置环境变量
【右键计算机】--》【属性】--》【高级系统设置】--》【高级】--》【环境变量】--》【在第二个内容框中找到 变量名为Path 的一行,双击】--> 【将MySQL的bin目录路径追加到变值值中,用 ; 分割】
window服务
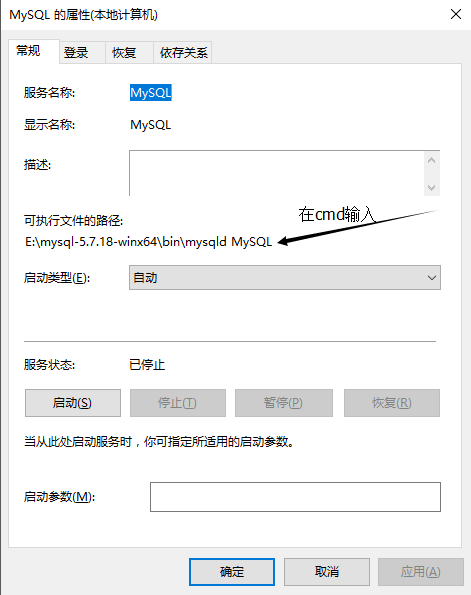
安装mysql服务

出现这个情况用管理员身份运行cmd就能解决
cmd路径:C:\Windows\System32,右键管理员身份运行

服务安装成功
如果还不行就结束mysql进程
移除mysql服务

启动mysql服务

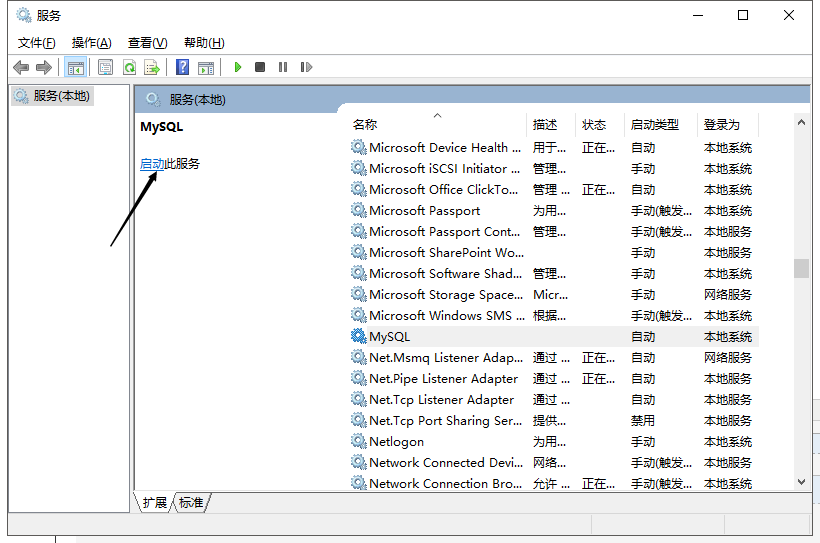
一样的效果
或者
停止mysql服务

文件夹【数据库】
文件【表】
数据行【行】
数据行
数据行
use 文件夹; 进入这个文件夹
show tables; 查看这个文件夹下的文件
-- 1.创建数据库(在磁盘上创建一个对应的文件夹)
create database 数据库名 default charset utf8;-- 2.查看数据库
show databases;查看所有数据库
show create database 数据库名; 查看数据库的创建方式-- 3.修改数据库
alter database 数据库名 charset utf8;-- 4.删除数据库
drop database 数据库名;-- 5.使用数据库
切换数据库 use 数据库名;--注意:进入到某个数据库后没办法再退回之前状态,但可以通过use进行切换
查看当前使用的数据库 select database();
创建表
create table 表名(id int,name char(10)) engine=innodb default charset=utf8
#innodb引擎, 支持事务,原子性操作,推荐写上
create table t1(
列名 类型 null,
列名 类型 not null,
列名 类型 not null auto_increment primary key,
id int,
name char(10)
)engine=innodb default charset=utf8;
null:可以为空
not null:不可以为空
auto_increment表示:自增 一个表里面只有一个自增列
primary key:不能约束(不能重复且不能为空) 加速查找 一个表里面只有一个主键
查看表信息
desc 表名; 查看表结构
show colums from 表名; 查看表结构
show tables; 查看当前数据库中的所有表
show create table 表名 \G; 查看当前数据库表建表语句,\G能竖着看
修改表结构
增加列(字段)
alter table 表名 add 列名 类型[完整性约束条件]
修改列类型
alter table 表名 modify 列名 类型[完整性约束条件]
修改列名
alter table 表名 change 列名 新列名 类型[完整性约束条件]
删除列
alter table 表名 drop 列名
修改表名
rename table 表名 to 新表名;
修改该表所用的字符集
alter table 表名 character set utf8
修改自增的值
alter table 表名 auto_increment=10
清空表
delete from 表名 下次id从原来的自增
truncate table 表名 速度快,id从1开始
删除表
drop table 表名
表记录的增删改查
增加表记录
insert into 表名()values()
插入数据,查看数据
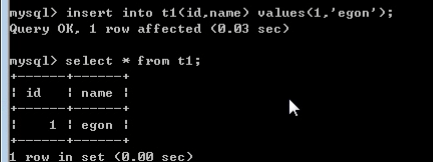
修改表记录
update tab_name set field1=value1,field2=value2,......[where 语句]/*UPDATE语法可以用新值更新原有表行中的各列。
SET子句指示要修改哪些列和要给予哪些值。
WHERE子句指定应更新哪些行。如没有WHERE子句,则更新所有的行。*/update employee_new set birthday="1989-10-24" WHERE id=1;---将yuan的薪水在原有基础上增加1000元。
update employee_new set salary=salary+4000 where name='yuan';
删除表记录
