本文主要是介绍Elaticsearch 学习笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- Elaticsearch 学习笔记
- 一、什么是 Elaticsearch ?
- 二、Elaticsearch 安装
- 1 es 安装
- 2 问题解决
- 3 数据格式
- 三、索引操作
- 1 PUT 请求:在postman中,向 ES 服务器发 PUT 请求(PUT请求相当于创建的意思)
- 2 GET 请求:GET 请求是获取的意思,获取指定的索引
- 3 GET 请求获取全部索引
- 4 DELETE:删除索引
- 四、文档操作
- 1 POST请求创建文档
- 2 GET请求查询文档
- 3 GET请求条件查询
- 4 GET请求分页查询
- 5 GET请求查询后排序
- 6 GET多条件查询
- 7 GET范围查询
- 8 PUT请求修改文档-全部覆盖:在请求体内贴入需修改的数据
- 9 DELETE请求删除文档
- 10 全文检索与部分检索:match_phrase & match
- 11 检索结果高亮显示
- 12 聚合查询-平均值
- 五、Java API 操作
- 1 创建maven项目,添加依赖
- 2 索引创建
- 3 索引查看
- 4 索引删除
- 5 向索引新增元素
- 6 在索引中修改元素
- 7 在索引中查看元素
- 8 在索引中删除元素
- 9 在索引中批量新增元素
- 10 在索引中批量删除元素
- 11 高级查询-全量查询:QueryBuilders.matchAllQuery()
- 12 高级查询-条件查询:QueryBuilders.termQuery()
- 13 高级查询-分页查询:builder.from(x);builder.size(y)
- 14 高级查询-查询排序:builder.sort()
- 15 高级查询-排除/包含字段:builder.sort()
- 16 高级查询-组合查询
- 1 组合查询-类似于and
- 2 组合查询-类似于or
- 3 组合查询-范围查询
- 17 高级查询-模糊查询
- 六、es 集群搭建
- 1 windows集群
- 2 linux集群
- 七、es 进阶
- 1 核心概念
- 1.1 索引(Index)
- 1.2 类型(Type)
- 1.3 文档(Document)
- 1.4 字段(Field)
- 1.5 映射(Mapping)
- 1.6 分片(Shards)
- 1.7 副本(Replicas)
- 1.8 分配(Allocation)
- 2 单节点集群
Elaticsearch 学习笔记
一、什么是 Elaticsearch ?
Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。作为 ElasticStack 的核心,它集中存储您的数据,帮助您发现意料之中以及意料之外的情况。
The Elastic Stack,包括 Elasticsearch、Kibana、Beats 和 Logstash (也称为 ELK Stack)能够安全可靠地获取任何来源、任何格式的数据,然后实时地对数据进行搜索、分析和可视化。Elaticsearch,简称为ES,ES 是一个开源的高扩展的分布式全文搜索引擎,是整个 ElasticStack 技术栈的核心。它可以近乎实时的存储、检索数据:本身扩展性很好,可以扩展到上百台服务器,处理 PB 级别的数据。
二、Elaticsearch 安装
1 es 安装
Elaticsearch 官网地址:https://www.elastic.co/cn/
由于我的环境是 windows 环境,因此下载 windows 安装包即可。
下载完windows 安装包后,直接解压即可:

注意:9300端口为 es 集群间通信的端口,9200为浏览器访问的 http 协议 的restful 端口。
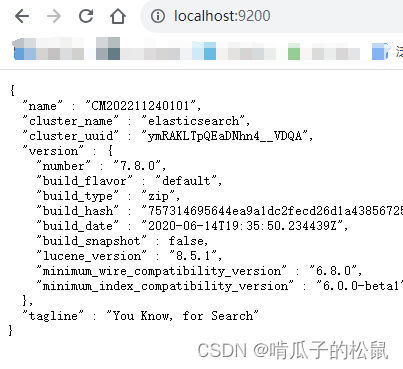
启动后浏览器访问:
http://localhost:9200/
出现以下页面则成功启动:
2 问题解决
-
es 是使用 java 开发的,且 7.8 版本的 es 需要jdk 1.8以上,默认安装包带有 jdk 环境,如果系统配置 JAVA HOME,那么使用系统默认的 jdk,如果没有配置使用自带的 jdk,一般建议使用系统配置的 jdk。
-
双击启动窗口闪退,通过路径访问追踪错误,如果是“空间不足”,请修改 config/jvm.options 配置文件:
# 设置 JVM 初始内存为1G。此值可以设置与-Xmx 相同,以避免每次垃圾回收完成后 JVM 重新分配内存 # Xms represents the initial size of total heap space # 设置 JVM 最大可用内存为 1G # Xmx represents the maximum size of total heap space -Xms1g -Xmx1g
3 数据格式
Elasticsearch 是面向文档型数据库,一条数据在这里就是一个文档。为了方便理解,我们将 Elasticsearch 里存储文档数据和关系型数据库 MySQL 存储数据的概念进行一个类比
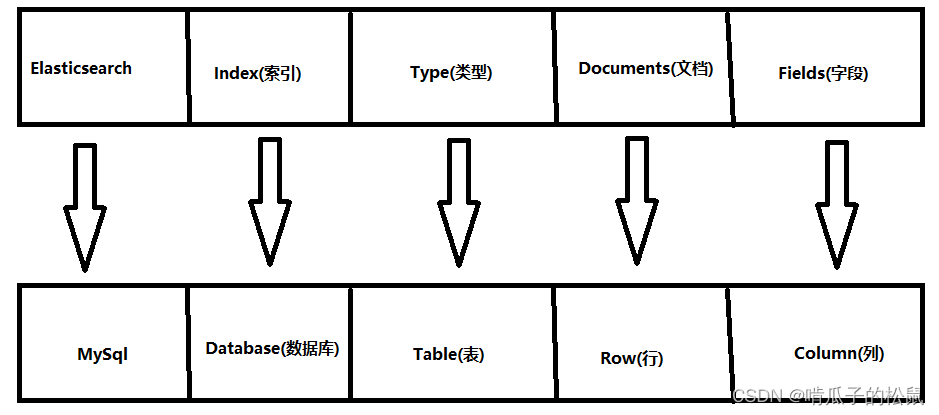
ES 里的 Index 可以看作一个库,而 Types 相当于表,Documents 则相当于表的行。
三、索引操作
对比关系型数据库,创建索引就等同于创建数据库。
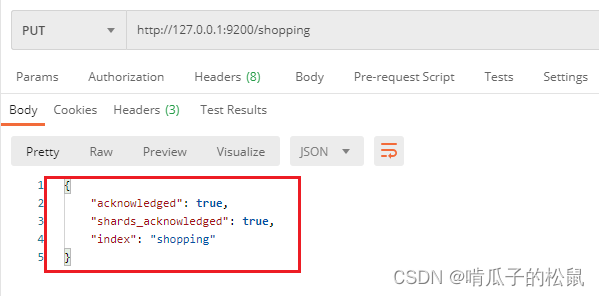
1 PUT 请求:在postman中,向 ES 服务器发 PUT 请求(PUT请求相当于创建的意思)
http://127.0.0.1:9200/shopping
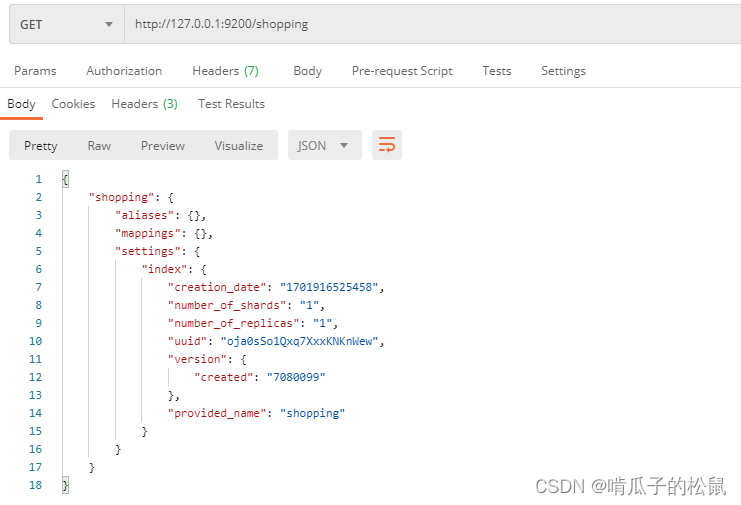
2 GET 请求:GET 请求是获取的意思,获取指定的索引
http://127.0.0.1:9200/shopping
