本文主要是介绍R语言读数据做图,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
今天给大家带来的是如何用R语言读数据并作图
- 数据如下,需要你复制黏贴到记事本中,并在R工作目录下保存为txt格式,命名为“123.txt”。
指标 2014年 2013年 2012年 2011年 2010年
各项税收(亿元) 119158.05 110530.70 100614.28 89738.39 73210.79
国内增值税(亿元) 30849.78 28810.13 26415.51 24266.63 21093.48
营业税(亿元) 17781.62 17233.02 15747.64 13679.00 11157.91
国内消费税(亿元) 8906.82 8231.32 7875.58 6936.21 6071.55
关税(亿元) 2843.19 2630.61 2783.93 2559.12 2027.83
个人所得税(亿元) 7376.57 6531.53 5820.28 6054.11 4837.27
企业所得税(亿元) 24632.49 22427.20 19654.53 16769.64 12843.54
- 看代码:
par(mfrow=c(1,2),cex=0.5)
data=read.table("123.txt",header=T)
data2014=data$X2014年
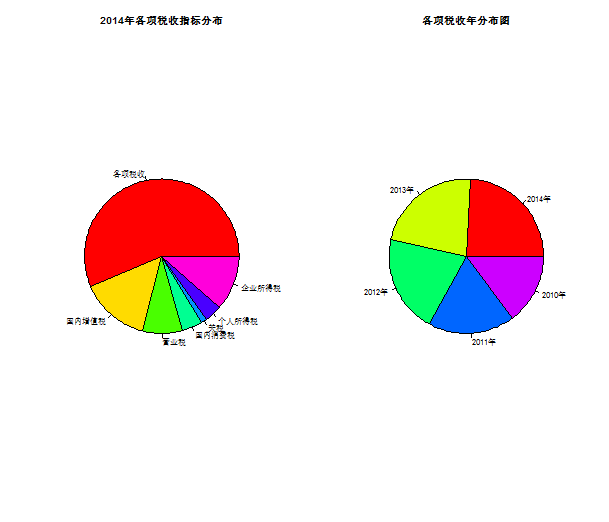
data2014_items=c("各项税收","国内增值税","营业税","国内消费税","关税","个人所得税","企业所得税")
pie(data2014,labels=data2014_items,col=rainbow(length(data2014_items)),main="2014年各项税收指标分布")
data_pertax=data[1,2:6]
data_pertax_years=c("2014年","2013年","2012年","2011年","2010年")
pie(as.numeric(data_pertax),labels=data_pertax_years,col=rainbow(length(data_pertax_years)),main="各项税收年分布图")
#barplot(data2014,col=col,horiz=T)这一条自己查帮助,添加你需要的东西。结果如下:
不难发现读数据的一般格式为(读表和记事本):
x=read.csv("GDP增长率.csv")
y <- x[13,2:23]
m=seq(2007,1986)
plot(m,y)
lines(m,y)x<-read.table("statisticians.txt")温馨提示:记住,数据要放到工作目录下才能读哦!获取和设置工作目录的指令为getwd()和setwd(‘E:\R工作目录’)。
这篇关于R语言读数据做图的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



