本文主要是介绍人山人海(python实现),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
人山人海(通信网理论基础)
小朱和小白同学来到大学旁的商圈凤巢玩耍。商圈中有n个娱乐场馆和m条路连接这些场馆。由于国庆期间出门玩耍的人数增加,每条路上都积攒了不同数量的游客。小朱同学不想经过游客太多的路径,所以求助成都某大学精通图算法的小白同学。问,任意两个场馆之间最大游客数量最小的那条路的最大游客数量。
如图:
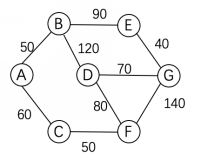
a-g两点间的路径,只有a-c-f-d-g这条路的最大游客数量是最小的,为80。
b-d两点间的路径,只有b-a-c-f-d这条路的最大游客数量是最小的,为80。
输入:第一行m<10000为图的边数,第二行为图的点数。之后m<100行,每行有三个正整数I,j,k表示节点I,j相连,游客人数k<10000。之后一行一个正整数t<n(n-1)表示询问次数。之后t行,每一行两个正整数a,b(a,b<n),表示询问a,b之间最大游客数量最小的那条路的最大游客数量。
输出:
对于每次询问输出一行,该行为一个正整数,表示最大游客数量。
样例:
输入:
5
4
1 2 10
1 3 20
2 3 15
2 4 5
3 4 30
1
04
输出:
10
题目分析:
这个题目的思路和温差问题有些相似,先将图中所有的边按权重从小到大排列,从排列好的边集合A依次取出边加入一个新的集合B,每加入一条边都要判断给定的起点终点在集合B中的边与边对应的点构成的图里是否可达,如果可达就停止加边,将集合B中最大的边权值输出。
import sys, time, mathedgeLinks = dict()
edgeLinks_dfs = dict()
stack = []
edgeWeightsAbout = dict()
edgeWeightsAbout1 = dict()
edgeWeight = dict()
Cu = []
J = []
S = []
Path = []
start = []
end = []
stack = []
T = []
Q = []
ju = 0
start_1 = time.time()def DFS(start, end):global stack, T, edgeLinks_dfs, p, justack.append(start)if start == end:p = 1ju = 1# print("找到路径:%s" %(stack))stack.clear()else:if len(edgeLinks_dfs) != 0:if start in edgeLinks_dfs:for nextPoint in edgeLinks_dfs[start]: # start不为全局变量 在递归后就变为了nextPointif nextPoint not in stack:DFS(nextPoint, end)if p == 1:stack.clear()returnelse:p = -1stack.pop()global p
p = 0
f = open('data5.txt', 'r')
P = int(f.readline())
V = int(f.readline())
if V > 1 and V <= 10000 and P <= 10000:for item2 in range(P):a, b, c = map(int, f.readline().split())wi = int(c)if str(a) not in edgeLinks: edgeLinks[str(a)] = set()if str(b) not in edgeLinks: edgeLinks[str(b)] = set()edgeLinks[str(a)].add(str(b))edgeLinks[str(b)].add(str(a))# 进行权重分类 权重一样的放到一个集合里面if wi not in edgeWeightsAbout.keys():edgeWeightsAbout[wi] = []if {str(a), str(b)} not in edgeWeightsAbout[wi]:edgeWeightsAbout[wi].append({str(a), str(b)})if str(a) not in edgeWeight:edgeWeight[str(a)] = dict()if str(b) not in edgeWeight:edgeWeight[str(b)] = dict()edgeWeight[str(a)].update({str(b): c})edgeWeight[str(b)].update({str(a): c})NP = int(f.readline())for item3 in range(NP):m, n = map(int, f.readline().split())start.append(str(m))end.append(str(n))S = sorted(edgeWeightsAbout.keys(), reverse=False)for item6 in range(len(S)):edgeWeightsAbout1.update({S[item6]: edgeWeightsAbout[S[item6]]})for item12 in range(NP):T.clear()Cu.clear()J.clear()edgeLinks_dfs.clear()stack.clear()ju = 0for item7 in range(len(S)):if(ju==1):breakfor item8 in range(len(edgeWeightsAbout1[S[item7]])):if(ju==1):breakfor item11 in edgeWeightsAbout1[S[item7]][item8]:J.append(item11)if J[0] not in edgeLinks_dfs: edgeLinks_dfs[J[0]] = set()if J[1] not in edgeLinks_dfs: edgeLinks_dfs[J[1]] = set()edgeLinks_dfs[J[0]].add(J[1])edgeLinks_dfs[J[1]].add(J[0])Cu.append(str(J[0]))Cu.append(str(J[1]))J.clear()if (len(edgeLinks_dfs) == 0):breakelse:if (len(edgeLinks_dfs) == 0):breakelse:if start[item12] in Cu and end[item12] in Cu:DFS(start[item12], end[item12])if (p == 1):T.append(edgeWeight[Cu[len(Cu) - 2]][Cu[len(Cu) - 1]])if (ju == 1):print('%s->%s'%(start[item12],end[item12]),end=' ')print(T)else:print('no path')
end_1 = time.time()
print('Running time: %s Seconds' % (end_1 - start_1))
该代码采取读取文件形式,只需将文件路径放入即可。
输出:为起点->终点 最大游客数量
输出为“no path”意味着没有该路径
正常输出如下:
1->10 [10]
1->13 [10]
2->25 [13]
45->70 [11]
8->89 [8]
Running time: 0.009997129440307617 Seconds
这篇关于人山人海(python实现)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




