本文主要是介绍[线上问题] 线上服务器内存使用量已达到90%报警(内存泄漏),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
2016-05-06中午11:56,收到“[sentry2]2016-05-06 11:56:09 xxxxxxhost xxx.xxx.xxx.xxx 内存使用已达到90.18%”报警。首先在脑海浮现的,应该哪里出现内存泄漏了。
一、确认问题
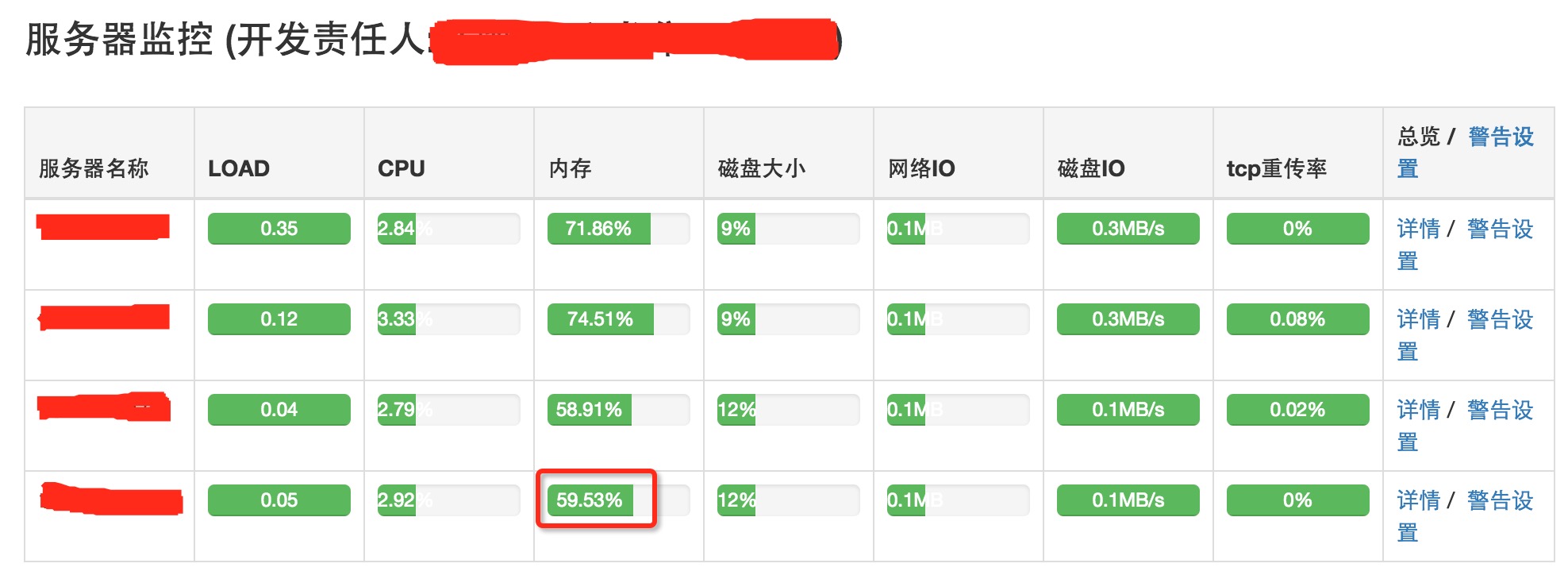
马上到 Sentry 监控系统查看了该服务的“服务器监控”指标,发现其中2台机器的内存使用量都超过了90%,另外2台尽然没有监控数据(以前是有的)。

对于另外2台服务器没有监控数据,只好先登上去查看确认一下喽。通过“free -m”确认,线上服务器总内存共 7872MB,使用了 7098MB,还有 773MB(= 406 + 151 + 216) 空闲着,使用率为 90.16%(= 7098 / 7872)。(参考:free(1) - Linux manual page、Linux Used内存到底哪里去了? | 褚霸-余锋)

从问题表现来看,该业务的4台机器都出现“内存使用量都超过了90%”。
二、排查问题
1. 对比一下该业务“服务器内存占用百分比”的历史状况
1.1 3月26日业务刚上线时,服务器内存占用百分比是 45%。