delete fromtab_name [where ....]/*如果不跟where语句则删除整张表中的数据
delete只能用来删除一行记录
delete语句只能删除表中的内容,不能删除表本身,想要删除表,用drop
TRUNCATE TABLE也可以删除表中的所有数据,词语句首先摧毁表,再新建表。此种方式删除的数据不能在
事务中恢复。*/
--删除表中名称为’alex’的记录。
deletefrom employee_new where name='alex';--删除表中所有记录。
deletefrom employee_new;-- 注意auto_increment没有被重置:alter table employee auto_increment=1;--使用truncate删除表中记录。
truncate table emp_new;
查询表记录
--查询语法:
SELECT*|field1,filed2 ... FROM tab_name
WHERE 条件
GROUP BY field
HAVING 筛选
ORDER BY field 排序
LIMIT 限制条数
简单查询
select * from 表名 查看表中所有的数据,*表示所有列
select name,age,id from 表名 查看表中指定的字段,按列名先后顺序显示
-- (1)select [distinct] *|field1,field2,...... fromtab_name-- 其中from指定从哪张表筛选,*表示查找所有列,也可以指定一个列--表明确指定要查找的列,distinct用来剔除重复行。--查询表中所有学生的信息。
select* fromExamResult;--查询表中所有学生的姓名和对应的英语成绩。
select name,JSfromExamResult;--过滤表中重复数据。
select distinct JS ,namefromExamResult;-- (2)select 也可以使用表达式,并且可以使用: 字段 as 别名或者:字段 别名--在所有学生分数上加10分特长分显示。
select name,JS+10,Django+10,OpenStack+10 fromExamResult;--统计每个学生的总分。
select name,JS+Django+OpenStack fromExamResult;--使用别名表示学生总分。
select name as 姓名,JS+Django+OpenStack as 总成绩 fromExamResult;
select name,JS+Django+OpenStack 总成绩 fromExamResult;
select name JSfrom ExamResult; -- what will happen?---->记得加逗号
使用where子句,进行过滤查询
--查询姓名为XXX的学生成绩
select* from ExamResult where name='yuan';--查询英语成绩大于90分的同学
select id,name,JSfrom ExamResult where JS>90;--查询总分大于200分的所有同学
select name,JS+Django+OpenStack as 总成绩 fromExamResult where JS+Django+OpenStack>200;--where字句中可以使用:--比较运算符:> < >= <= <> !=between80 and 100值在10到20之间in(80,90,100) 值是10或20或30
like'yuan%'
/*pattern可以是%或者_,
如果是%则表示任意多字符,此例如唐僧,唐国强
如果是_则表示一个字符唐_,只有唐僧符合。两个_则表示两个字符:__*/
--逻辑运算符
在多个条件直接可以使用逻辑运算符and or not
order by排序
指定排序的列,排序的列即可是表中的列名,也可以是select 语句后指定的别名。-- select *|field1,field2... from tab_name order by field [Asc|Desc]--Asc 升序、Desc 降序,其中asc为默认值 ORDER BY 子句应位于SELECT语句的结尾。--练习:--对JS成绩排序后输出。
select* fromExamResult order by JS;--对总分排序按从高到低的顺序输出
select name ,(ifnull(JS,0)+ifnull(Django,0)+ifnull(Database,0))