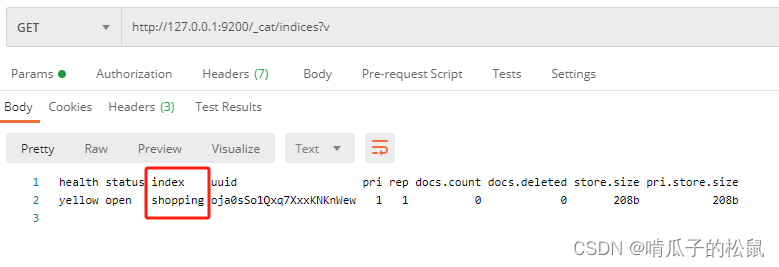
3 GET 请求获取全部索引
http://127.0.0.1:9200/_cat/indices?v
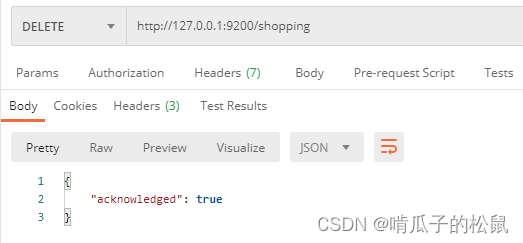
4 DELETE:删除索引
http://127.0.0.1:9200/shopping
四、文档操作
1 POST请求创建文档
http://127.0.0.1:9200/shopping/_doc
{"title": "小米手机","category": "小米","images": "https://ts1.cn.mm.bing.net/th?id=OIP-C.NelZaFZYimRWyjjIrjd-QQHaGM&w=273&h=228&c=8&rs=1&qlt=90&o=6&pid=3.1&rm=2","price": 3999.00
}

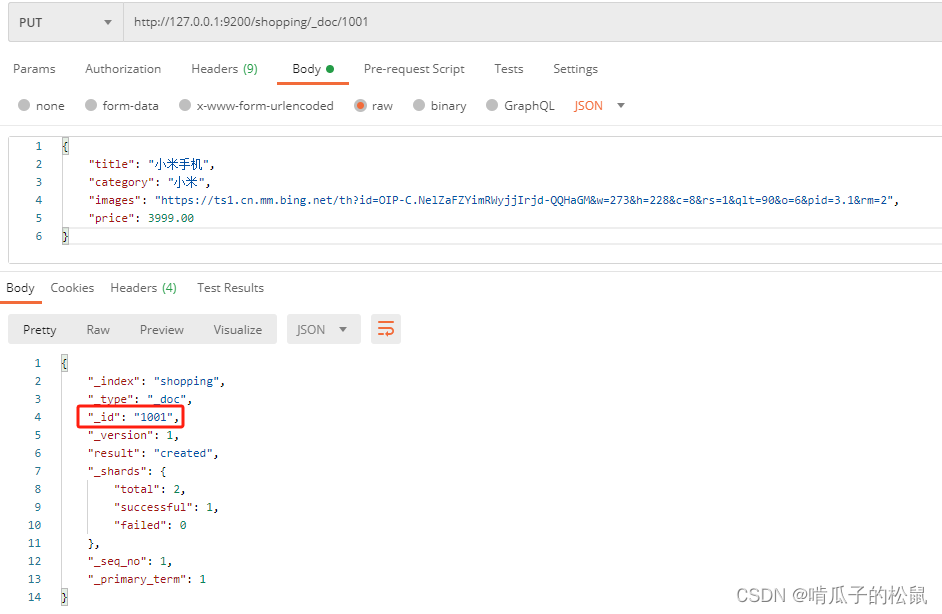
这里的id是随机生成的,也可以采用put请求直接传入id:
http://127.0.0.1:9200/shopping/_doc/1001
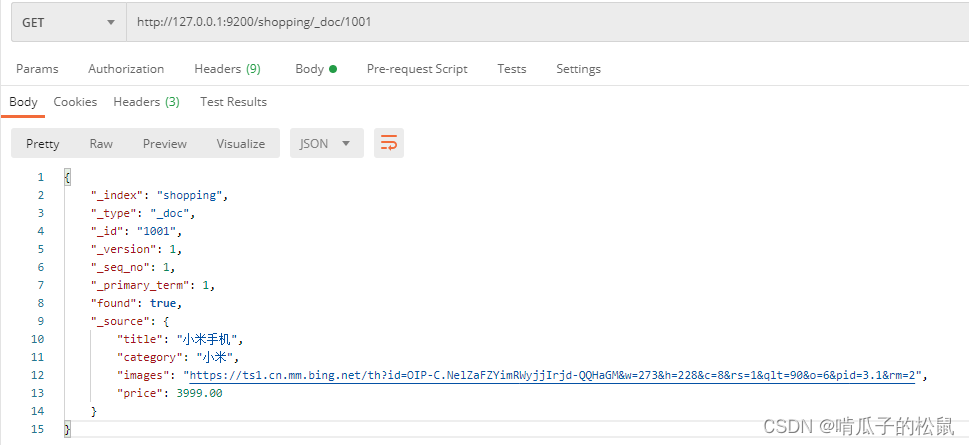
2 GET请求查询文档
如果只查询某个指定的id,则在路径中直接指定即可:
// 在路径中指定id
http://127.0.0.1:9200/shopping/_doc/1001
如果要查询全部:
// 指定index并且使用_search
http://127.0.0.1:9200/shopping/_search
3 GET请求条件查询
http://127.0.0.1:9200/shopping/_search?q=category:小米
上述条件会查询出所有 category 字段为小米的元素。
直接在请求路径中拼接中文,很有可能会乱码,因此我们采用请求体查询:
http://127.0.0.1:9200/shopping/_search
{"query" : {"match": {"category" : "小米"}}
}
4 GET请求分页查询
在请求体中加入from和size即可。
http://127.0.0.1:9200/shopping/_search
{"query" : {"match": {"category" : "小米"}},"from": 0,"size": 2
}
5 GET请求查询后排序
http://127.0.0.1:9200/shopping/_search
{"query" : {"match": {"category" : "小米"}},"from": 0,"size": 2,"sort": {"price": {"order": "desc" // asc}}
}
6 GET多条件查询
http://127.0.0.1:9200/shopping/_search
{"query" : {"bool": {"must": [{"match": {"category": "小米"}}, // 多条件{"match": {"price": "4999.00"}} // 多条件]}},"from": 0,"size": 2,"sort": {"price": {"order": "desc" // asc}}
}
一个条件符合多值:
{"query" : {"bool": {"should": [ // 一个条件符合多值{"match": {"category": "小米"}}, // 多值{"match": {"category": "华为"}} // 多值]}},"from": 0,"size": 2,"sort": {"price": {"order": "desc" // asc}}
}
7 GET范围查询
http://127.0.0.1:9200/shopping/_search
{"query" : {"bool": {"must": [{"match": {"category": "小米"}}],"filter" :{"range": {"price": {"gt": 3000, // 大于3000 && 小于8000"lt": 8000}}}}},"from": 0,"size": 2,"sort": {"price": {"order": "desc" // asc}}
}
8 PUT请求修改文档-全部覆盖:在请求体内贴入需修改的数据
http://127.0.0.1:9200/shopping/_doc/1001
{"title": "小米手机","category": "小米","images": "https://ts1.cn.mm.bing.net/th?id=OIP-C.NelZaFZYimRWyjjIrjd-QQHaGM&w=273&h=228&c=8&rs=1&qlt=90&o=6&pid=3.1&rm=2","price": 4999.00
}
如果只修改指定的属性,则使用post请求:
http://127.0.0.1:9200/shopping/_update/1001
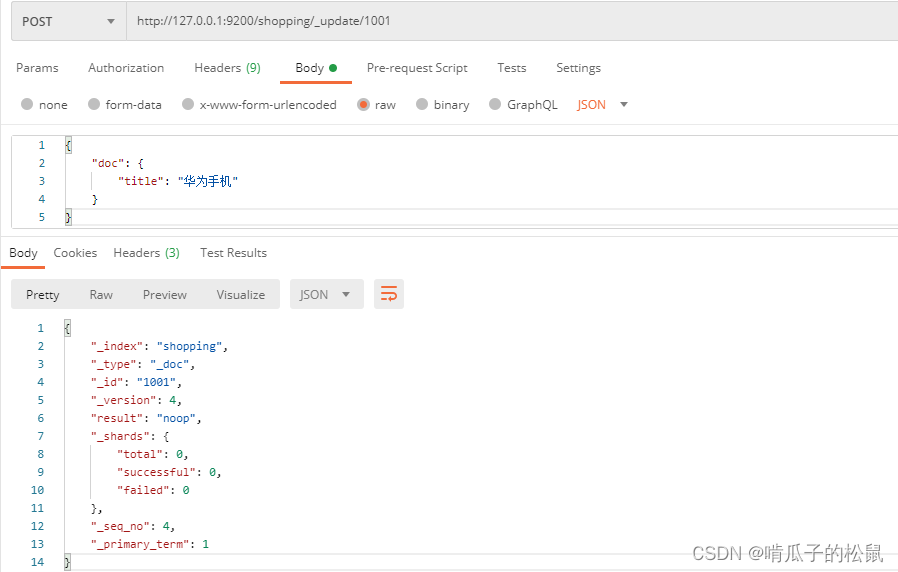
9 DELETE请求删除文档
http://127.0.0.1:9200/shopping/_doc/1001
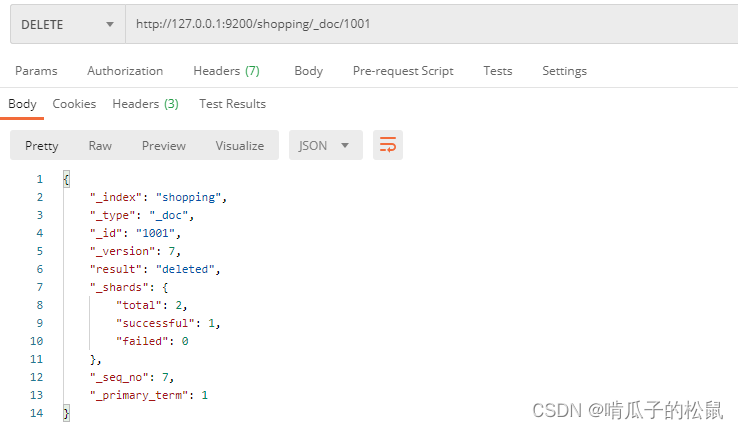
10 全文检索与部分检索:match_phrase & match
http://127.0.0.1:9200/shopping/_search
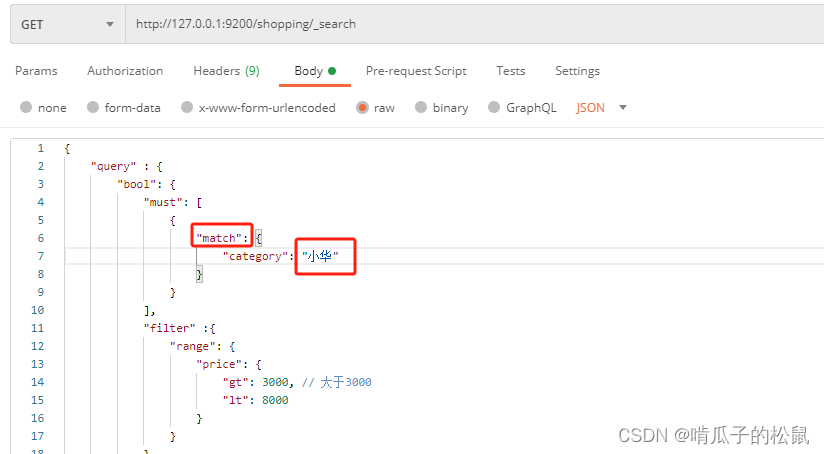
此处使用match是全文检索,es会把小华拆分成"小"、"华"两个字符单独匹配,因此查询结果会把字段category 包含"小"字、"华"字的元素都查询出来。
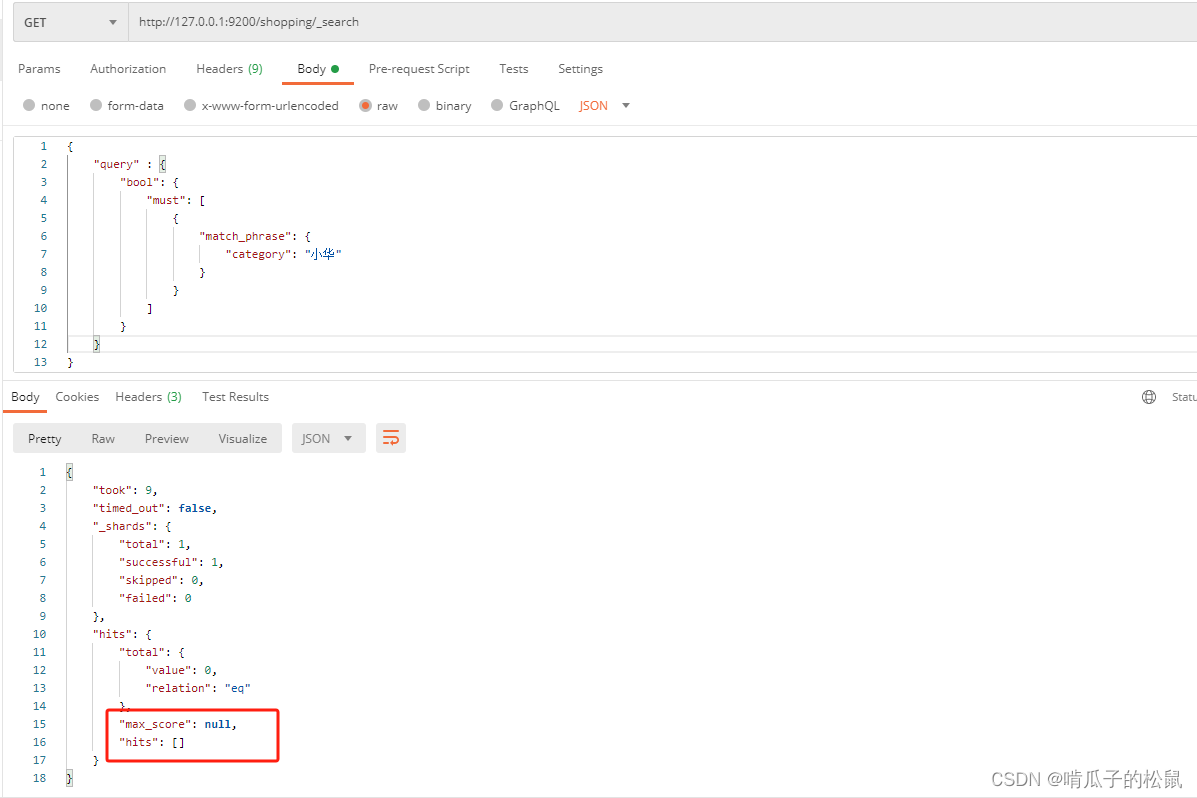
如果要实现完全匹配,则使用:match_phrase 。
