本文主要是介绍TCP/IP详解——IP协议,IP选路,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1. IP 编址
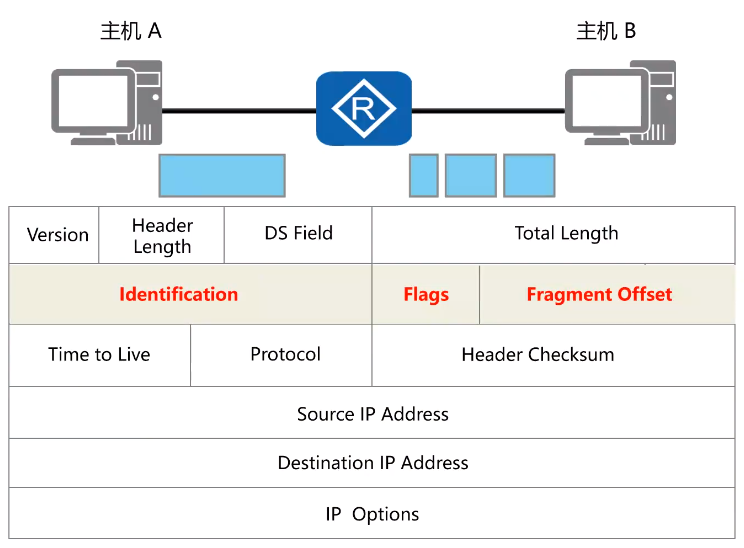
- 1.1 IP 报文头部
- 1.2 进制之间的转换
- 1.3 网络通信
- 1.4 有类 IP 编制的缺陷
- 1.5 变长子网掩码
- 1.6 网关
- 1.7 IP 包分片
- 1.7.1 IP 包分片实例
- 1.7.2 IP 分片注意事项
- 1.7.3 Wireshark 抓取 IP 包分片
- 1.7.4 OmniPeek 抓取 IP 包分片
- 1.7.5 ICMP 不可达差错(需要分片)
- 1.7.6 实例
- 1.8 生存时间/首部校验和
- 1.9 协议位
- 1.10 IP 首部的选项
- 1.11 IP 路由选择
- 1.12 特殊情况的 IP 地址
- 2. IP 选路
- 2.1 IP 选路概念
- 2.2 选路原理
- 2.3 简单路由表
- 2.4 路由查找失败
- 2.5 ICMP 重定向差错
- 2.6 重定向的条件
1. IP 编址
IP 概述
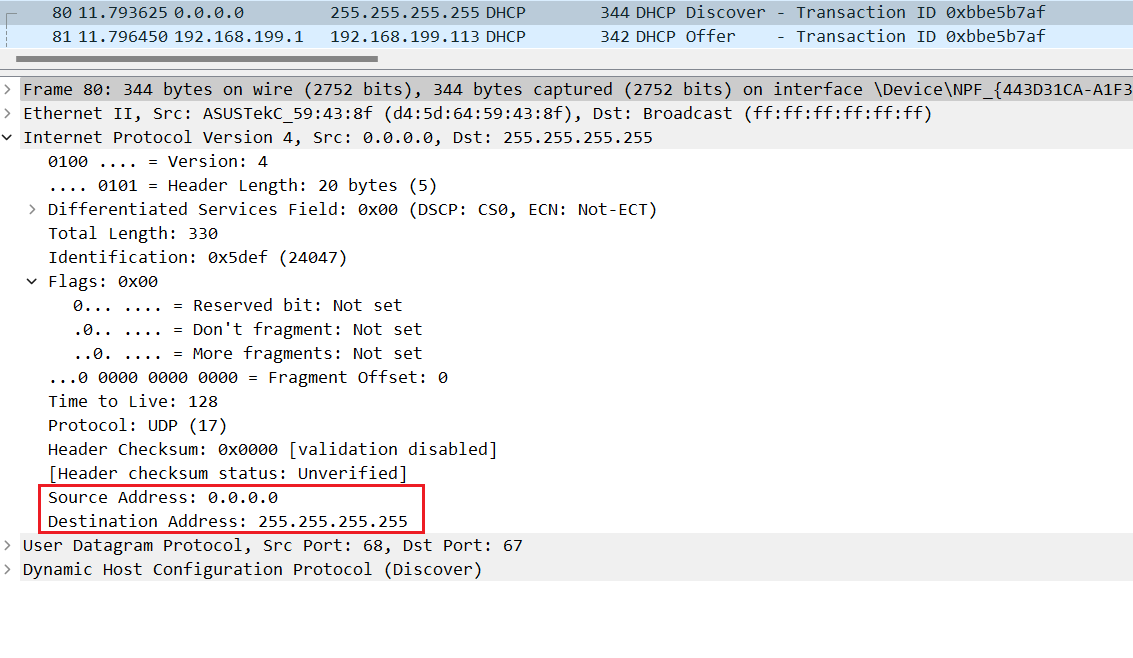
- IP是TCP/IP协议族中最为核心的协议,所有的TCP,UDP,ICMP,IGMP数据都是以IP数据报格式进行传输的。
- IP提供不可靠的,无连接的数据报传送服务。
- 不可靠(unreliable)的意思是它不能保证IP数据报能成功地到达目的地。IP 仅提供最好的传输服务。如果发生某种错误时,如某个路由器暂时用完了缓冲区,IP 有一个简单的错误处理算法:丢弃该数据报,然后发送 ICMP 消息报给信源端。任何要求的可靠性必须由上层来提供(如TCP)。
- 无连接(connectionless)这个术语的意思是IP并不维护任何关于后续数据报的状态信息。每个数据报的处理是相互独立的。IP数据报可以不按发送顺序接收。如果一信源向相同的信宿发送两个连续的数据报(先是A,然后是B),每个数据报都是独立地进行路由选择,可能选择不同的路线,因此B可能在A到达之前先到达。
- 命令:
ifconfig和netstat。
1.1 IP 报文头部
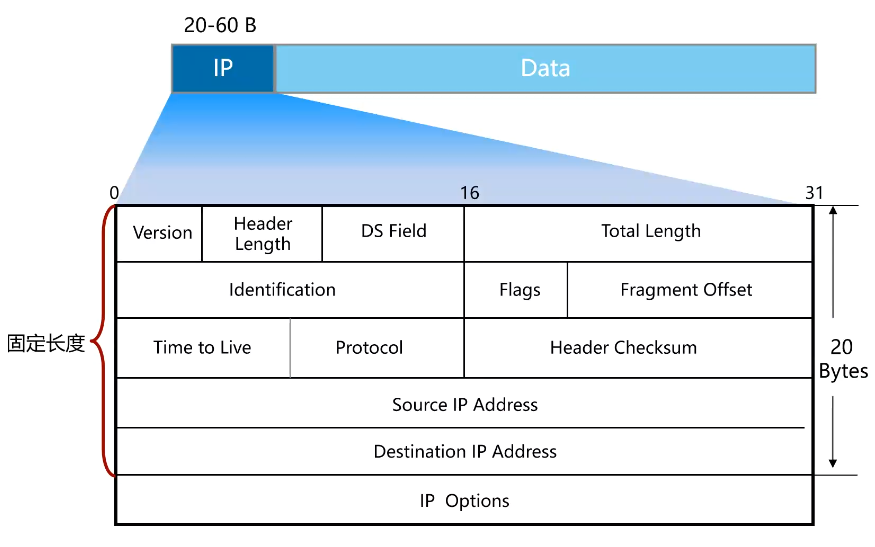
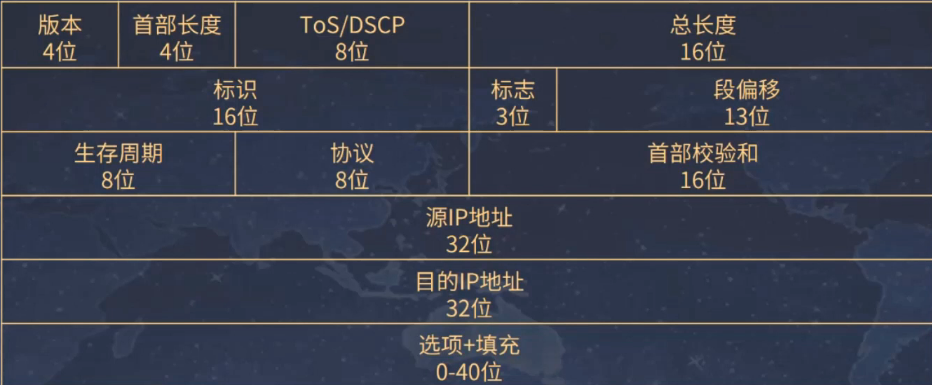

说明:
-
**版本字段(Version):**用于区分不同IP协议的版本。如IPv4、IPv6,用4bit表示(4位),IPV4头部为0100(4),IPV6头部为0110(6)。
-