总成绩fromExamResult order by 总成绩 desc;--对姓李的学生成绩排序输出
select name ,(ifnull(JS,0)+ifnull(Django,0)+ifnull(OpenStack,0))
总成绩from ExamResult where name like 'a%'order by 总成绩 desc;
group by分组查询
--注意,按分组条件分组后每一组只会显示第一条记录--group by字句,其后可以接多个列名,也可以跟having子句,对group by 的结果进行筛选。--按位置字段筛选
select* from order_menu group by 5;--练习:对购物表按类名分组后显示每一组商品的价格总和
selectclass,SUM(price)from order_menu group by class;--练习:对购物表按类名分组后显示每一组商品价格总和超过150的商品
selectclass,SUM(price)from order_menu group by classHAVING SUM(price)>150;/*having 和 where两者都可以对查询结果进行进一步的过滤,差别有:<1>where语句只能用在分组之前的筛选,having可以用在分组之后的筛选;<2>使用where语句的地方都可以用having进行替换<3>having中可以用聚合函数,where中就不行。*/
--GROUP_CONCAT() 函数
SELECT id,GROUP_CONCAT(name),GROUP_CONCAT(JS)from ExamResult GROUP BY id;
聚合函数
--<1>统计表中所有记录--COUNT(列名):统计行的个数--统计一个班级共有多少学生?先查出所有的学生,再用count包上
select count(*) fromExamResult;--统计JS成绩大于70的学生有多少个?
select count(JS)from ExamResult where JS>70;--统计总分大于280的人数有多少?
select count(name)fromExamResult
where (ifnull(JS,0)+ifnull(Django,0)+ifnull(OpenStack,0))>280;-- 注意:count(*)统计所有行; count(字段)不统计null值.--SUM(列名):统计满足条件的行的内容和--统计一个班级JS总成绩?先查出所有的JS成绩,再用sum包上
select JS as JS总成绩fromExamResult;
select sum(JS) as JS总成绩fromExamResult;--统计一个班级各科分别的总成绩
select sum(JS) as JS总成绩,
sum(Django) as Django总成绩,
sum(OpenStack) as OpenStackfromExamResult;--统计一个班级各科的成绩总和
select sum(ifnull(JS,0)+ifnull(Django,0)+ifnull(Database,0))
as 总成绩fromExamResult;--统计一个班级JS成绩平均分
select sum(JS)/count(*) fromExamResult ;--注意:sum仅对数值起作用,否则会报错。--AVG(列名):--求一个班级JS平均分?先查出所有的JS分,然后用avg包上。
select avg(ifnull(JS,0))fromExamResult;--求一个班级总分平均分
select avg((ifnull(JS,0)+ifnull(Django,0)+ifnull(Database,0)))fromExamResult ;--Max、Min--求班级最高分和最低分(数值范围在统计中特别有用)
select Max((ifnull(JS,0)+ifnull(Django,0)+ifnull(OpenStack,0)))
最高分fromExamResult;
select Min((ifnull(JS,0)+ifnull(Django,0)+ifnull(OpenStack,0)))
最低分fromExamResult;--求购物表中单价最高的商品名称及价格---SELECT id, MAX(price) FROM order_menu;--id和最高价商品是一个商品吗?