{"query" : {"bool": {"must": [{"match_phrase": {"category": "小华"}}]}}
}
这时查询出来的结果集就是category 为小华的元素,如果没有,则是null。
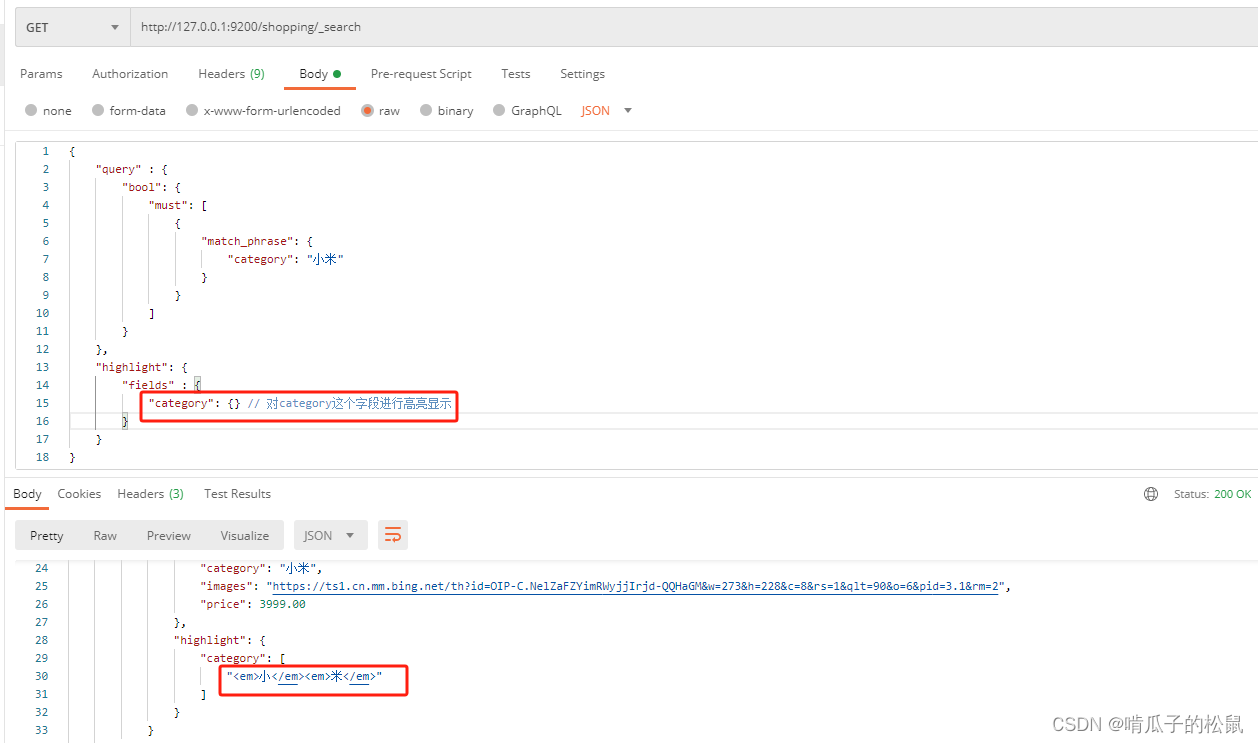
11 检索结果高亮显示
http://127.0.0.1:9200/shopping/_search
{"query" : {"bool": {"must": [{"match_phrase": {"category": "小米"}}]}},"highlight": {"fields" : {"category": {} // 对category这个字段进行高亮显示}}
}
12 聚合查询-平均值
http://127.0.0.1:9200/shopping/_search
聚合查询:
{ "aggs" : {"price_group【价格分组】": {"terms": {"field": "price"}}}
}
求平均值:
{ "aggs" : {"price_avg【价格平均值】": {"avg": {"field": "price"}}}
}
五、Java API 操作
Elasticsearch 软件是由Java 语言开发的,所以也可以通过 Java API 的方式对 Elasticsearch 服务进行访问。
1 创建maven项目,添加依赖
<!-- es 依赖 -->
<dependency><groupId>org.elasticsearch</groupId><artifactId>elasticsearch</artifactId><version>7.8.0</version>
</dependency><!-- es的客户端 -->
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.8.0</version>
</dependency>
创建客户端连接:
public class ESTestClient {public static void main(String[] args) {// 创建es客户端RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));// 关闭es客户端try {esClient.close();} catch (IOException e) {e.printStackTrace();}}
}
2 索引创建
public class ESTestCreatIndex {public static void main(String[] args) {// 创建es客户端RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));// 创建索引CreateIndexRequest user = new CreateIndexRequest("user"); // user: 索引名try {CreateIndexResponse createIndexResponse = esClient.indices().create(user, RequestOptions.DEFAULT);// 响应状态boolean acknowledged = createIndexResponse.isAcknowledged();System.out.println("索引操作:" + acknowledged);} catch (IOException e) {e.printStackTrace();}// 关闭es客户端try {esClient.close();} catch (IOException e) {e.printStackTrace();}}}
3 索引查看
public class ESTestCreatIndex {public static void main(String[] args) {// 创建es客户端RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));// 查询索引GetIndexRequest request = new GetIndexRequest("user"); // 获取user索引try {GetIndexResponse getIndexResponse = esClient.indices().get(request, RequestOptions.DEFAULT);System.out.println(getIndexResponse.getAliases());System.out.println(getIndexResponse.getMappings());System.out.println(getIndexResponse.getSettings());} catch (IOException e) {e.printStackTrace();}// 关闭es客户端try {esClient.close();} catch (IOException e) {e.printStackTrace();}}}
4 索引删除
public class ESTestDeleteIndex {public static void main(String[] args) {// 创建es客户端RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));// 删除索引DeleteIndexRequest request = new DeleteIndexRequest("user"); // 删除user索引try {AcknowledgedResponse deleteResponse = esClient.indices().delete(request, RequestOptions.DEFAULT);System.out.println(deleteResponse.isAcknowledged());} catch (IOException e) {e.printStackTrace();}// 关闭es客户端try {esClient.close();} catch (IOException e) {e.printStackTrace();}}}
