本文主要是介绍java--LinkedHashSet集合的底层原理和TreeSet集合,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.LinkedHashSet底层原理
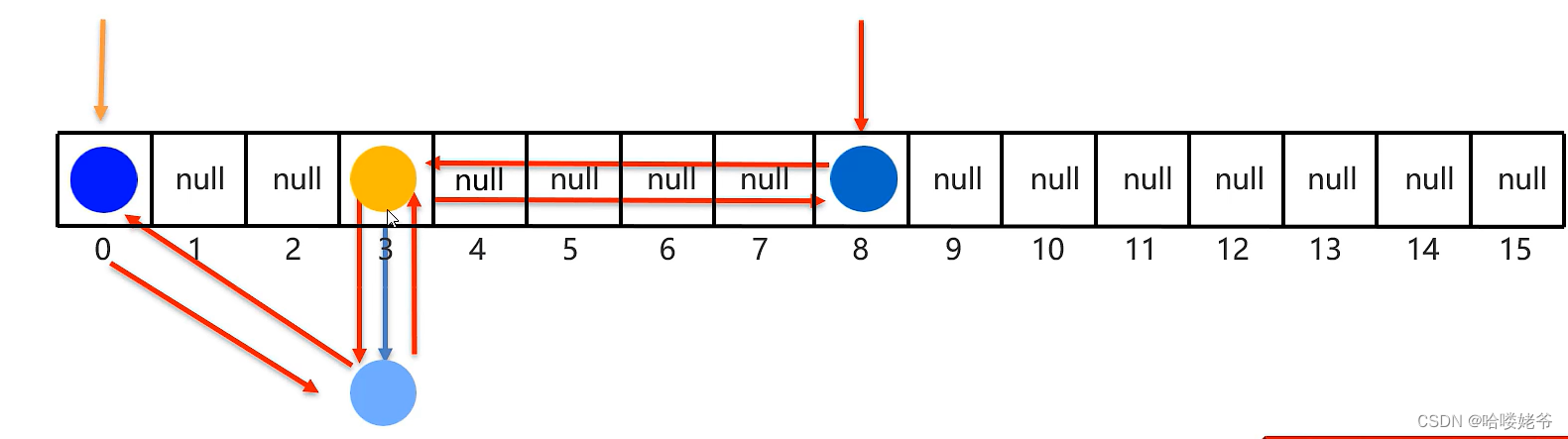
①依然是基于哈希表(数组、链表、红黑树)实现的
②但是,它的每个元素都额外的多了一个双链表的机制记录它前后元素的位置。
2.TreeSet
①特点:不重复、无索引、可排序(默认升序排序,按照元素的大小,由小到大排序)
②底层是基于红黑树实现的排序。
3.注意
①对于数值类型:Integer,Double,默认按照数值本身的大小进行升序排序。
②对于字符串类型:默认按照首字符的编号升序排序。
③对于自定义类型如Student对象,TreeSet默认是无法直接排序的。
4.自定义排序规则
①TreeSet集合存储自定义类型的对象时,必须指定排序规则,支持如下两种方式来指定比较规则。
方式一:
让自定义的类(如学生类)实现Comparable接口,重写里面的compareTo方法来指定比较规则。
方式二:
通过调用TreeSet集合有参数构造器,可以设置Comparator对象(比较器对象,用于指定比较规则)

5.两种方式中,关于返回值的规则
①如果认为第一个元素>第二个元素返回正整数即可。
②如果认为第一个元素<第二个元素返回负整数即可。
③如果认为第一个元素=第二个元素返回0即可,此时TreeSet集合只会保留一个元素,认为两者重复。
注意:如果类本身有实现Comparable接口,TreeSet集合同时也自带比较器,默认使用集合自带的比较器排序。
这篇关于java--LinkedHashSet集合的底层原理和TreeSet集合的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