**首部长度(Header Length):**因为头部长度不固定(IP首部的选项部分 Option 不固定),所以需要标识该分组的头部长度用4bit表示(4位),以4byte为单位,取值范围:5-15,即20-40byte(其他字段也是类似的计算方式,因为bit位是不够表示该字段的值)。
- 确定IP首部的结束位置:通过首部长度字段,接收方能够确定整个IP首部的结束位置,从而能够准确地找到IP数据包中的数据部分的起始位置。
-
DS Field字段:早期用来表示业务类型,现在用于支持QoS中的差别服务模型,实现网络流量优化。
- DSCP(Differentiated Services Code Point)占据了前6位,用于标识数据包的优先级和处理方式。它通过定义一系列编码值来实现不同类型数据流的区分。这些编码值可以被用来指定数据包的转发优先级、队列处理方式等,以便网络设备能够根据这些值对数据包进行适当的处理。
- ECN(Explicit Congestion Notification)占据了后2位,用于指示网络中的拥塞情况。当网络出现拥塞时,数据包的ECN位会被设置以通知接收方网络的拥塞状态,从而触发相应的拥塞控制机制。
-
Total Length总长度:长16位,描述了 IP 数据包头部和后续数据的总长度,最大可达到 65535 的一个长度,当数据包被分片的时候该字段的值也随着变化。

-
标识 Identification:16位长度,每一个IP包都有标识。便于在IP包分片后,判断是否是一个数据包。
-
**源和目的IP地址:**是分配给主机的逻辑地址,用于在网络层标识报文的发送方和接收方。根据源IP地址和目的IP地址可以判断目的端是否与发送端位于同一网段,如果二者不在同一网段,则需要采用路由机制进行跨网段转发。
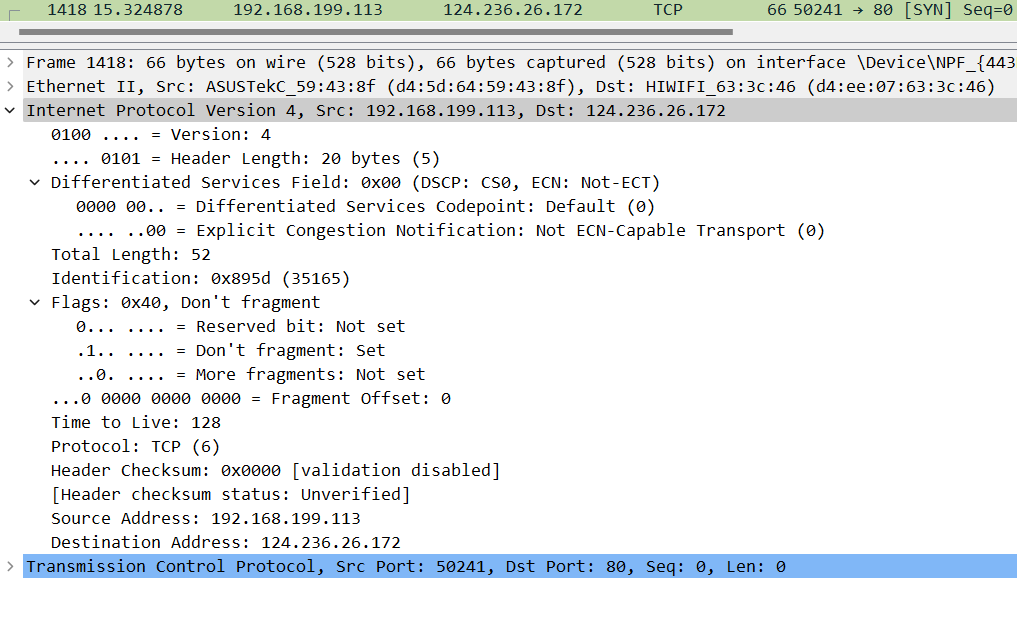
Wireshark抓包查看
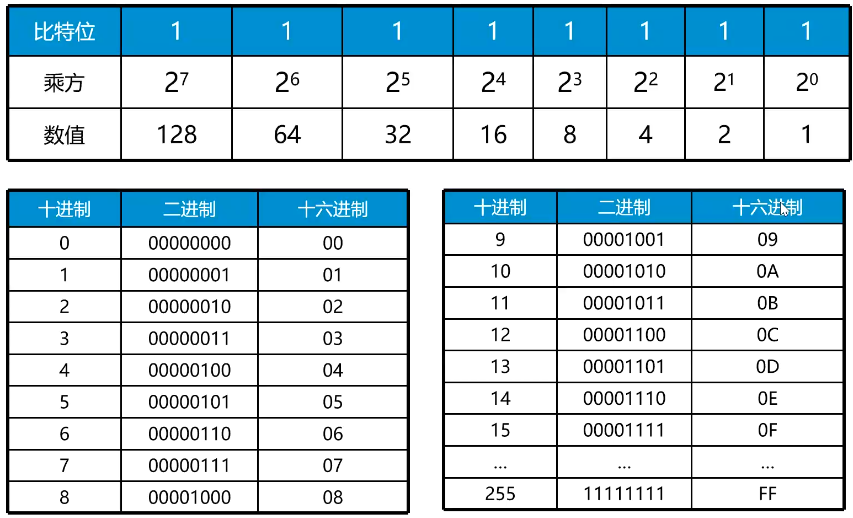
1.2 进制之间的转换

1.3 网络通信
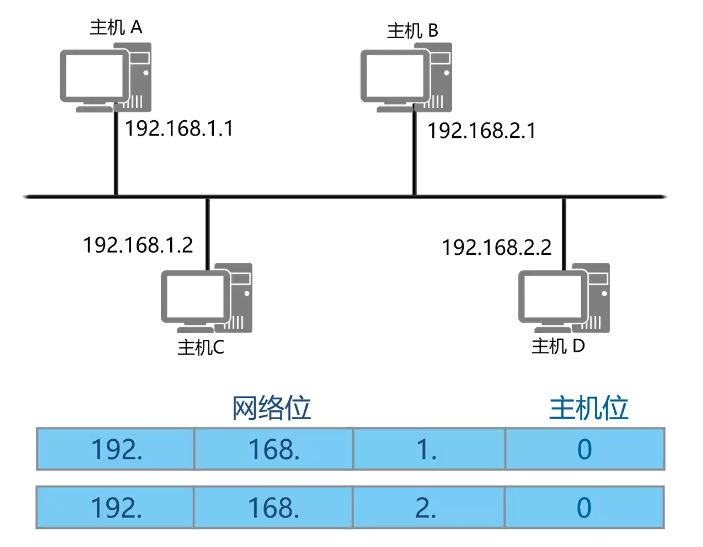
说明:源主机必须知道目的主机的ip地址才能将数据发送到目的地,源主机向其他主机发送报文之前,需要检查目的IP地址和源主机IP地址是否处于同一网段,如果是则将报文下发到底层的协议进行以太网的封装处理。如果目的地址和源主机地址不属于同一个网段,则主机需要获取下一跳路由的IP地址才能将报文下发到底层的协议处理。
1.4 有类 IP 编制的缺陷
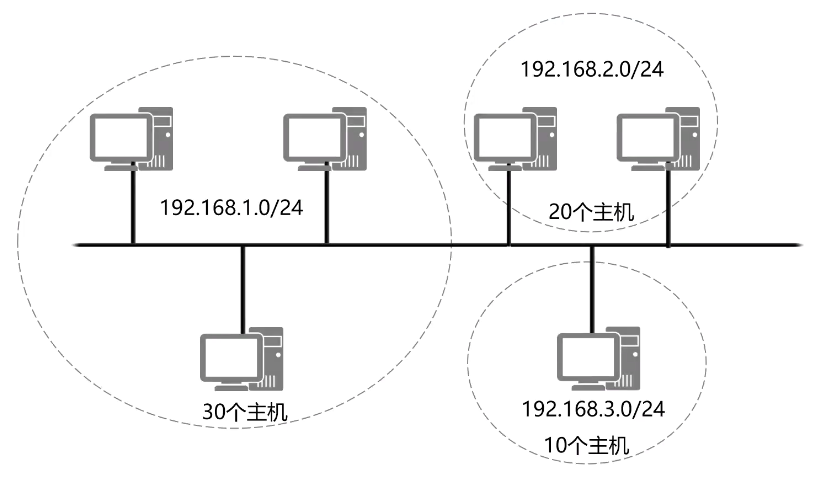
如果企业网络中希望通过规划多个网段来隔离物理网络上的主机,使用缺省子网掩码就会存在一定的局限性。网络中划分多个网段后,每个网段中的实际主机数量可能很有限,导致很多地址未被使用。
如图所示的场景下,C类地址的缺省子网掩码为24位,可以支持254台这主机,而图中只有30台主机,如果使用缺省子网掩码的编址方案,则地址使用率很低。