5 向索引新增元素
public class ESTestDocInsert {public static void main(String[] args) {// 创建es客户端RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));// 插入数据IndexRequest request = new IndexRequest();request.index("user").id("1004");User user = new User();user.setName("张三");user.setAge(20);user.setSex("男");try {// 向es插入数据,必须将数据转换为json格式ObjectMapper objectMapper = new ObjectMapper();String userJson = objectMapper.writeValueAsString(user);request.source(userJson, XContentType.JSON);IndexResponse response = esClient.index(request, RequestOptions.DEFAULT);System.out.println(response.getResult());} catch (IOException e) {e.printStackTrace();}// 关闭es客户端try {esClient.close();} catch (IOException e) {e.printStackTrace();}}
}
6 在索引中修改元素
public class ESTestDocUpdate {public static void main(String[] args) {// 创建es客户端RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));// 更新数据UpdateRequest request = new UpdateRequest();request.index("user").id("1004"); // 传入索引和idrequest.doc(XContentType.JSON, "sex", "女"); // 把性别改为女try {UpdateResponse response = esClient.update(request, RequestOptions.DEFAULT);System.out.println(response.getResult());} catch (IOException e) {e.printStackTrace();}// 关闭es客户端try {esClient.close();} catch (IOException e) {e.printStackTrace();}}
}
7 在索引中查看元素
public class ESTestDocGet {public static void main(String[] args) {// 创建es客户端RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));// 查询数据GetRequest request = new GetRequest();request.index("user").id("1004"); // 传入索引和idtry {GetResponse response = esClient.get(request, RequestOptions.DEFAULT);System.out.println(response.getSourceAsString());} catch (IOException e) {e.printStackTrace();}// 关闭es客户端try {esClient.close();} catch (IOException e) {e.printStackTrace();}}
}
8 在索引中删除元素
public class ESTestDocDelete {public static void main(String[] args) {// 创建es客户端RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));// 删除数据DeleteRequest request = new DeleteRequest();request.index("user").id("1004"); // 传入索引和idtry {DeleteResponse response = esClient.delete(request, RequestOptions.DEFAULT);System.out.println(response.getResult());} catch (IOException e) {e.printStackTrace();}// 关闭es客户端try {esClient.close();} catch (IOException e) {e.printStackTrace();}}
}
9 在索引中批量新增元素