SELECT MAX(price) FROM order_menu;--注意:null 和所有的数计算都是null,所以需要用ifnull将null转换为0!-- -----ifnull(JS,0)
limit记录条数限制
SELECT * from ExamResult limit 1;
SELECT* from ExamResult limit 2,5; --跳过前两条显示接下来的五条纪录
SELECT* from ExamResult limit 2,2;
正则表达式
SELECT * FROM employee WHERE emp_name REGEXP '^yu';
SELECT* FROM employee WHERE emp_name REGEXP 'yun$';
SELECT* FROM employee WHERE emp_name REGEXP 'm{2}';
外键约束
创建外键
---每一个班主任会对应多个学生 , 而每个学生只能对应一个班主任----主表
CREATE TABLE ClassCharger(
id TINYINT PRIMARY KEY auto_increment,
name VARCHAR (20),
age INT ,
is_marriged boolean-- show create table ClassCharger: tinyint(1)
);
INSERT INTO ClassCharger (name,age,is_marriged) VALUES ("冰冰",12,0),
("丹丹",14,0),
("歪歪",22,0),
("姗姗",20,0),
("小雨",21,0);----子表
CREATE TABLE Student(
id INT PRIMARY KEY auto_increment,
name VARCHAR (20),
charger_id TINYINT,--切记:作为外键一定要和关联主键的数据类型保持一致--[ADD CONSTRAINT charger_fk_stu(外键名称)]FOREIGN KEY (charger_id) REFERENCES ClassCharger(id)
) ENGINE=INNODB;
INSERT INTO Student(name,charger_id) VALUES ("alvin1",2),
("alvin2",4),
("alvin3",1),
("alvin4",3),
("alvin5",1),
("alvin6",3),
("alvin7",2);
DELETE FROM ClassCharger WHERE name="冰冰";
INSERT student (name,charger_id) VALUES ("yuan",1);-- 删除居然成功,可是 alvin3显示还是有班主任id=1的冰冰的;-----------增加外键和删除外键---------ALTER TABLE student ADD CONSTRAINT abc
FOREIGN KEY(charger_id)
REFERENCES classcharger(id);
ALTER TABLE student DROP FOREIGN KEY abc;
INNODB支持的ON语句
--外键约束对子表的含义: 如果在父表中找不到候选键,则不允许在子表上进行insert/update--外键约束对父表的含义: 在父表上进行update/delete以更新或删除在子表中有一条或多条对--应匹配行的候选键时,父表的行为取决于:在定义子表的外键时指定的-- on update/on delete子句-----------------innodb支持的四种方式---------------------------------------
-----cascade方式 在父表上update/delete记录时,同步update/delete掉子表的匹配记录-----外键的级联删除:如果父表中的记录被删除,则子表中对应的记录自动被删除--------FOREIGN KEY (charger_id) REFERENCES ClassCharger(id)
ON DELETE CASCADE------set null方式 在父表上update/delete记录时,将子表上匹配记录的列设为null--要注意子表的外键列不能为not null
FOREIGN KEY (charger_id) REFERENCES ClassCharger(id)
ON DELETE SET NULL------Restrict方式 :拒绝对父表进行删除更新操作(了解)------No action方式 在mysql中同Restrict,如果子表中有匹配的记录,则不允许对父表对应候选键-- 进行update/delete操作(了解)
多表查询
多表查询之连接查询
1.笛卡尔积查询
mysql> SELECT *FROM employee,department;--select employee.emp_id,employee.emp_name,employee.age,-- department.dept_name fromemployee,department;+--------+----------+------+---------+---------+-----------+