128 64 32 16 8 4 2 1
1 1 1 0 0 0 0 0
第一个子网
网络地址:192.168.1.0
第一个IP地址:192.168.1.1
最后一个IP地址:192.168.1.30
广播地址:192.168.1.31
第二个子网
网络地址:192.168.1.32
第一个IP地址:192.168.1.33
最后一个IP地址:192.168.1.62
广播地址:192.168.1.63
第三个子网
网络地址:192.168.1.64
第一个IP地址:192.168.1.65
最后一个IP地址:192.168.1.94
广播地址:192.168.1.95
1.5 变长子网掩码
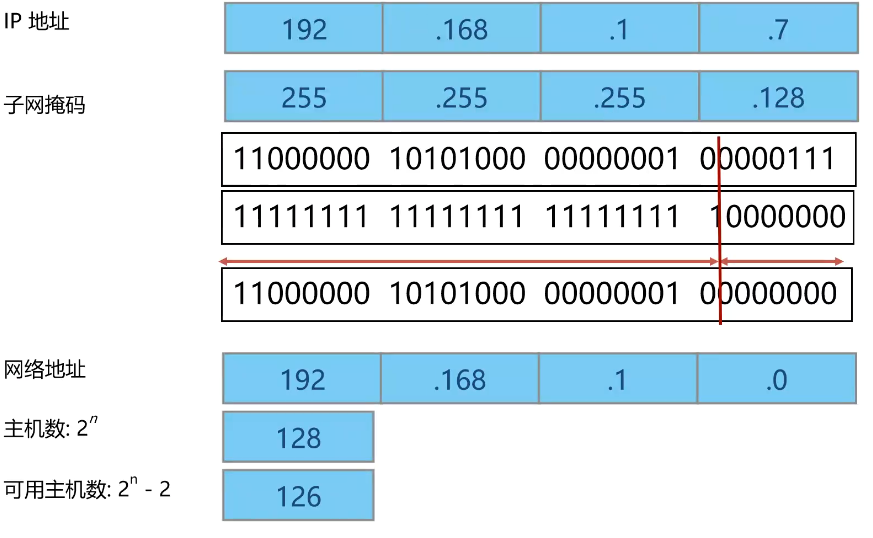
可变长子网掩码缓解了使用缺省子网掩码导致的地址浪费问题,同时也为企业网络提供了更为有效的编址方案。本例中需要使用可变长子网掩码来划分多个子网,借用一定数量的主机位作为子网位的同时,剩余的主机位必须保证有足够的IP地址供每个子网上的所有主机使用。
例如:公司有C类网段192.168.1.0/24,目前有以下几个部门:
- 销售部 59台
- 技术部 27台
- 业务部 121台
- 会计部 10台
需求是将一个C类网段合理分配给如下几个部门,保证地址合理分配
销售部地址范围:
子网掩码:255.255.255.192
子网范围:192.168.1.128~192.168.1.191
技术部地址范围:
子网掩码:255.255.255.224
子网范围:192.168.1.192~192.168.1.223
业务部地址范围:
子网掩码:255.255.255.128
子网范围:192.168.1.0~192.168.1.127
会计部地址范围:
子网掩码:255.255.255.240
子网范围:192.168.1.224~192.168.1.241
1.6 网关
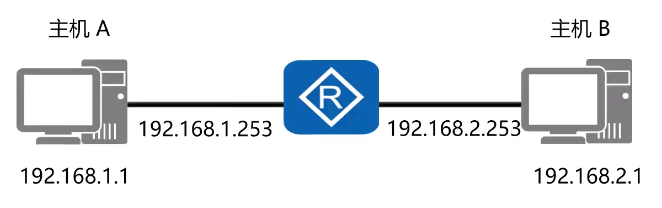
在没有路由器的情况下,两个网络之间的主机是不能进行TCP/IP通信的,即使是两个网络连接在同一台交换机,TCP/IP协议也会根据子网掩码(255.255.255.0)与主机的IP 地址作 “与” 运算的结果不同判定两个网络中的主机处在不同的网络里。
而要实现这两个网络之间的通信,则必须通过网关。如果主机A发现数据包的目的主机不在本地网络中,就把数据包转发给它自己的网关(在封装MAC地址的时候是封装的是网关的MAC地址),再由网关转发给主机B的网关。
网关由管理员设置,从主机地址中随机挑选一个作为网关地址。
1.7 IP 包分片
只有UDP的数据包才会有分片。
- IP把MTU与数据报长度进行比较。
- 如果需要则进行分片,分片可以发生在原始发送端主机,也可以发生在中间的路由器上。
- 把一份IP数据报分片以后,只有到达目的地才进行重新组装。(FRfragment)