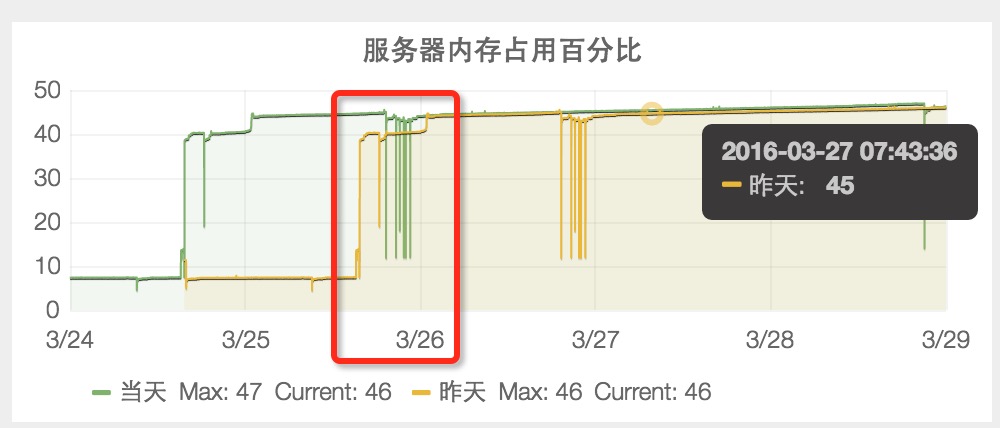
1.2 4月14日之前,服务器内存占用百分比稳定在 48%。
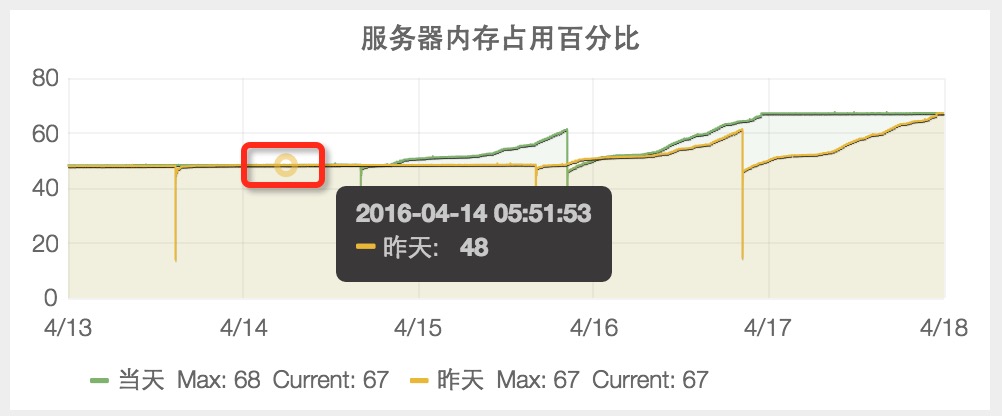
1.3 4月15日,服务器内存占用百分比突然从 48% 升到 61%。
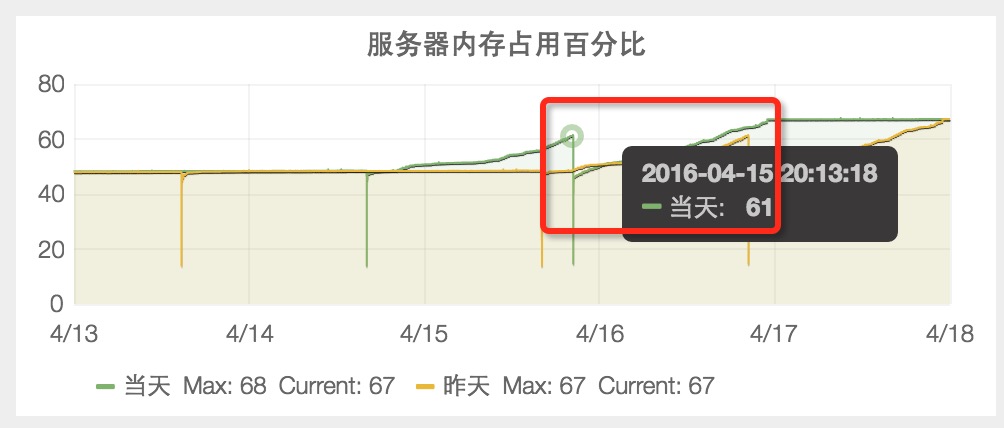
1.4 4月17日,服务器内存占用百分比稳定在 67%。
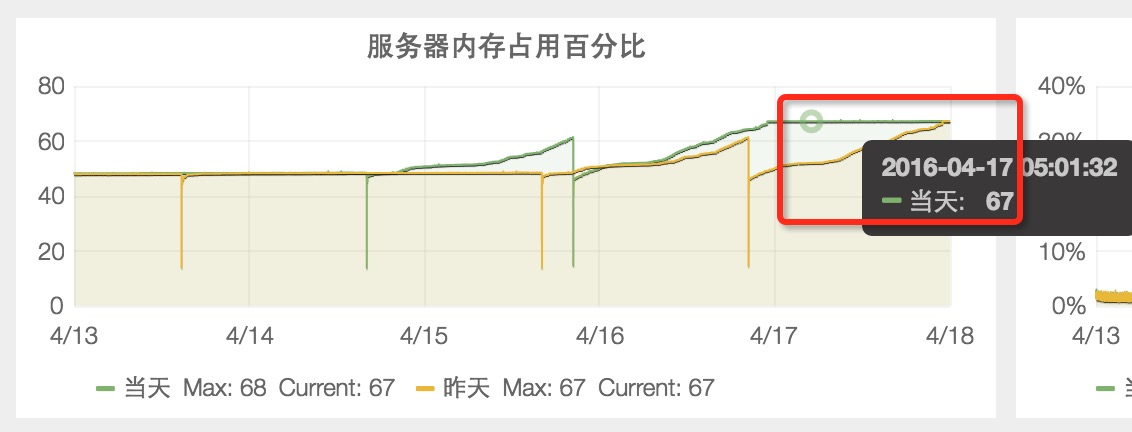
1.5 4月18日到5月2日期间,服务器内存占用百分比稳定在 68%。

1.6 5月3日直到5月6日的报警期间,服务器内存占用百分比又从 68% 升到 90%。
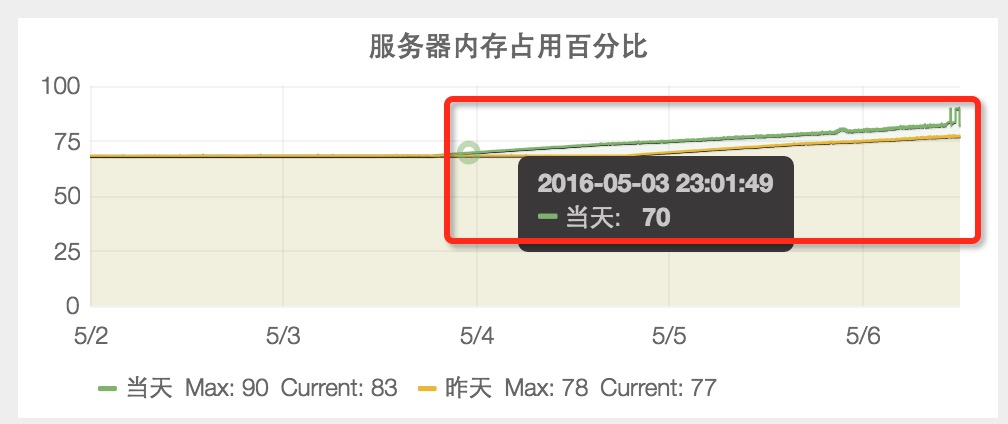
从“服务器内存占用百分比”历史数据的异常时间点(4月17日、5月3日)来看,我们自己都没有发布上线过代码,说明不是我们引起的。
2. 查看 Sentry 监控系统的“进程监控”指标,运维同学发现 logagent 进程内存占用了 580MB。他们刚优化了 logagent 组件,1分钟在线平滑升级后(线上业务服务不需要重启),内存从 580MB 降到 54MB,还是很可观的。这样服务器的空闲内存又多出了500+MB,为排查线上问题留出了更多的时间。(当时做得不够好的地方,应该只保留一台作为现场排查问题,重启其他机器,避免线上可能因为所有机器 OOM 而导致整个服务不可用)(当时我们都没看到 sentry_agent 进程占用了近 1.3GB