| emp_id | emp_name | age | dept_id | dept_id | dept_name |
+--------+----------+------+---------+---------+-----------+
| 1 | A | 19 | 200 | 200 | 人事部 |
| 1 | A | 19 | 200 | 201 | 技术部 |
| 1 | A | 19 | 200 | 202 | 销售部 |
| 1 | A | 19 | 200 | 203 | 财政部 |
| 2 | B | 26 | 201 | 200 | 人事部 |
| 2 | B | 26 | 201 | 201 | 技术部 |
| 2 | B | 26 | 201 | 202 | 销售部 |
| 2 | B | 26 | 201 | 203 | 财政部 |
| 3 | C | 30 | 201 | 200 | 人事部 |
| 3 | C | 30 | 201 | 201 | 技术部 |
| 3 | C | 30 | 201 | 202 | 销售部 |
| 3 | C | 30 | 201 | 203 | 财政部 |
| 4 | D | 24 | 202 | 200 | 人事部 |
| 4 | D | 24 | 202 | 201 | 技术部 |
| 4 | D | 24 | 202 | 202 | 销售部 |
| 4 | D | 24 | 202 | 203 | 财政部 |
| 5 | E | 20 | 200 | 200 | 人事部 |
| 5 | E | 20 | 200 | 201 | 技术部 |
| 5 | E | 20 | 200 | 202 | 销售部 |
| 5 | E | 20 | 200 | 203 | 财政部 |
| 6 | F | 38 | 204 | 200 | 人事部 |
| 6 | F | 38 | 204 | 201 | 技术部 |
| 6 | F | 38 | 204 | 202 | 销售部 |
| 6 | F | 38 | 204 | 203 | 财政部 |
+--------+----------+------+---------+---------+-----------+
内连接
--查询两张表中都有的关联数据,相当于利用条件从笛卡尔积结果中筛选出了正确的结果。
select* from employee,department where employee.dept_id =department.dept_id;--select * from employee inner join department on employee.dept_id =department.dept_id;+--------+----------+------+---------+---------+-----------+
| emp_id | emp_name | age | dept_id | dept_id | dept_name |
+--------+----------+------+---------+---------+-----------+
| 1 | A | 19 | 200 | 200 | 人事部 |
| 2 | B | 26 | 201 | 201 | 技术部 |
| 3 | C | 30 | 201 | 201 | 技术部 |
| 4 | D | 24 | 202 | 202 | 销售部 |
| 5 | E | 20 | 200 | 200 | 人事部 |
+--------+----------+------+---------+---------+-----------+
外连接
--(1)左外连接:在内连接的基础上增加左边有右边没有的结果
select* from employee left join department on employee.dept_id =department.dept_id;+--------+----------+------+---------+---------+-----------+
| emp_id | emp_name | age | dept_id | dept_id | dept_name |
+--------+----------+------+---------+---------+-----------+
| 1 | A | 19 | 200 | 200 | 人事部 |
| 5 | E | 20 | 200 | 200 | 人事部 |
| 2 | B | 26 | 201 | 201 | 技术部 |
| 3 | C | 30 | 201 | 201 | 技术部 |
| 4 | D | 24 | 202 | 202 | 销售部 |
| 6 | F | 38 | 204 | NULL | NULL |
+--------+----------+------+---------+---------+-----------+
--(2)右外连接:在内连接的基础上增加右边有左边没有的结果
select* from employee RIGHT JOIN department on employee.dept_id =department.dept_id;+--------+----------+------+---------+---------+-----------+