- 重新组装由目的端的IP层来完成,其目的是使分片和重新组装过程对传输层(TCP和UDP)是透明的。
- 已经分片过的数据报有可能会再次进行分片(可能不止一次)

网络中转发的IP报文的长度可以不同,但如果报文长度超过了数据链路所支持的最大长度,则报文需要分割成若干个较小的片段才能够在链路上传输。将报文分割成多个片段的过程叫做分片。
说明:
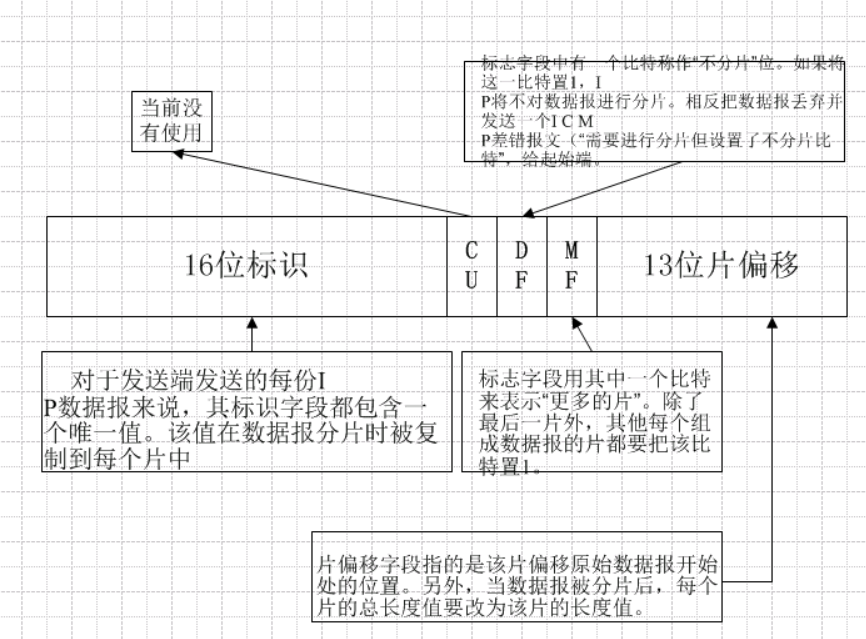
接收端根据分片报文中的标识符(Identification),标志(Flags),及片偏移(Fragment Offset)字段对分片报文进行重组。
-
Identification:标识符,用于识别属于同一个数据包的分片,以区别于同一主机或其他主机发送的其它数据包分片,保证分片被正确的重新组合。
-
Identification该字段还在流量分析中也会起到重要的意义。例如在防火墙之前和之后去抓取同一个会话,那么数据在经过防火墙后,其源IP地址和目的IP地址甚至是端口可能都已经被改变了。很难去分辨在防火墙前和防火墙后是否是同一组流量。那么就可以使用Identification这个字段进行判断,因为Identification值是一样的。
-
标识字段唯一的标识主机发送的每一份数据报,通常每发送一个报文,它的值就会加1。
-
-
Flags:标志字段,用于判断是否已经收到最后一个分片。(最后一个分配的标志字段(flag)值为0,其他分片设置为1)
- CU位:当前没有使用。
- DF位:当该位置1的时候,表示禁止对本数据包进行分片操作。
- MF位:当该位置1的时候,表示该数据包片段并不是数据包末尾,也就是“更多的片”,其他每个组成数据报的片都要把该比特置为1。
-
Fragment Offset:片偏移,原始分片中的位置。标识某个分片在分组中的位置。第一个分片的片偏移为0,第二个分片的片偏移表示紧跟第一个分片后的第一个比特的位置。比如,如果首片报文包含1259比特,那么第二片报文的片偏移字段值就应该为1260。
当IP数据报被分片后,每一片都成为一个分组,具有自己的IP首部,并在选择路由时与其他分组独立。这样,当数据报的这些分片到达目的端时有可能会失序,但是在IP首部中有足够的信息让接收端能正确组装这些分片。
尽管IP分片过程看起来是透明的,但是有一个点:即使只丢失一片数据也要重新传递整个数据报。
IP层本身没有超时重传的机制一一由更高层来负责超时和重传(TCP有超时和重传机制,但UDP没有。一些UDP应用程序本身也执行超时和重传)。当来自TCP报文段的某一片丢失后,TCP在超时后会重发整个TCP报文段,该报文段对应于一份IP数据报。没有办法只重传据报中的一个数据报片。
如果对数据报分片的是中间路由器,而不是起始端系统,那么起始端系统就无法知道数据报是如何被分片的。就这个原因,经常要避免分片。