public static void main(String[] args) {// 创建es客户端RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));// 批量插入数据BulkRequest request = new BulkRequest();for (int i = 0; i < 3; i++) {IndexRequest indexRequest = new IndexRequest("user").id("1001" + i).source(XContentType.JSON, "name", "张三" + i);request.add(indexRequest);}try {BulkResponse response = esClient.bulk(request, RequestOptions.DEFAULT);System.out.println(response.getTook()); // 花费的时间System.out.println(response.getItems()); // 多个响应} catch (IOException e) {e.printStackTrace();}// 关闭es客户端try {esClient.close();} catch (IOException e) {e.printStackTrace();}}
10 在索引中批量删除元素
public static void main(String[] args) {// 创建es客户端RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));// 批量删除数据BulkRequest request = new BulkRequest();for (int i = 0; i < 3; i++) {DeleteRequest indexRequest = new DeleteRequest("user").id("1001" + i);request.add(indexRequest);}try {BulkResponse response = esClient.bulk(request, RequestOptions.DEFAULT);System.out.println(response.getTook()); // 花费的时间System.out.println(response.getItems()); // 多个响应} catch (IOException e) {e.printStackTrace();}// 关闭es客户端try {esClient.close();} catch (IOException e) {e.printStackTrace();}}
11 高级查询-全量查询:QueryBuilders.matchAllQuery()
public static void main(String[] args) {// 创建es客户端RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));// 高级查询-全量查询SearchRequest request = new SearchRequest();request.indices("user");request.source(new SearchSourceBuilder().query(QueryBuilders.matchAllQuery()));try {SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);System.out.println(response.getHits().getTotalHits()); // 获取user索引中元素的个数System.out.println(response.getTook()); // 获取时间for (SearchHit hit : response.getHits()) {System.out.println(hit.getSourceAsString()); // 按字符串打印元素的全部属性System.out.println(hit); // 一个元素的全部数据 json 格式System.out.println(hit.getId()); // 打印id}} catch (IOException e) {e.printStackTrace();}// 关闭es客户端try {esClient.close();} catch (IOException e) {e.printStackTrace();}}
12 高级查询-条件查询:QueryBuilders.termQuery()
public static void main(String[] args) {// 创建es客户端RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));// 高级查询-全量查询SearchRequest request = new SearchRequest();request.indices("user");request.source(new SearchSourceBuilder().query(QueryBuilders.termQuery("age", 22))); // 把年龄为22岁的查询出来try {SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);System.out.println(response.getHits().getTotalHits()); // 获取user索引中元素的个数System.out.println(response.getTook()); // 获取时间for (SearchHit hit : response.getHits()) {System.out.println(hit.getSourceAsString()); // 按字符串打印元素的全部属性System.out.println(hit); // 一个元素的全部数据 json 格式System.out.println(hit.getId()); // 打印id}} catch (IOException e) {e.printStackTrace();}// 关闭es客户端try {esClient.close();} catch (IOException e) {e.printStackTrace();}}