| emp_id | emp_name | age | dept_id | dept_id | dept_name |
+--------+----------+------+---------+---------+-----------+
| 1 | A | 19 | 200 | 200 | 人事部 |
| 2 | B | 26 | 201 | 201 | 技术部 |
| 3 | C | 30 | 201 | 201 | 技术部 |
| 4 | D | 24 | 202 | 202 | 销售部 |
| 5 | E | 20 | 200 | 200 | 人事部 |
| NULL | NULL | NULL | NULL | 203 | 财政部 |
+--------+----------+------+---------+---------+-----------+
--(3)全外连接:在内连接的基础上增加左边有右边没有的和右边有左边没有的结果--mysql不支持全外连接 full JOIN--mysql可以使用此种方式间接实现全外连接
select* from employee RIGHT JOIN department on employee.dept_id =department.dept_id
UNION
select* from employee LEFT JOIN department on employee.dept_id =department.dept_id;+--------+----------+------+---------+---------+-----------+
| emp_id | emp_name | age | dept_id | dept_id | dept_name |
+--------+----------+------+---------+---------+-----------+
| 1 | A | 19 | 200 | 200 | 人事部 |
| 2 | B | 26 | 201 | 201 | 技术部 |
| 3 | C | 30 | 201 | 201 | 技术部 |
| 4 | D | 24 | 202 | 202 | 销售部 |
| 5 | E | 20 | 200 | 200 | 人事部 |
| NULL | NULL | NULL | NULL | 203 | 财政部 |
| 6 | F | 38 | 204 | NULL | NULL |
+--------+----------+------+---------+---------+-----------+
-- 注意 union与union all的区别:union会去掉相同的纪录
多表查询之复合条件连接查询
--查询员工年龄大于等于25岁的部门
SELECT DISTINCT department.dept_name
FROM employee,department
WHERE employee.dept_id=department.dept_id
AND age>25;--以内连接的方式查询employee和department表,并且以age字段的升序方式显示
select employee.emp_id,employee.emp_name,employee.age,department.dept_namefromemployee,department
where employee.dept_id=department.dept_id
order by age asc;
多表查询之子查询
--子查询是将一个查询语句嵌套在另一个查询语句中。--内层查询语句的查询结果,可以为外层查询语句提供查询条件。--子查询中可以包含:IN、NOT IN、ANY、ALL、EXISTS 和 NOT EXISTS等关键字-- 还可以包含比较运算符:= 、 !=、> 、
select* fromemployee
where dept_id IN
(select dept_idfromdepartment);+--------+----------+------+---------+
| emp_id | emp_name | age | dept_id |
+--------+----------+------+---------+
| 1 | A | 19 | 200 |
| 2 | B | 26 | 201 |
| 3 | C | 30 | 201 |
| 4 | D | 24 | 202 |
| 5 | E | 20 | 200 |
+--------+----------+------+---------+rowsin set (0.01sec)-- 2. 带比较运算符的子查询-- =、!=、>、>=、
--查询员工年龄大于等于25岁的部门
select dept_id,dept_namefromdepartment
where dept_id IN
(select DISTINCT dept_idfrom employee where age>=25);-- 3. 带EXISTS关键字的子查询--EXISTS关字键字表示存在。在使用EXISTS关键字时,内层查询语句不返回查询的记录。--而是返回一个真假值。Ture或False--当返回Ture时,外层查询语句将进行查询;当返回值为False时,外层查询语句不进行查询