1.7.1 IP 包分片实例
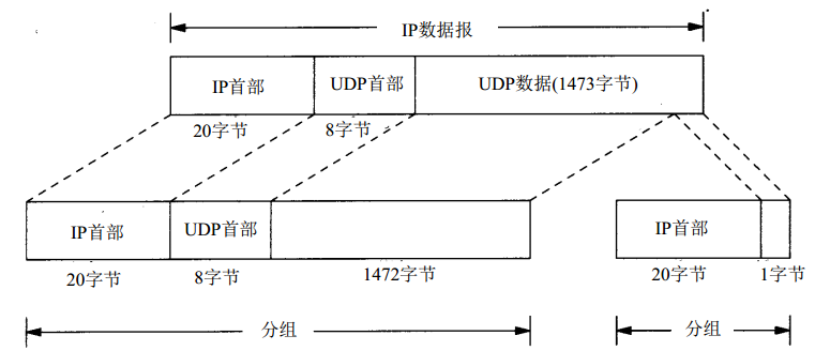
使用UDP很容易导致IP分片,而TCP不会产生IP分片。这是因为TCP限制了传给IP层数据的长度,使IP数据报的长度不会超过路径MTU。
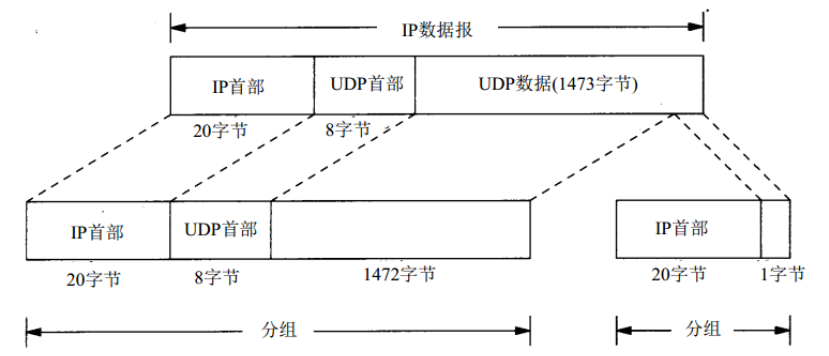
假设网络的MTU为1500字节。当发送一份数据长度为1473字节的UDP数据报时,封装成的IP数据报的长度为1501(1473+8+20)字节,大于路径的MTU值。于是IP层进行分片,一份IP数据报被分成两个分组,其中一个分组包含1472字节数据,另一个分组包含1字节数据。
1.7.2 IP 分片注意事项
- 在分片的时候,除了最后一片外,其他每一片中的数据部分(除 IP 首部外的其余部分)必须是8字节的整数倍。
- IP 首部被复制到各个片中。但是端口号在UDP首部,只能在第1片中被发现。
- IP 数据报是指 IP 层端到端的传输单元(在分片之前和重新组装之后),分组是指在 IP 层和链路层之间传送的数据单元。一个分组可以是一个完整的 IP 数据报,也可以是 IP 数据报的一个分片。
1.7.3 Wireshark 抓取 IP 包分片
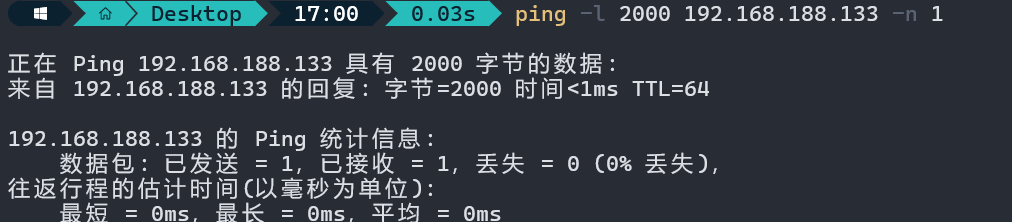
执行ping命令
ping -l 2000 192.168.188.133 -n 1
命令解析:
- -n:表示只发送一个数据包。
- -l:表示指定数据报中的数据(不包含IP首部和ICMP首部),这里是2000字节。
在虚拟机中进行抓包查看:
说明:
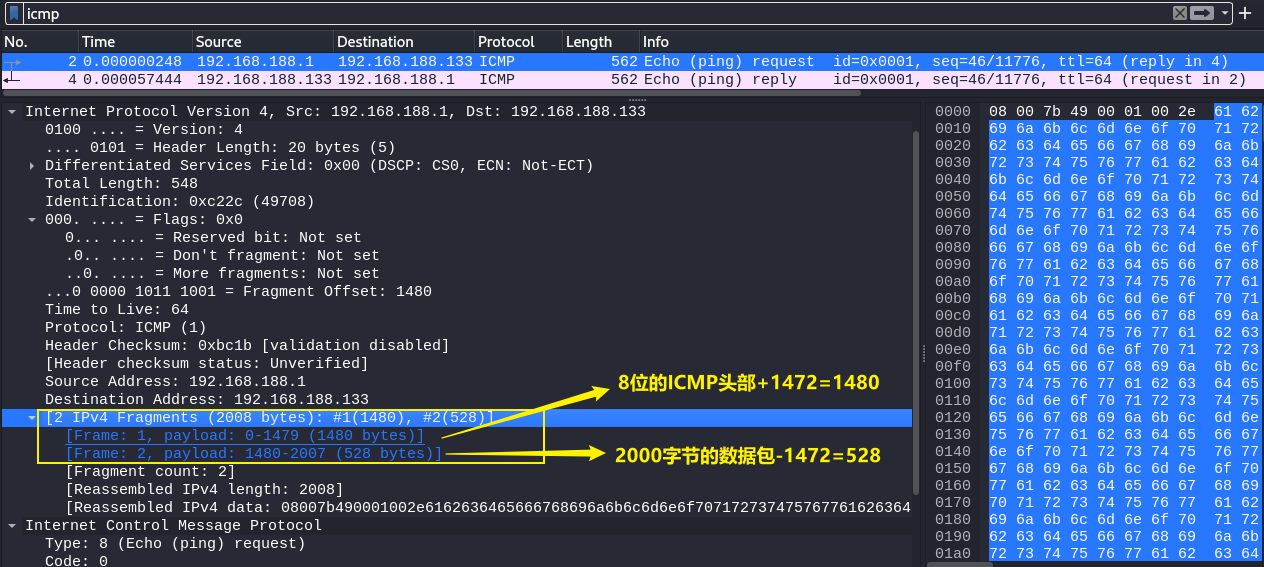
-
DF位为0表示该数据报可以被分片。
-
以太网帧的数据大小最多要求1500个字节,其中IP头部占20个字节,ICMP头部占8个字节。数据部分就只剩下1472个字节了。
-
1472+528=2000。
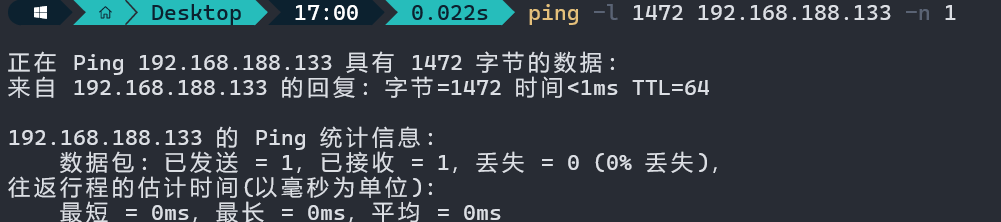
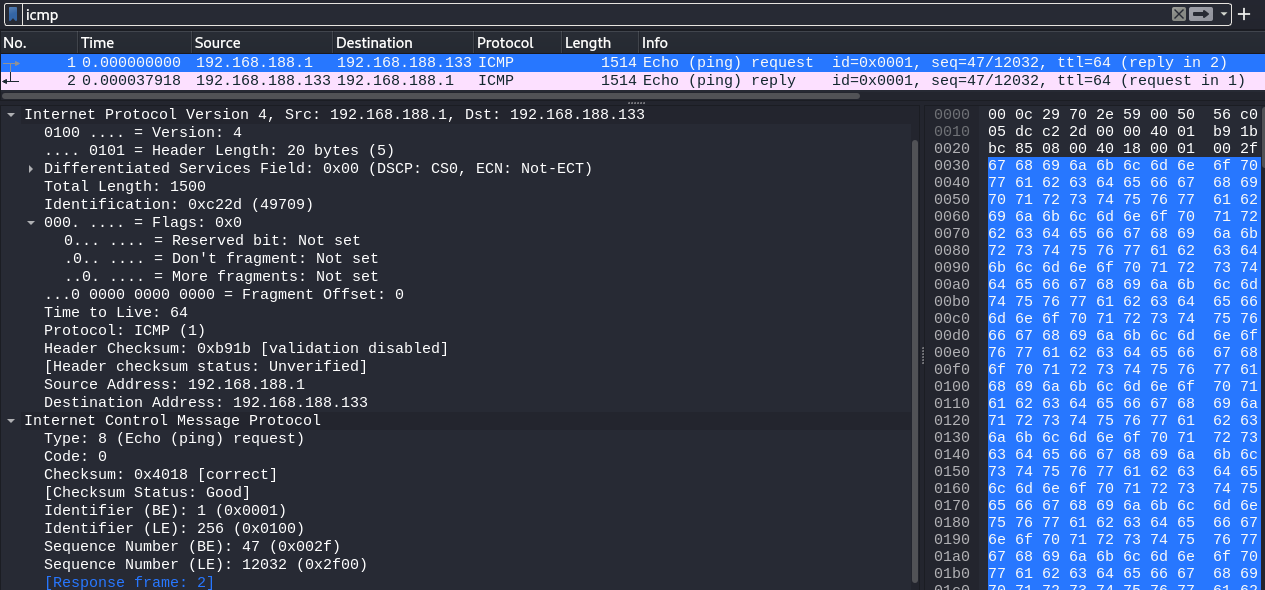
抓取不分片的数据包
ping -l 1472 192.168.188.133 -n 1
1.7.4 OmniPeek 抓取 IP 包分片
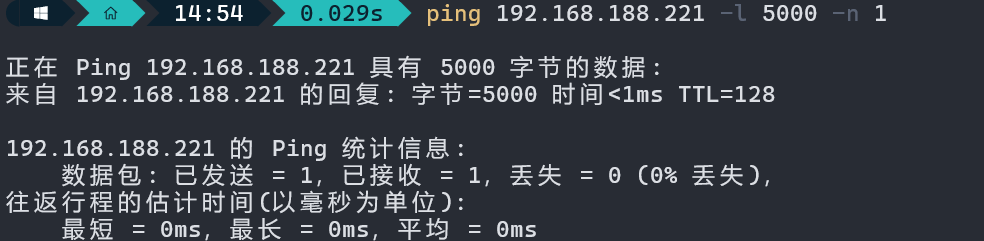
OmniPeek 抓包查看
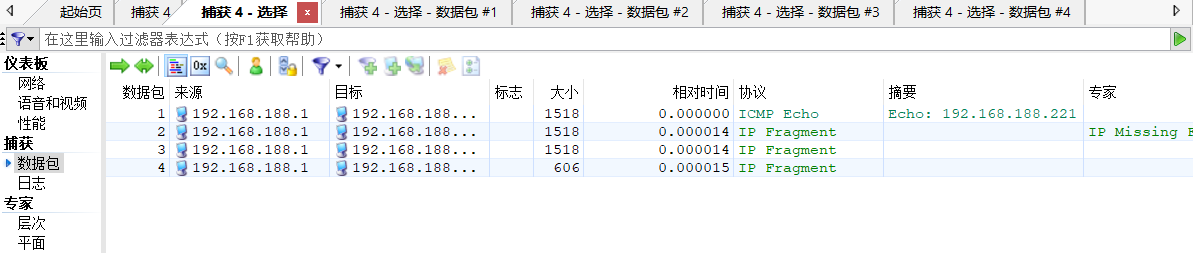
第一个分片
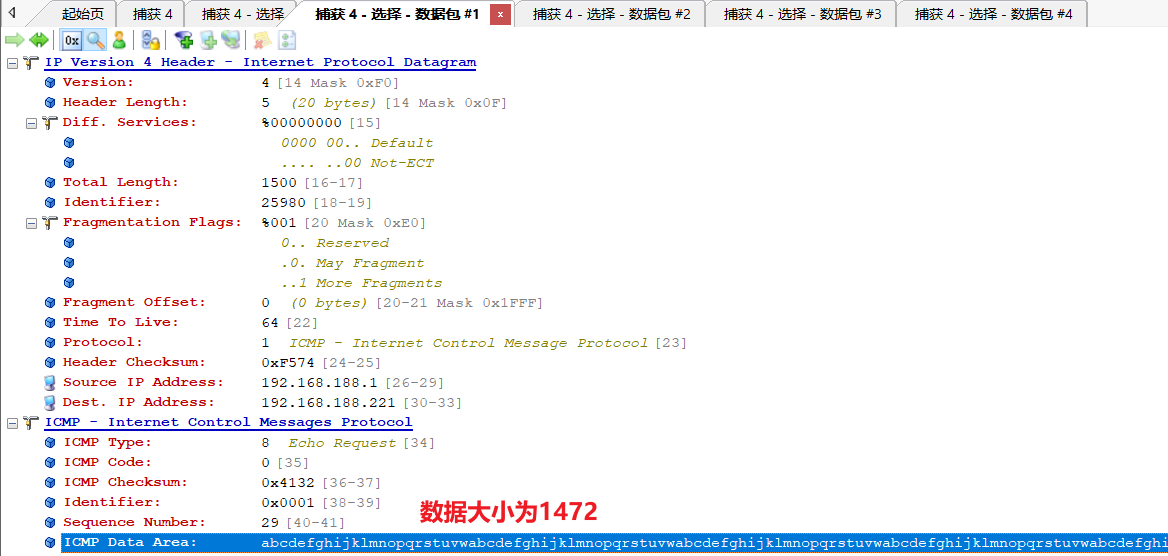
第二个分片
1500-20个字节的IP首部=1480数据部分
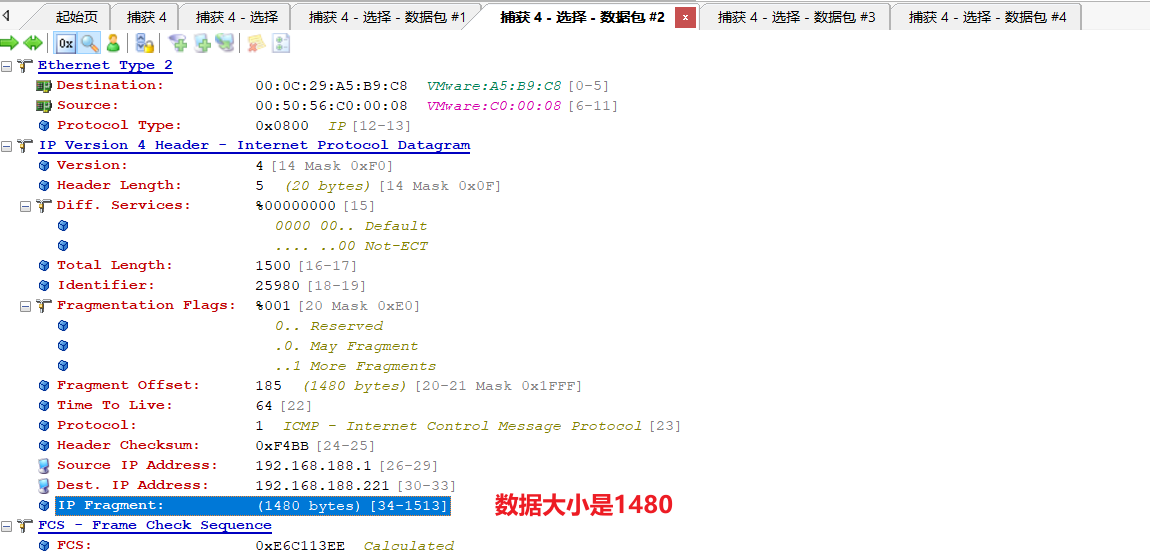
第三个分片