13 高级查询-分页查询:builder.from(x);builder.size(y)
public static void main(String[] args) {// 创建es客户端RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));// 查询数据SearchRequest request = new SearchRequest();request.indices("user");SearchSourceBuilder builder = new SearchSourceBuilder().query(QueryBuilders.matchAllQuery());builder.from(0); // 从第几条数据开始builder.size(3); // 每页查询3条数据request.source(builder);try {SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);System.out.println(response.getHits().getTotalHits()); // 获取user索引中元素的个数System.out.println(response.getTook()); // 获取时间for (SearchHit hit : response.getHits()) {System.out.println(hit.getSourceAsString()); // 只打印name}} catch (IOException e) {e.printStackTrace();}// 关闭es客户端try {esClient.close();} catch (IOException e) {e.printStackTrace();}}
14 高级查询-查询排序:builder.sort()
public static void main(String[] args) {// 创建es客户端RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));// 查询数据SearchRequest request = new SearchRequest();request.indices("user");SearchSourceBuilder builder = new SearchSourceBuilder().query(QueryBuilders.matchAllQuery());builder.sort("age", SortOrder.DESC); // SortOrder.ASCrequest.source(builder);try {SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);System.out.println(response.getHits().getTotalHits()); // 获取user索引中元素的个数System.out.println(response.getTook()); // 获取时间for (SearchHit hit : response.getHits()) {System.out.println(hit.getSourceAsString()); // 只打印name}} catch (IOException e) {e.printStackTrace();}// 关闭es客户端try {esClient.close();} catch (IOException e) {e.printStackTrace();}}
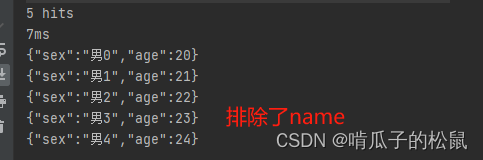
15 高级查询-排除/包含字段:builder.sort()
public static void main(String[] args) {// 创建es客户端RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));// 查询数据SearchRequest request = new SearchRequest();request.indices("user");SearchSourceBuilder builder = new SearchSourceBuilder().query(QueryBuilders.matchAllQuery());String[] excludes = {"name"}; // 排除某个字段String[] includes = {}; // 包含某个字段builder.fetchSource(includes, excludes); // SortOrder.ASCrequest.source(builder);try {SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);System.out.println(response.getHits().getTotalHits()); // 获取user索引中元素的个数System.out.println(response.getTook()); // 获取时间for (SearchHit hit : response.getHits()) {System.out.println(hit.getSourceAsString()); // 只打印name}} catch (IOException e) {e.printStackTrace();}// 关闭es客户端try {esClient.close();} catch (IOException e) {e.printStackTrace();}}
16 高级查询-组合查询
1 组合查询-类似于and