)
3. 内存泄漏的可能性最大,先验证之
向有经验的同学请教,说内存使用量飙高,一般都是中间件引起的内存泄漏。因为我们线上服务使用 Java 语言开发,所以先从 JVM 垃圾收集器 GC 入手,可以比较直观地看出 JVM 内存状况。(jstat -gcutil `pgrep -u mapp java` 1s)
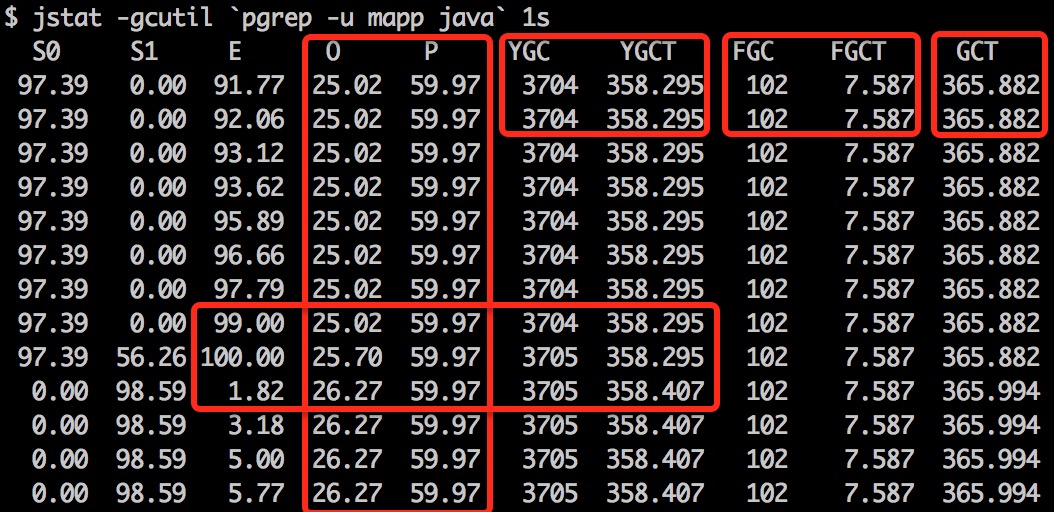
上图输出的每个字段的含义见 jstat -gcutil 命令参考文档。从上图看,Eden 区(Eden Space (heap))内存占用每秒增长 1.5%,Survivor 区(Survivor Space (heap),S0、S1)内存占用在一次垃圾收集后增长 1.2%,Old 区(Tenured Generation (heap))内存占用在一次垃圾收集后增长 0.57%,Perm 区(Permanent Generation (non-heap))内存一直占用 59.97%。Young GC 平均耗时为 96.7ms ( = 358.407 / 3705),Full GC 平均耗时为 74.4ms(= 7.587 / 102)。
从“gc 监控”看,也没收到 Full GC 报警。同时查看 gc.log,ParNew GC 大约每隔几分钟触发一次,CMS GC 大约每隔5个小时触发一次,没有 Full GC。从 JVM 内存监控数据来看,说明 GC 都正常的。