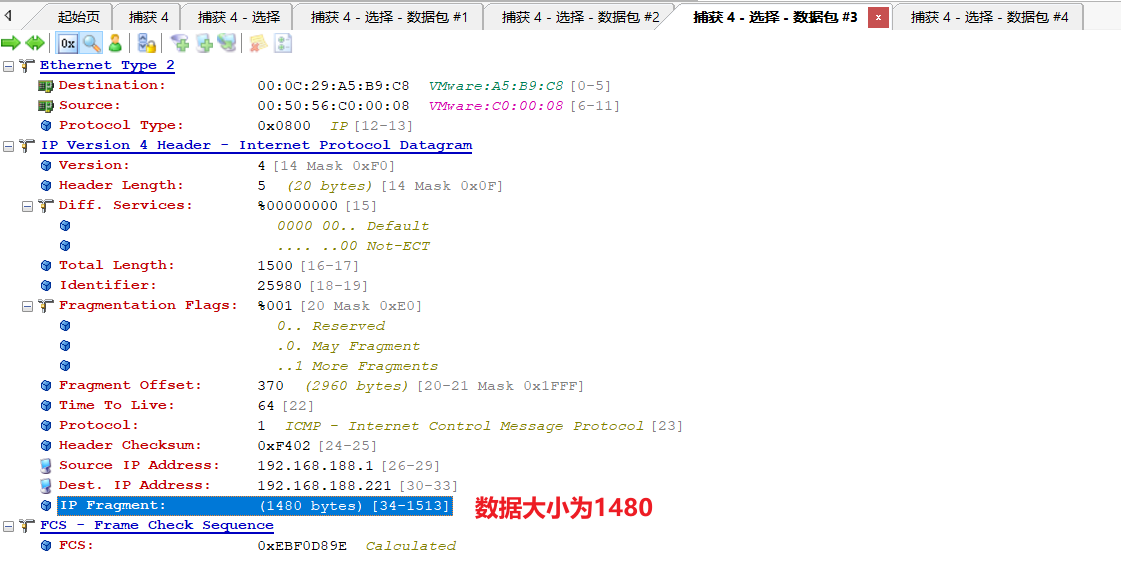
第四个分片
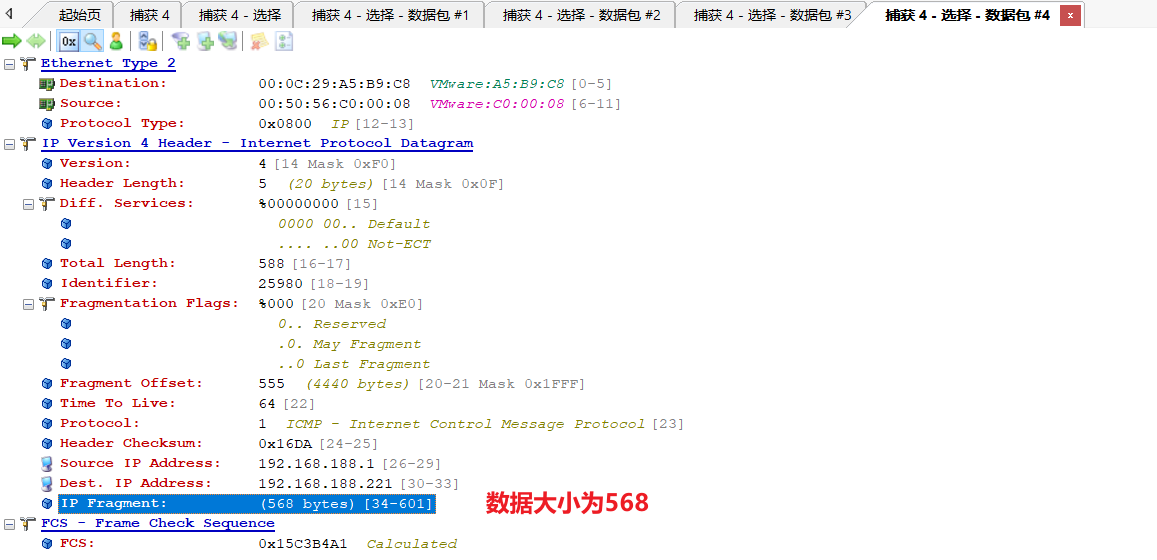
数据长度为1472+1480+1480+568=5000。
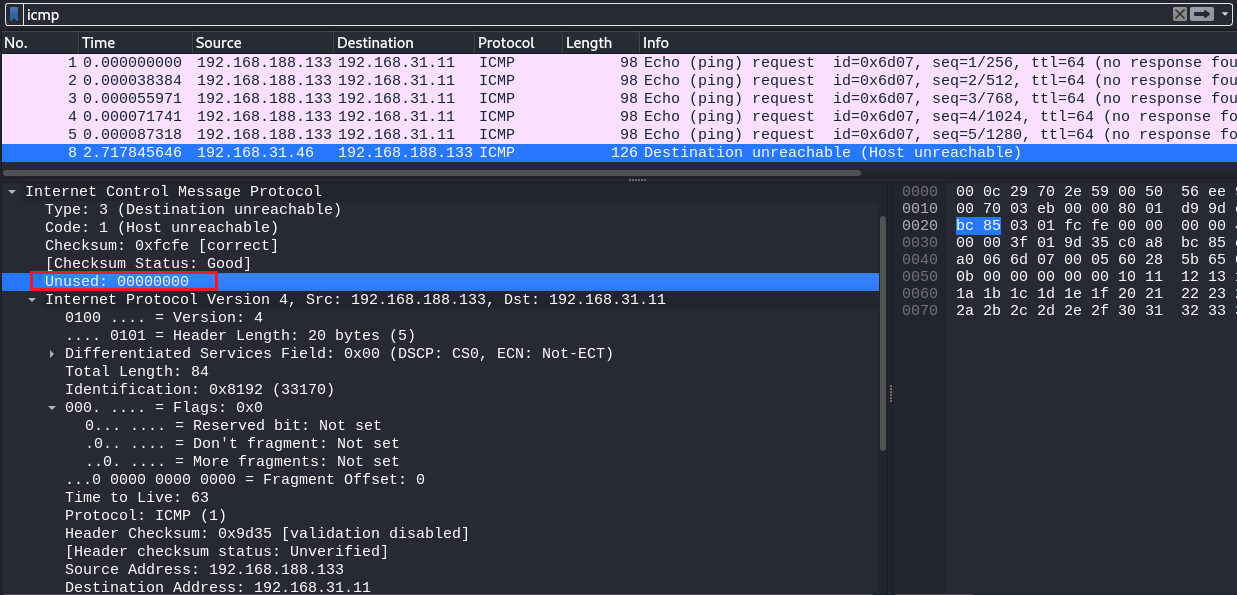
1.7.5 ICMP 不可达差错(需要分片)
ICMP 不可达差错需要分片。

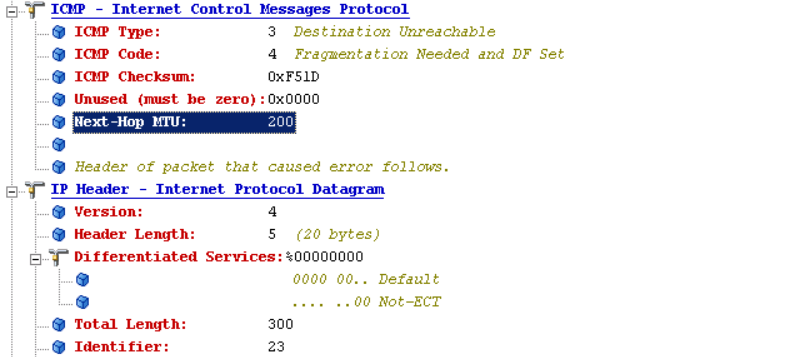
- 发生ICMP不可达差错的另一种情况是,当路由器收到一份需要分片的数据报,而在IP首部又设置了不分片(DF)位。该差错报文的格式如上。
- 如果程序需要判断到达目的端的路径中最小MTU是多少,那么这个差错就可以被该程序使用。
- 下一站点网络的MTU字段有些操作系统可能不支持。
思科路由器会支持显示下一站网络的MTU。
1.7.6 实例
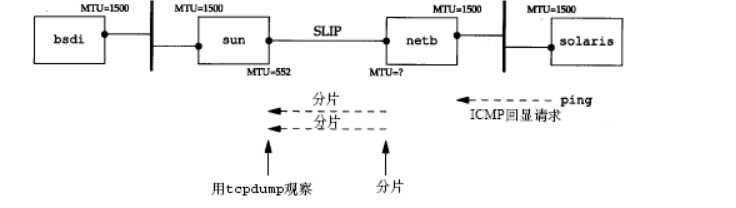
- 在点到点的链路中,不会去要求两个方向的MTU为相同的值。
- 在主机sun上运行tcpdump,观察SLIP链路,看什么时候发生分片。开始没有观察到分片,一切都很正常直到ping分组的数据长度从500增加到600字节。可以看到接收到的回显请求(仍然没有分片),但不见回显应答。
- Ping的时候DF置位为0。
解析:主机solaris在和主机bsdi通信的时候,数据长度设置为600字节,在主机netb的MTU值是大于600的所以是可以通过并不需要就行分片操作。而主机sun的路径MTU是552(ping程序检查的出接口,这个MTU=552是入接口,所以在去的时候是不需要分片的)。但是在回来的时候由于MTU值是大于600,所以主机sun这里的出接口是过不来的。看不见回显应答,返回一个ICMP 不可达差错报文,不会返回给主机solaris,而是返回给主机bsdi。
1.8 生存时间/首部校验和


说明:
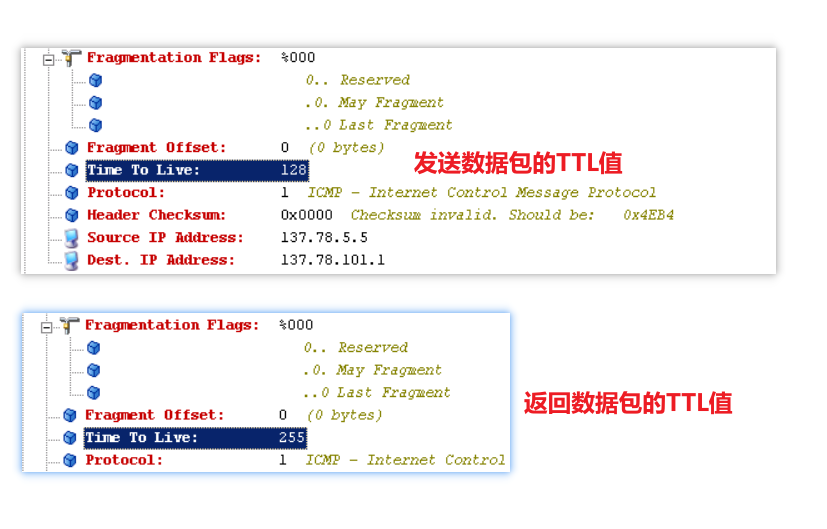
-
Time to Live 生存周期:数据包每经过一个三层设备转发就将TTL值减1,当生存周期TTL为0时,向源IP地址发送ICMP错误消息。不同都操作系统的默认TTL值不同,Linux中的TTL值位64,Windows中的TTL值为128。(但是这个TTL值是可以修改的,只能是作为一个参考)
-
并且有时候每个方向的TTL值是不一样的,有可能发包的时候TTL值是128,返回可能TTL值是255。
-
-
Header Checksum 首部校验和:长16位,只对IPv4头部进行校验,如果出现错误则丢弃数据包。
- 首部检验和字段是根据IP首部计算的检验和码。它不对首部后面的数据进行计算。ICMP、IGMP、UDP和TCP在它们各自的首部中均含有同时覆盖首部和数据检验和码。
数据包在网络中传输为什么会出现拥塞?