select* fromemployee
WHERE EXISTS
(SELECT dept_namefrom department where dept_id=203);--department表中存在dept_id=203,Ture
select* fromemployee
WHERE EXISTS
(SELECT dept_namefrom department where dept_id=205);-- Empty set (0.00sec)
ps: create table t1(select* from t2);
约束条件:
主键一张表只能有一个
一个主键可以由多个列组成
primary key(非空且唯一):能够唯一区分出当前记录的字段称为主键,加速查找
unique 唯一
not null 非空
auto_increment:自增,和主键搭配着才能用,主键必须是数字类型
数据类型:
数字
tinyint unsigned加上这个就是无符号
int
bigint
float
double
decimal 精准 decimal(10,5)总位数,小数点后位数
字符串
char 速度快
varchar 节省空间
最大字符255,大于255用test
ps:创建数据表定长列往前放
上传文件:
文件存硬盘
db存路径
时间类型
datetime
enum 枚举
set 集合
数据库存储引擎
什么是存储引擎
数据库的表有不同的类型,表的类型不同,会对应不同的存取机制,表类型又称为存储引擎
存储引擎说白了就是如何存储数据,如何为存储的数据建立索引和如何更新、查询数据等技术的实现方法。因为在关系型数据库中的存储是以表的形式存储的,所以存储引擎也可以称为表类型(即存储和操作此表的类型)
mysql数据库提供了多种存储引擎,用户可以根据不同的需求为数据表选择不同的存储引擎,用户也可以根据自己的需要编写自己的存储引擎
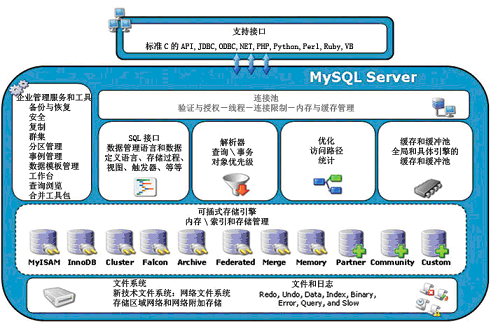
mysql支持的存储引擎
MariaDB [(none)]> show engines\G #查看所有支持的存储引擎
MariaDB [(none)]> show variables like 'storage_engine%'; #查看正在使用的存储引擎
mysql常用的数据引擎
mylsam存储引擎
由于该引擎不支持事务,也不支持外键,所以访问速度较快,因此当对事物完整性没有要求并以访问为主的应用适合试用该存储引擎。
innodb存储引擎(主要使用)
由于该存储引擎在事务上具有优势,即支持具有提交、回滚及崩溃恢复能力等事务的特性,所以比mylsam存储引擎占用更多的磁盘空间,因此当需要频繁的更新、删除等操作,同时还对事务的完整性要求较高,需要实现并发控制,建议选择。
memory
memory存储引擎存储数据的位置是内存,因此访问速度最快,但是安全上没有保障。适合于需要快速的访问或临时表。
blackhole
黑洞存储引擎,可以应用与主备复制中的分发主库
使用存储引擎
方法1:建表时指定
MariaDB [db1]> create table innodb_t1(id int,name char)engine=innodb;
MariaDB [db1]> create table innodb_t2(id int)engine=innodb;
MariaDB [db1]>show create table innodb_t1;
MariaDB [db1]> show create table innodb_t2;
方法2:在配置文件时指定默认的存储引擎
/etc/my.cnf
[mysqld]
default-storage-engine=INNODB
innodb_file_per_table=1
查看
[root@egon db1]#cd /var/lib/mysql/db1/
[root@egon db1]#ls
db.opt innodb_t1.frm innodb_t1.ibd innodb_t2.frm innodb_t2.ibd
查看用户
创建用户:
create user 'alex'@'192.168.1.1' identified by '123123'
create user 'alex'@'192.168.1.%' identified by '123123' %表示任意
create user 'alex'@'%' identified by '123123'
授权管理:
show grants for '用户'@'IP地址' 查看地址
grant select,insert,update on db1.t1 to 'alex'@'%';
grant all privileges on db1.* to 'alex'@'%'; 除了授权功能其他功能都有,db1数据库下的所有表
revoke all privileges from db1.* to 'alex'@'%'; 取消授权

再开个终端进入
这篇关于mysql db_owner_mysql的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