3. 哪些进程用了那么多内存
从上面@褚霸在《Linux Used内存到底哪里去了?》总结的:内存的去向主要有3个:1. 进程消耗,2. slab消耗,3. pagetable消耗。
先看一下线上服务器的 JVM 配置(jps -lv):
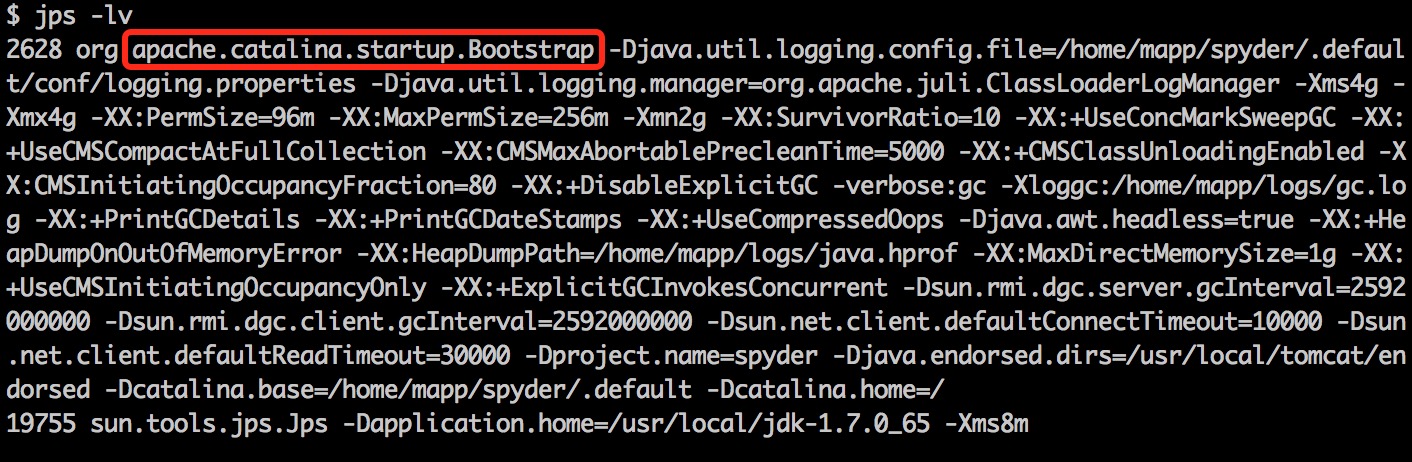
2628 org.apache.catalina.startup.Bootstrap -Djava.util.logging.config.file=/home/mapp/spyder/.default/conf/logging.properties -Djava.util.logging.manager=org.apache.juli.ClassLoaderLogManager -Xms4g -Xmx4g -XX:PermSize=96m -XX:MaxPermSize=256m -Xmn2g -XX:SurvivorRatio=10 -XX:+UseConcMarkSweepGC -XX:+UseCMSCompactAtFullCollection -XX:CMSMaxAbortablePrecleanTime=5000 -XX:+CMSClassUnloadingEnabled -XX:CMSInitiatingOccupancyFraction=80 -XX:+DisableExplicitGC -verbose:gc -Xloggc:/home/mapp/logs/gc.