- 报文在网段间转发时,如果网络设备上的路由规划不合理,就可能会出现环路,导致报文在网络中无限循环,无法到达目的端。环路发生后,所有发往这个目的地的报文都会被循环转发,随着这种报文逐渐增多,网络将会发生拥塞。
TTL解决环路导致拥塞
- 为避免环路导致的网络拥塞,IP报文头中包含一个生存时间TTL(Time To Live)字段。报文每经过一台三层设备,TTL值减1。初始TTL值由源端设备设置(自己设置)。当报文中的TTL降为0时,报文会被丢弃。同时,丢弃报文的设备会根据报文头中的源IP地址向源端发送ICMP错误消息。
Ping是ICMP协议
1.9 协议位
协议字段被 IP 用来对数据报进行分用,根据它可以识别是哪个协议向IP传送数据。
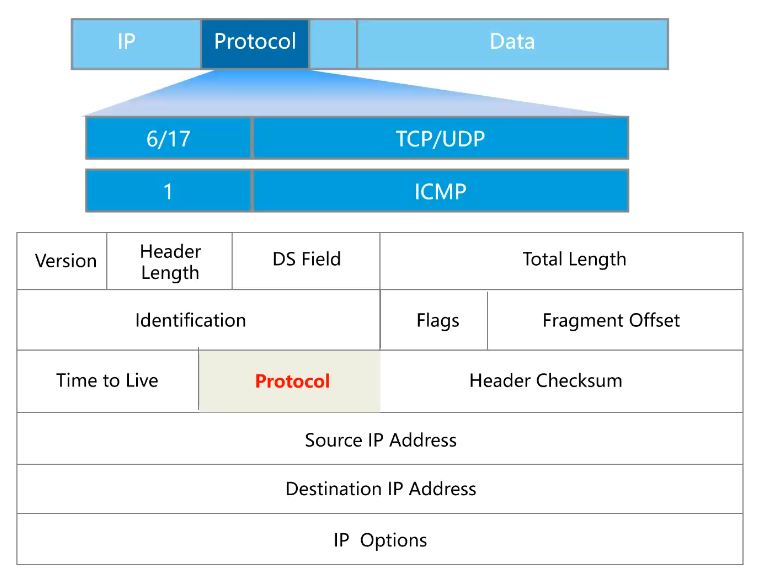
目的端的网络层在接收并处理报文以后,需要决定下一步对报文该做如何处理。IP报文头中的**协议字段(Protocol)**标识了将会继续处理报文的协议。与以太帧头中的Type字段类似,协议字段也是一个十六进制数。
IP报文头中的协议字段也标识上层协议如:
-
ICMP 控制消息协议,对应值0x01。
-
TCP 传输控制协议,对应值0x06。
-
UDP 用户数据报协议,对应值0x17。
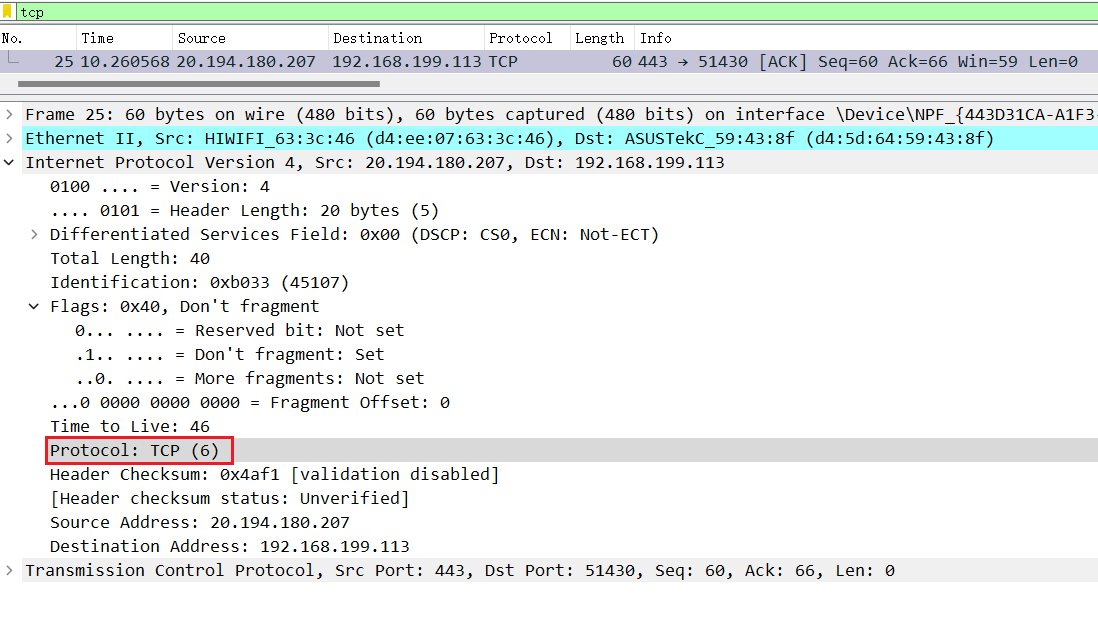
1.10 IP 首部的选项
最后一个字段是选项,它是数据报中的一个可变长的可选信息。选项字段以32位作为界限,在必要的时候插入值为0的填充字节。这样就保证IP首部长度始终是32位的整数倍(这是首部长度字段所要求的)。
有如下几个选项:
- 记录路径(让每个路由器都记下它的IP地址)。
- 时间戳(让每个路由器都记下它的IP地址和时间)。
- 宽松的源站选路(为数据报指定一系列必须经过的IP地址)。
- 严格的源站选路(与宽松的源站选路类似,但是要求只能经过指定的这些地址,不能经过其他的地址)。
这些选项很少被使用,并非所有的主机和路由器都支持这些选项。选项字段一直都是以32bit作为界限,在必要的时候插入值为0的填充字节。这样就保证IP首部始终是32bit的整数倍(这是首部长度字段所要求的)。
1.11 IP 路由选择
数据报从主机bsdi到sun的传送过程。
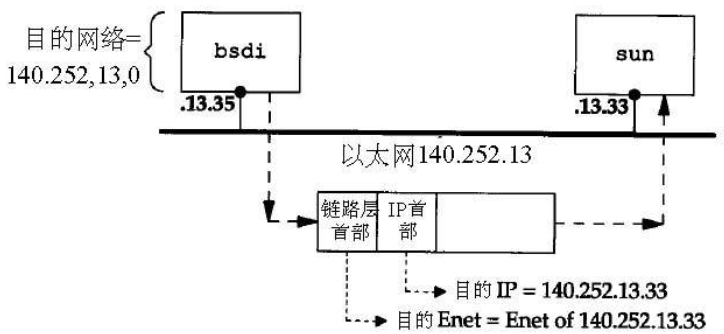
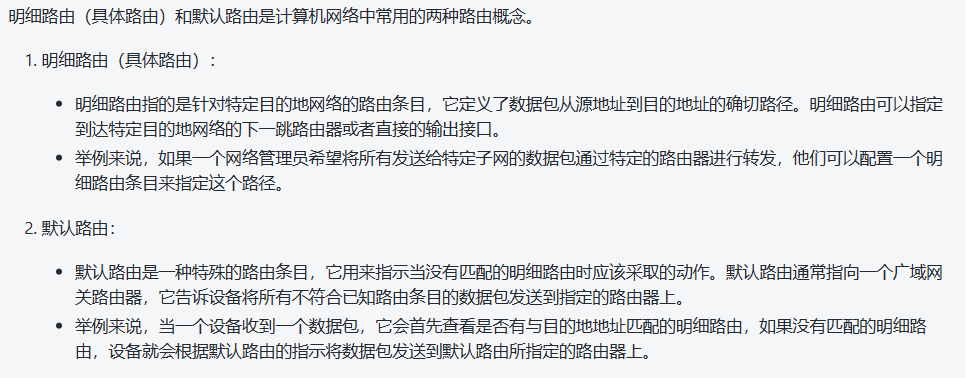
查询路由的过程:
- 策略明细路由
- 明细路由
- 策略默认路由
- 默认路由

1.12 特殊情况的 IP 地址
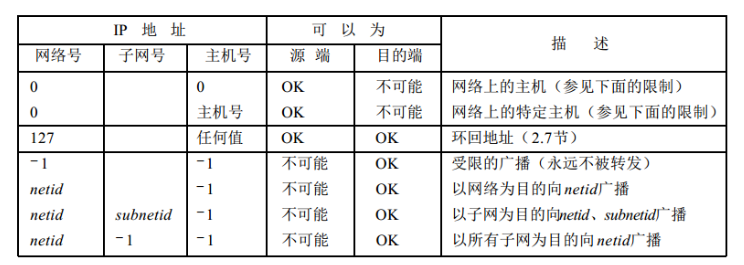
- 在这个图中,0表示所有的比特位全为0。-1表示所有的比特位全为1。netid、subnetid和hostid分别表示不为全0或全1的对应字段。子网号栏为空表示该地址没有进行子网划分。
- 表的头两项是特殊的源地址,中间项是特殊的环回地址,最后四项是广播地址。
- 表中的头两项,网络号为0,如主机使用BOOTP协议确定本机IP地址时只能作为初始化过程中的源地址出现。
DHCP的源IP地址就是0.0.0.0 。
127.0.0.1是环回地址,但是127后面随便写都是环回地址。
2. IP 选路
IP选路的原理涉及计算机网络中的路由协议和路由表。当数据包到达路由器时,路由器需要决定将数据包发送到哪个接口以及下一跳的地址是什么。
除了传统的路由选择方式外,还可以通过使用IP选路选项(如IP源站选路选项),来指定数据包的传输路径,以实现特定的路由策略和行为控制。
2.1 IP 选路概念
选路是IP最重要的功能之一。下图是IP层处理过程的简单流程。需要进行选路的数据报可以由本地主机产生,也可以由其他主机产生。在后一种情况下,主机必须配置成一个路由器,否则通过网络接口接收到的数据报,如果目的地址不是本机就要被丢弃(例如,悄无声息地被丢弃)。
在下图中,描述了一个路由守护程序( daemon),通常这是一个用户进程。在Unix系统中,大多数普通的守护程序都是路由程序和网关程序(术语 daemon指的是运行在后台的进程,它代表整个系统执行某些操作。 daemon一般在系统引导时启动,在系统运行期间一直存在)。在某个给定主机上运行何种路由协议,如何在相邻路由器上交换选路信息,以及选路协议是如何工作的,所有这些问题都是非常复杂的。
下图所示的路由表经常被IP访问(在一个繁忙的主机上,一秒钟内可能要访问几百次),但是它被路由守护程序更新的频度却要低得多(可能大约30秒种一次)。当接收到ICMP重定向,报文时,路由表也要被更新。
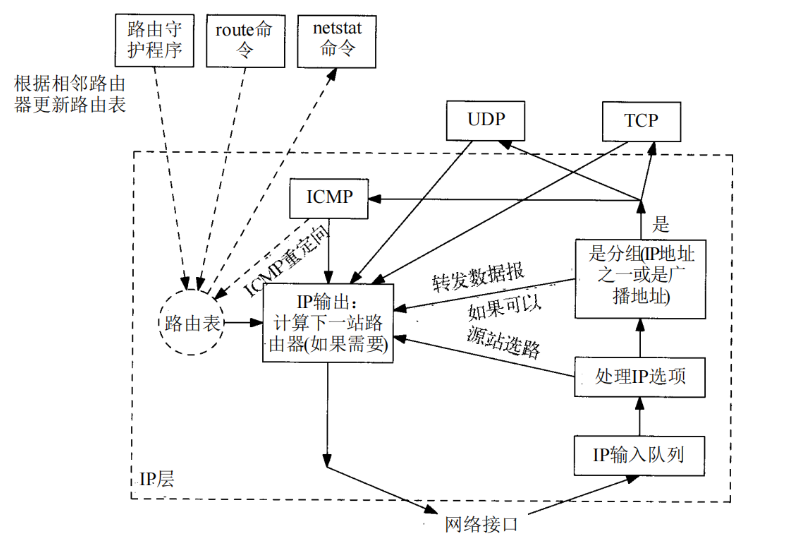
