本文主要是介绍DRBD分布式存储实验,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
DRBD
DRBD的全称为:Distributed Replicated Block Device (DRBD) 分布式块设备复制 与心跳连接结合使用,构建高可用性(HA)的集群。
实现方式是通过网络来镜像(mirror)整个设备。它允许用户在远程机器上建立一个本地块设备的实时镜像。DRBD负责接收数据,把数据写到本地磁盘,然后发送给另一个主机。另一个主机再将数据存到自己的磁盘中。
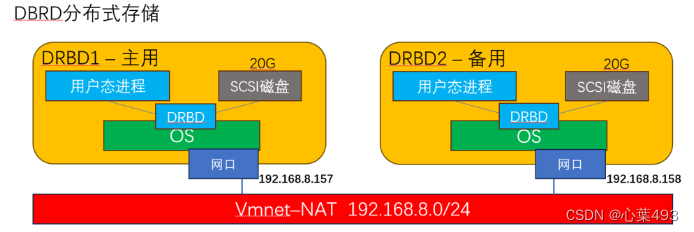
DRBD分为主用节点和备用节点,在设置了DRBD设备之后,DRBD会接管磁盘,通过tcp通过网卡连接另外节点的DRBD设备,最后虚拟出一个逻辑磁盘-DRBD磁盘,DRBD会根据DRBD磁盘数据的变化,将数据写入底下的磁盘
参考文档
DRBD - LINBIT
环境
centos8-stream
centos8-DRBD1 192.168.8.157/24 主节点
centos8-DRBD2 192.168.8.158/24 备节点
——8G内存,4core
——nat网络
——系统盘100G
——20G SCSI磁盘 - 用以被DRBD接管
——最小化安装
拓扑
DRBD安装
#设置软件源
rm -rf /etc/yum.repos.d/*
cat > /etc/yum.repos.d/iso.repo <<END
[AppStream]
name=AppStream
baseurl=http://mirrors.163.com/centos/8-stream/AppStream/x86_64/os/
enabled=1
gpgcheck=0
[BaseOS]
name=BaseOS
baseurl=http://mirrors.163.com/centos/8-stream/BaseOS/x86_64/os/
enabled=1
gpgcheck=0
[epel]
name=epel
baseurl=https://mirrors.tuna.tsinghua.edu.cn/epel/8/Everything/x86_64/
gpgcheck=0
END
yum clean all
yum makecache#设置主机名
hostnamectl set-hostname DRBD01 && bash
hostnamectl set-hostname DRBD02 && bash#安全相关
sed -i 's/SELINUX=enforcing/SELINUX=permissive/' /etc/selinux/config
setenforce 0
systemctl disable firewalld --now#设置host文件
echo "
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.8.157 DRBD01
192.168.8.158 DRBD02
" > /etc/hosts#安装编译软件和依赖
yum -y group install "Development Tools" && yum -y install wget vim net-tools lvm2
yum -y install drbd #如果使用默认源可能没有这个包
#从官网下载安装包,编译安装
wget https://pkg.linbit.com//downloads/drbd/9/drbd-9.1.11.tar.gz
tar zxvf drbd-9.1.11.tar.gz
cd drbd-9.1.11
make && make install
DRBD配置
#把drbd模块暂时加载到内核中
modprobe drbd
lsmod | grep -i drbd#把drbd模块持久化加载到内核中
echo drbd > /etc/modules-load.d/drbd.conf#drbd配置文件
drbd配置文件/etc/drbd.d/global_common.conf
#[global]全局参数
#[common]通用参数- handlers -startup - options -disk -net
drbd主配置文件/etc/drbd.conf#创建卷
pvcreate /dev/sdb
vgcreate drbd /dev/sdb #卷组名drbd
lvcreate -n drbd -l 100%free drbd #逻辑卷drbd,所有空间都分配,也可以直接指定20G#修改配置文件,添加文件
echo "
#指定资源名为ws-drbd
resource ws-drbd {
#指定元数据
meta-disk internal;
#指定逻辑磁盘
device /dev/drbd1;
net {
verify-alg sha256;
}
#指定节点,与对应的逻辑卷
on DRBD01 {
address 192.168.8.157:7788;
disk /dev/drbd/drbd;
}
on DRBD02 {
address 192.168.8.158:7788;
disk /dev/drbd/drbd;
}
} " > /etc/drbd.d/ws-drdb.res#创建drbd资源
drbdadm create-md ws-drbd
drbdadm up ws-drbd#此时已经设置完成,两台节点都显示如下
drbdadm status
#ws-drbd role:Secondary
# disk:Inconsistent 非一致性状态
# DRBD01 role:Secondary
# peer-disk:Inconsistent#在主节点上设置主节点
drbdadm primary ws-drbd --force验证与测试
drbdadm status #同步中
#ws-drbd role:Primary
# disk:UpToDate
# DRBD02 role:Secondary
# replication:SyncSource peer-disk:Inconsistent done:16.60lsblk #能看到多了一个drbd1磁盘
#NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
#sda 8:0 0 100G 0 disk
#├─sda1 8:1 0 1G 0 part /boot
#└─sda2 8:2 0 99G 0 part
# ├─cs-root 253:0 0 65.2G 0 lvm /
# ├─cs-swap 253:1 0 2G 0 lvm [SWAP]
# └─cs-home 253:2 0 31.8G 0 lvm /home
#sdb 8:16 0 20G 0 disk
#└─drbd-drbd 253:3 0 20G 0 lvm
# └─drbd1 147:1 0 20G 0 disk
#sr0 11:0 1 12.3G 0 romdrbdadm status #同步完成
#ws-drbd role:Primary
# disk:UpToDate
# DRBD02 role:Secondary
# peer-disk:UpToDate#测试是否能够同步
#在主节点上操作
mkfs.ext4 /dev/drbd1
mount /dev/drbd1 /mnt/
echo 1 > /mnt/test
poweroff#在备节点上操作
#能看到test已经被同步到备节点的drbd1中
mount /dev/drbd1 /mnt/
ls /mnt/
#lost+found test这篇关于DRBD分布式存储实验的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