public static void main(String[] args) {// 创建es客户端RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));// 查询数据SearchRequest request = new SearchRequest();request.indices("user");SearchSourceBuilder builder = new SearchSourceBuilder();BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();boolQueryBuilder.must(QueryBuilders.matchQuery("age", 24)); // age必须是25boolQueryBuilder.mustNot(QueryBuilders.matchQuery("sex", "男")); // sex必须不能是男builder.query(boolQueryBuilder);request.source();try {SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);System.out.println(response.getHits().getTotalHits()); // 获取user索引中元素的个数System.out.println(response.getTook()); // 获取时间for (SearchHit hit : response.getHits()) {System.out.println(hit.getSourceAsString()); // 只打印name}} catch (IOException e) {e.printStackTrace();}// 关闭es客户端try {esClient.close();} catch (IOException e) {e.printStackTrace();}}
2 组合查询-类似于or
public static void main(String[] args) {// 创建es客户端RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));// 查询数据SearchRequest request = new SearchRequest();request.indices("user");SearchSourceBuilder builder = new SearchSourceBuilder();BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();queryBuilder.should(QueryBuilders.matchQuery("age",20)); // 年龄20-21的都可以查出queryBuilder.should(QueryBuilders.matchQuery("age",21));builder.query(boolQueryBuilder);request.source();try {SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);System.out.println(response.getHits().getTotalHits()); // 获取user索引中元素的个数System.out.println(response.getTook()); // 获取时间for (SearchHit hit : response.getHits()) {System.out.println(hit.getSourceAsString()); // 只打印name}} catch (IOException e) {e.printStackTrace();}// 关闭es客户端try {esClient.close();} catch (IOException e) {e.printStackTrace();}}
3 组合查询-范围查询
public static void main(String[] args) {// 创建es客户端RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));// 查询数据SearchRequest request = new SearchRequest();request.indices("user");SearchSourceBuilder builder = new SearchSourceBuilder();RangeQueryBuilder rangeQueryBuilder = QueryBuilders.rangeQuery("age"); // 范围查询的字段rangeQueryBuilder.gte(20); // 大于等于20 && 小于等于40rangeQueryBuilder.lte(40);builder.query(rangeQueryBuilder);request.source(builder);try {SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);System.out.println(response.getHits().getTotalHits()); // 获取user索引中元素的个数for (SearchHit hit : response.getHits()) {System.out.println(hit.getSourceAsString()); // 以字符串形式打印}} catch (IOException e) {e.printStackTrace();}// 关闭es客户端try {esClient.close();} catch (IOException e) {e.printStackTrace();}
}
17 高级查询-模糊查询