路由守护程序:动态路由协议RIP协议,OSPF协议。
2.2 选路原理
开始讨论 IP 选路之前,首先要理解内核是如何维护路由表的。路由表中包含的信息决定了 IP 层所做的所有决策。
IP 搜索路由表的几个步骤:
-
搜索匹配的主机地址;
-
搜索匹配的网络地址;
-
搜索默认表项(默认表项一般在路由表中被指定为一个网络表项,其网络号为 0)。
匹配主机地址步骤始终发生在匹配网络地址步骤之前。
IP层进行的选路实际上是一种选路机制,它搜索路由表并决定向哪个网络接口发送分组。(可以添加路由表)
这区别于选路策略,它只是一组决定把哪些路由放入路由表的规则。 IP 执行选路机制,而路由守护程序则一般提供选路策略。
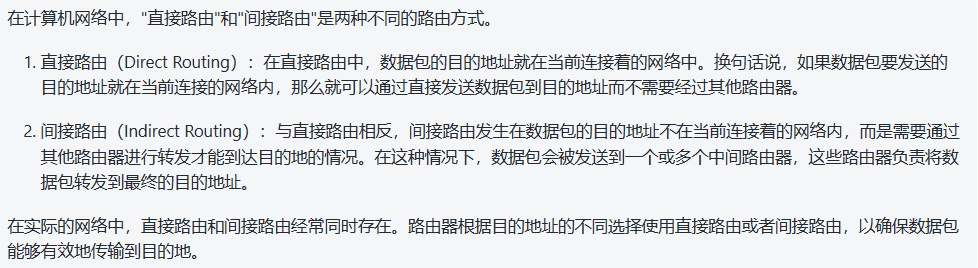
2.3 简单路由表
下图是“srv4”主机的路由表:
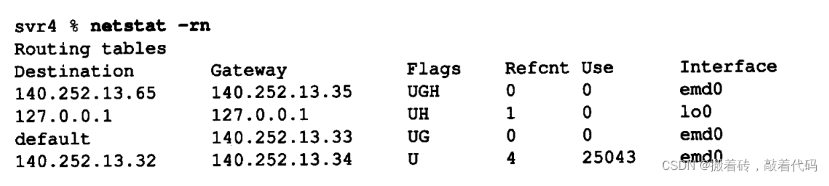
对于一个给定的路由器,可以打印出五种不同的标志( flag):
- U 该路由可以使用。
- G 该路由是到一个网关(路由器)。如果没有设置该标志,说明目的地是直接相连的。
- H 该路由是到一个主机,也就是说,目的地址是一个完整的主机地址。如果没有设置该标志,说明该路由是到一个网络,而目的地址是一个网络地址:一个网络号,或者网络号与子网号的组合。
- D 该路由是由重定向报文创建的。
- M 该路由已被重定向报文修改。
标志G是非常重要的,因为由它区分了间接路由和直接路由(对于直接路由来说是不设置标志G的)。其区别在于:发往直接路由的分组中的IP地址是目的端的IP地址,链路层地址是目的端的链路层地址。而当分组被发往一个间接路由时,分组中的IP地址还是目的端的IP地址,但是链路层地址却是网关(即下一跳路由器)的链路层地址。
链路层地址也称为MAC地址。
Linux下查看路由表
netstat -rn

Windows下查看路由表
route print
netstat -r
2.4 路由查找失败
如果路由表中没有默认表项,而又没有找到匹配项,这时会发生什么情况呢?结果取决于该IP数据报是由本机产生的还是被转发的(主机充当一个路由器)。如果数据报是本机产生的,那么就给发送该数据报的应用程序返回一个错误,或者是“主机不可达差错”或者是“网络不可达差错”。如果是被转发的数据报,那么就给发送该数据报的主机发送一份ICMP主机不可达的差错报文。
2.5 ICMP 重定向差错
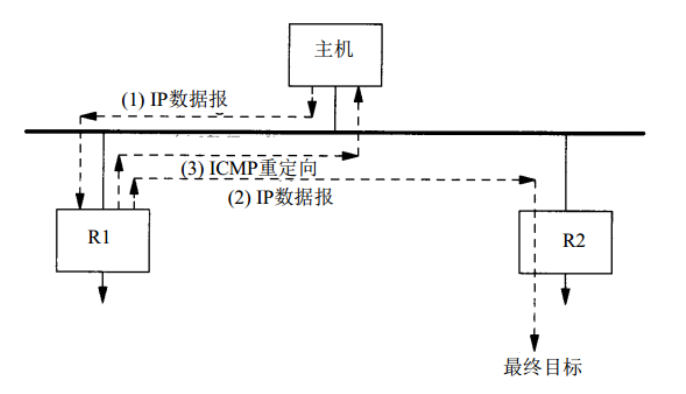
- 假定主机发送一份IP数据报给R1(R1是主机的默认网关)。
- R1收到数据报并且检查它的路由表,发现R2是发送该数据报的下一跳。当它把数据报发送给R2时,R1检测到它正在发送的接口与接收到数据报的接口是相同的。
- R1发送一份ICMP重定向报文给主机,告诉它以后把数据报发送给R2而不是R1。
一旦默认路由发生差错,默认路由器将通知它进行重定向,并允许主机对路由表作相应的改动。
ICMP 重定向报文的格式如下:
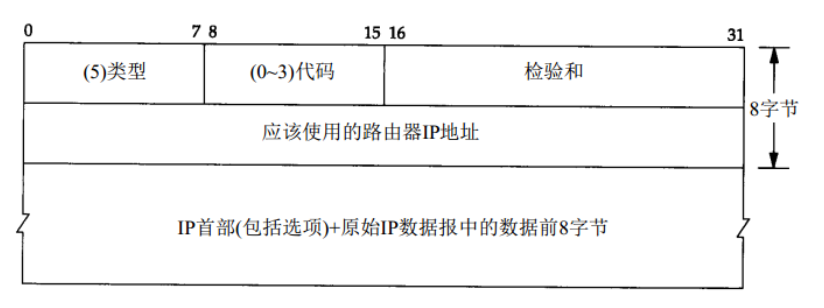
ICMP重定向报文的接收者(主机)必须查看三个IP地址:
1. 导致重定向的IP地址(即ICMP重定向报文中包含的IP首部中的目的IP地址)。(目的IP地址)
2. 发送重定向报文的路由器的IP地址(IP数据报首部中的源IP地址)。(网关)
3. 应该采用的路由器IP地址(ICMP重定向报文中的4~7字节)。(优化的网关)

ICMP 重定向数据包
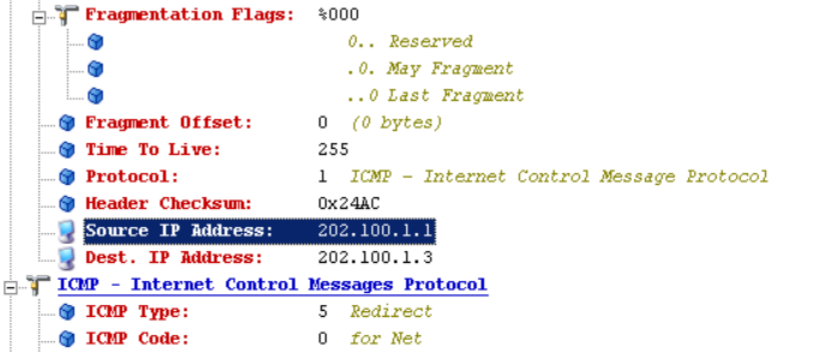
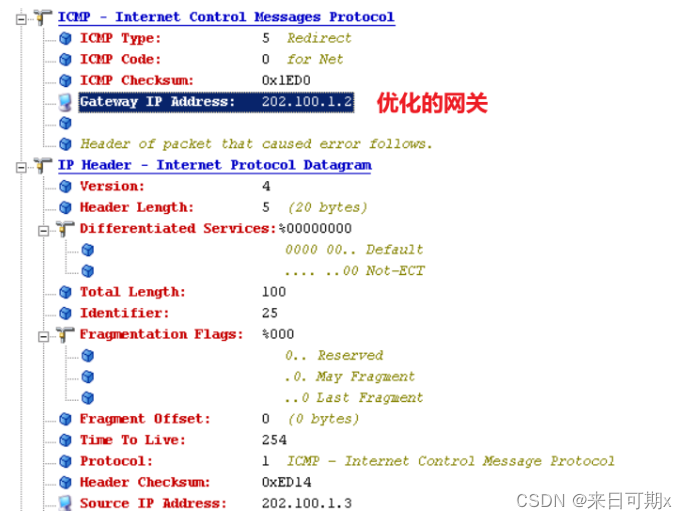
R1去往2.2.2.2的时候要走202.100.1.2这个IP
2.6 重定向的条件
在生成ICMP重定向报文之前这些条件需要满足:
- 出接口必须等于入接口。
- 用于向外传送数据包的路由不能被ICMP重定向报文创建或者修改过,而且不能是路由器的默认路由。
- 数据包不能用源站选路来转发。
- 内核必须配置成可以发送重定向报文。
- 在修改路由表之前要作一些检查。这是为了防止路由器或主机的误操作,以及恶意用户的破坏,导致错误地修改系统路由表。
- 新的路由器必须直接与网络相连接。
- 重定向报文必须来自当前到目的地所选择的路由器。
- 重定向报文不能让主机本身作为路由器。
- 被修改的路由必须是一个间接路由。
这篇关于TCP/IP详解——IP协议,IP选路的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