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+UseCompressedOops -Djava.awt.headless=true -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/home/mapp/logs/java.hprof -XX:MaxDirectMemorySize=1g -XX:+UseCMSInitiatingOccupancyOnly -XX:+ExplicitGCInvokesConcurrent -Dsun.rmi.dgc.server.gcInterval=2592000000 -Dsun.rmi.dgc.client.gcInterval=2592000000 -Dsun.net.client.defaultConnectTimeout=10000 -Dsun.net.client.defaultReadTimeout=30000 -Dproject.name=xxxxxx -Djava.endorsed.dirs=/usr/local/tomcat/endorsed -Dcatalina.base=/home/mapp/spyder/.default -Dcatalina.home=/
从 JVM 配置来看,最大内存为 4GB。
接着就是通过“top -M”(按RES字段排序:按 f,然后再按 q)观察哪些进程占用的内存不正常。
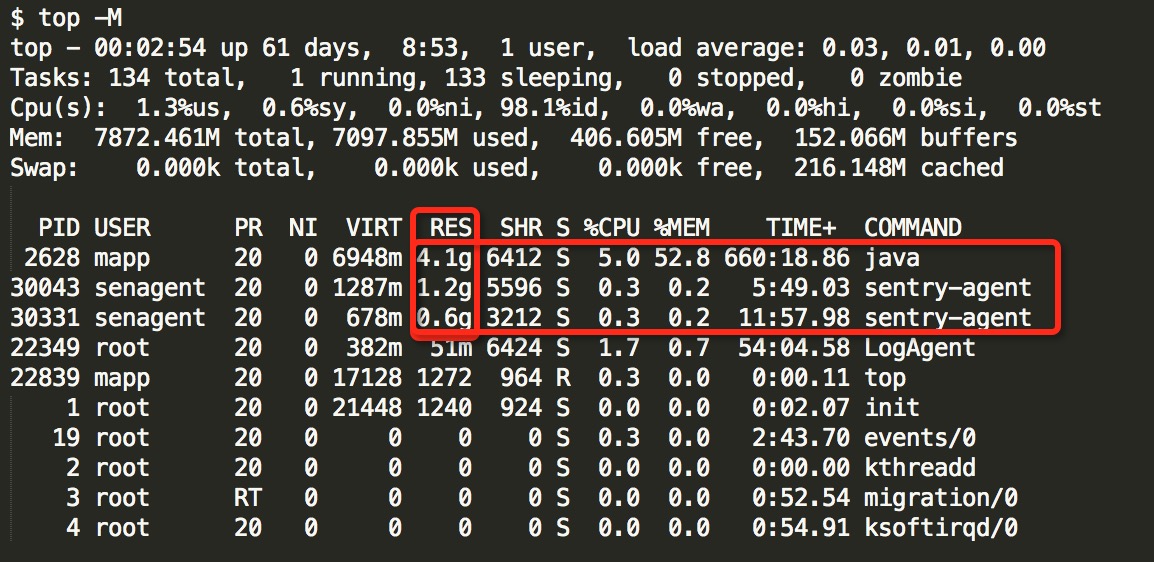
top 命令的 VIRT 字段表示虚拟内存,而 RES 字段才表示实际的使用内存。从上图(数据是事后伪造的,因为没保存当时现场,但量级和当时事故现场差不多)可以很清晰地看到,java 进程占用了 4.1g 内存,和 JVM 配置一样;两个 sentry-agent 进程尽然分别占用了 1.6GB 和 1.2GB(好吓人)。
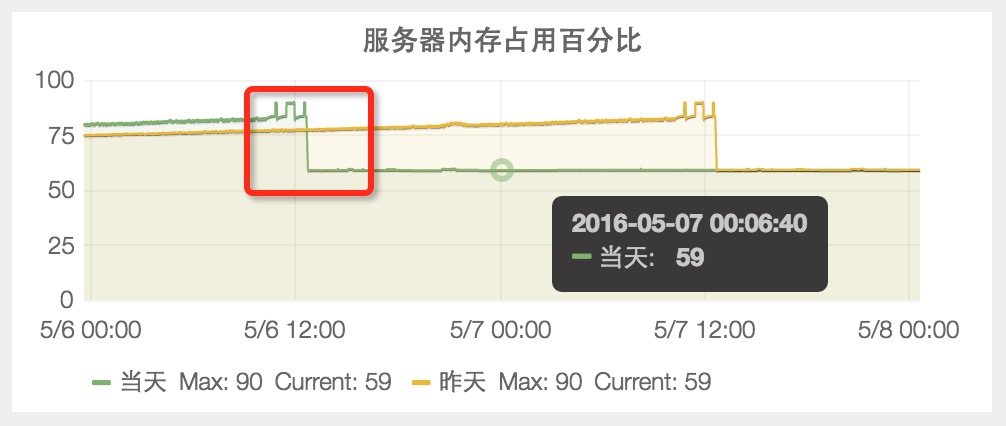
sentry-agent 是一个收集日志的客户端,为什么会占用这么多的内存呢?向负责该服务的开发同学反馈,证实确实有问题,他们好像也发现问题了,他们答应当天下午修复问题。凭直觉,问题应该就出现在这里了。先让运维同学重启了 sentry-agent 进程,内存占用百分比一下子就降到了 59%,说明此问题的大部分原因是这里引起的。此数据与4月15日吻合,但与最开始的48%数据还有差距,这个还需要进一步排查。因为从 GC 来看,自身应用程序没发现内存泄漏问题,需要深入探究一下。
上述4台机器,前面2台使用 Docker 虚拟化,后面2台使用 KVM 虚拟化。内存占用百分比相差10+个点(相差 900+MB),注意是由于 slabs 消耗不一样引起的(参考@褚霸的文章)。
KVM 虚拟化:
$ echo `cat /proc/slabinfo |awk 'BEGIN{sum=0;}{sum=sum+$3*$4;}END{print sum/1024/1024}'` MB
139.037 MB
Docker 虚拟化:
$ echo `cat /proc/slabinfo |awk 'BEGIN{sum=0;}{sum=sum+$3*$4;}END{print sum/1024/1024}'` MB
1177.34 MB
问题解决前后,“内存占用百分比”对比图:
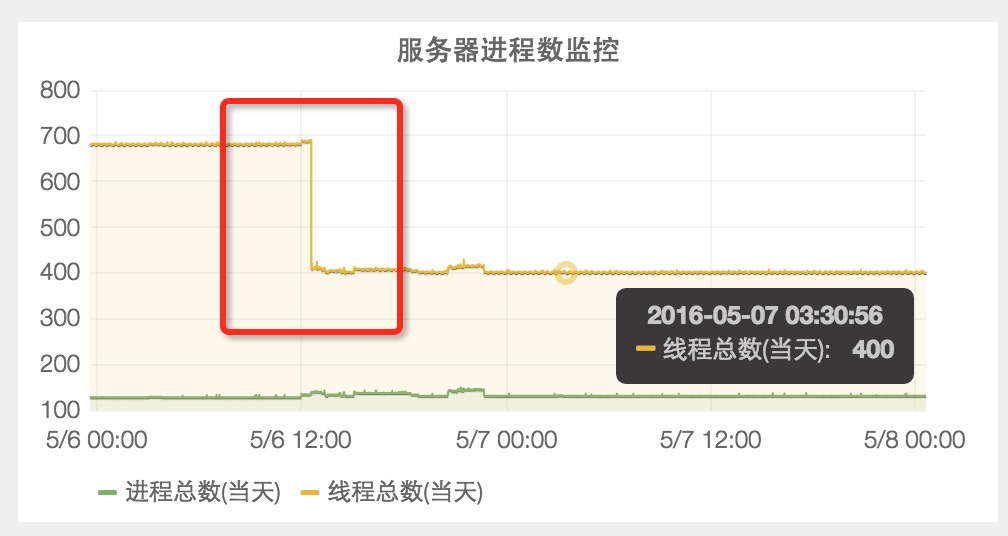
看了其他监控指标,发现“服务器线程总数”从680下降到400,说明 sentry-agent 存在线程泄漏问题。
至此,本问题算是解决了大部分,线上服务器内存暴涨问题得到了解决。(在群里反馈,其他服务先前就已经出现了此问题,但一直没有去排查,我也是醉啦,就不担心出现 OOM 吗?就不担心整个服务都不可用吗?这个问题解决得到 Leader 的赞还是很开心滴)
写文章确实花很多时间和精力,但回顾问题整个处理过程并反思处理思路,还是有很多地方可以改进(不懂时就上网查资料,了解清楚),收获颇多。(感谢每一个问题!)
搜索引擎是我们最靠谱的老师与朋友 [碰拳]
祝大家玩得开心!
这篇关于[线上问题] 线上服务器内存使用量已达到90%报警(内存泄漏)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