public static void main(String[] args) {// 创建es客户端RestHighLevelClient esClient = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));// 查询数据SearchRequest request = new SearchRequest();request.indices("user");SearchSourceBuilder builder = new SearchSourceBuilder();FuzzyQueryBuilder fuzziness = QueryBuilders.fuzzyQuery("name", "zhangsan").fuzziness(Fuzziness.TWO);builder.query(fuzziness);request.source(builder);try {SearchResponse response = esClient.search(request, RequestOptions.DEFAULT);System.out.println(response.getHits().getTotalHits()); // 获取user索引中元素的个数for (SearchHit hit : response.getHits()) {System.out.println(hit.getSourceAsString()); // 以字符串形式打印}} catch (IOException e) {e.printStackTrace();}// 关闭es客户端try {esClient.close();} catch (IOException e) {e.printStackTrace();}
}
QueryBuilders.fuzzyQuery(“name”, “zhangsan”) // zhangsan表示要模糊匹配的字段名
.fuzziness(Fuzziness.TWO); // TWO表示和匹配的字段名相差2个字符也能匹配到
六、es 集群搭建
1 windows集群
2 linux集群
此处暂时先略过,后期补充。
七、es 进阶
1 核心概念
1.1 索引(Index)
一个索引就是一个拥有几分相似特征的文档的集合。比如,我们可以新建一个客户数据的索引,产品目录的索引,订单数据的索引。一个索引必须全部都是小写字母,并且我们要对这个索引中的文档进行索引、搜索、更新、删除时,都要使用到这个索引。能搜索的数据必须索引,这样的好处是可以提高查询速度,比如:书本的目录就是索引的意思。
1.2 类型(Type)
在一个索引中,可以定义一种或多种类型,一个类型就是索引的一个逻辑上的分类/分区,其语义完全由我们来定,通查,会为具有一组共同字段的文档定义一个类型。
1.3 文档(Document)
一个文档通俗的说就是一条数据,类似于 mysql 关系型数据库的一行数据,文档通常以 json 数据来表示。在一个 index 或者 type 里面,我们可以存储任意多的文档。
1.4 字段(Field)
相当于是 mysql 数据表的字段,对文档数据根据不同属性进行的分类标识。
1.5 映射(Mapping)
Mapping 在处理数据的方式和规则方面做一些限制,如:某个字段的数据类型、默认值、是否被索引等等。这些在映射里面都可以设置,还有在 es 里面数据的一些使用规则设置也叫做映射,按着最优规则处理数据对性能提高很大,因此才需要简历映射,并且需要思考如何建立映射才能对性能更好。
1.6 分片(Shards)
一个索引可以存储超出单个节点硬件限制的大量数据。比如,一个具有 10 亿文档数据的索引占据 1 TB 的磁盘空间,而任一节点都可能没有这样大的磁盘空间,或者单个节点处理搜索请求,响应太慢。为了解决这个问题,es 提供了将索引分成多份的能力,每一份都称之为分片。当我们创建一个索引的时候,我们可以指定想要的分片数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。
分片很重要,主要有两方面的原因:
- 允许水平分割 / 扩展你的内存容量。
- 允许在分片之上进行分布式的、并行的操作,进而提高性能 / 吞吐量。
1.7 副本(Replicas)
在一个网络 / 云的环境里,失败随时都可能发生,在某个分片 / 节点不知怎么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elastisearch 允许创建分片的一份或多份拷贝,这些拷贝叫做复制分片(副本)。
复制分片之所以重要,有两个主要原因:
- 在分片 / 节点失败的情况下,提供了高可用性。因为这个原因,注意到复制分片从不与原 / 主要分片置于同一节点上是非常重要的。
- 扩展你的搜索量 / 吞吐量,因为搜索可以在所有的副本上并行运行。
1.8 分配(Allocation)
将分片分配给某个节点的过程,包括分配主分片或者副本。如果是副本,还包含从主分片复制数据的过程。这个过程是由 master 节点完成的。
2 单节点集群
整个集群中只有一个节点就叫单节点集群。在一个空节点的集群内创建名为 users 的索引,为了演示,分配 3个主分片和一份副本。
// put请求
http://127.0.0.1:9200/users
请求体:
{"settings" : {"number_of_shards" : 3,"number_of_replicas" : 1}
}
elasticserach-head 插件查看集群情况。
地址:https://github.com/mobz/elasticsearch-head
进入上述地址,下载 crx 目录下的:es-head.crx。然后开始添加到谷歌浏览器的扩展程序。
- 1、先将 crx 重命名为:elasticsearch-head.zip (没错,直接修改后缀名);
- 2、将 elasticsearch-head.zip 解压成文件夹;
- 3、打开谷歌浏览器扩展程序,点击(加载已解压的扩展程序)按钮,选择解压的文件夹即可。
- 4、如图,点击:

- 5、出现以下画面,则安装成功:

这篇关于Elaticsearch 学习笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








