本文主要是介绍gh-ost详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、简介
gh-ost是MySQL的无触发器在线DDL。它是可测试的,并提供可暂停性、动态控制/重新配置、审计和许多操作特权。DDL时master会生成少量工作负载,与迁移表上的现有工作负载分离。详细内容请看github
二、工作原理
1.ghost 迁移:
- 在服务器上创建ghost表,与要执行的DDL表结构一致
- 在ghost表上进行DDL变更
- 连接MySQL伪装为replica,流式传输binary log events
- 可交互的操作
- 在ghost表上应用events
- 将原始表中的行复制到ghost table上
- cut-over(切换表)
2.首选设置
- 连接到从库
- 检测副本上的表结构,表大小
- 连接到从库伪装成从库的从库
- 应用所有变更到主库上
- 心跳检测事件写到主库上

3.要求
- gh-ost 当前需要 MySQL 版本 5.7 及更高版本。
- row格式且为FULL row image的binlog
- 表级别权限:ALTER, CREATE, DELETE, DROP, INDEX, INSERT, LOCK TABLES, SELECT, TRIGGER, UPDATE
- 全局权限:SUPER, REPLICATION SLAVE,REPLICATION CLIENT
4.限制
- 不支持外键约束。 他们将来可能会在某种程度上得到支持。
- 不支持触发器。 他们将来可能会得到支持。
- 支持 MySQL 5.7 JSON 列,但不作为 PRIMARY KEY 的一部分
- 前后两个表必须共享主键或其他唯一键。 复制时 gh-ost 将使用此键来迭代表行
- 迁移键不得包含具有 NULL 值的列,作为键的字段类型可以为null,但值不能为null
- 默认情况下,如果唯一的 UNIQUE KEY 包含可为空的列,则 gh-ost 将不会运行。可以通过 --allow-nullable-unique-key 覆盖它,但请确保这些列中没有实际的 NULL 值。 现有的 NULL 值不能保证迁移表上的数据完整性。
- 不允许迁移一个库中的同名表(大小写不同但名字相同,如abc,Abc)
- Amazon RDS 可以工作,但有其自身的局限性。
- Google Cloud SQL 可以工作,需要 --gcp 标志。
- Aliyun RDS 可以工作,需要 --aliyun-rds 标志。
- Azure Database for MySQL 可以工作,需要 --azure 标志,并且有关于它的详细文档。 (azure.md)
- 通过副本迁移时不支持多源。 直接连接到 master 时它应该可以工作(但从未测试过)(–allow-on-master)
- 双主架构仅支持单写模式
- 如果您将枚举字段作为迁移键(通常是主键)的一部分,迁移性能将会降低并且可能会很糟糕。
- 迁移 FEDERATED 表不受支持,并且与 gh-ost 解决的问题无关。
- 不支持加密的二进制日志
- 不支持 ALTER TABLE … RENAME TO some_other_name (并且您不应该使用 gh-ost 进行此类简单操作)。
5.cut-over
MySQL 对表交换的发生方式设置了一些限制。 虽然它支持原子交换,但它不允许连接到其锁定的交换表。
- FB(facebook OSC) : 寻找“切换阶段”。 Facebook 解决方案使用非原子交换:首先重命名原始表并将其推到一边,然后重命名幽灵表以取代其位置。 在两次重命名之间,有一段短暂的时间,这个短暂的时间表不存在,所以会导致查询失败。
- gh-ost 通过使用原子的两步阻塞交换来解决这个问题:当一个连接持有锁时,另一个连接尝试原子 RENAME。 通过放置一个哨兵表来保证 RENAME 不会过早执行,该哨兵表会阻止 RENAME 操作,直到 gh-ost 满足所有要求为止。
- 成功执行,在这种情况下,表会自动交换,挂起的连接会被阻塞一段时间,继续对新迁移的表进行操作
- 或者由于某些连接超时或死亡而失败,在这种情况下,我们自然会返回到预切换阶段,其中原始表仍然存在并且可以访问。 这会释放挂起的连接,这些连接能够再次写入表,然后 gh-ost 能够再次尝试切换。
如果指定 --cut-over,则默认为上述原子切换算法。 还支持 --cut-over=two-step,它使用 FB 非原子算法
三、多种变更模式
gh-ost 的运行方式是连接到可能的多个服务器,并将自身强加为副本,以便直接从其中一台服务器流式获取binary log events。 有多种操作模式,具体取决于您的设置、配置以及要运行迁移的位置。如下图所示
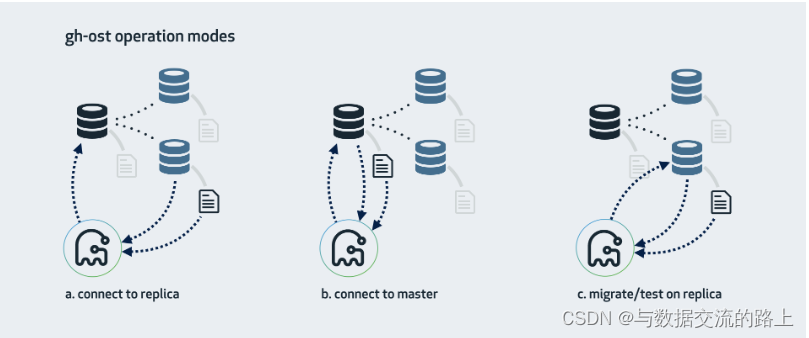
1.连接到replica,在master上迁移
这是 gh-ost 默认期望的模式。 gh-ost 将调查副本,找到拓扑的主节点,并且也会链接到master上。
1.1 变更流程
- 在master上读取和写入行数据
- 读取从库上的binary logs events ,将变更应用到master上
- 记录从库上的表格式、字段和主键,索引,行数
- 从副本读取内部变更日志事件(例如心跳)
- 主站上的切换(切换表)
1.2 限制
从库必须开启row格式的binary log,必须开启log_slave_updates参数
1.3 示例
gh-ost \
--max-load=Threads_running=25 \
--critical-load=Threads_running=1000 \
--chunk-size=1000 \
--throttle-control-replicas="myreplica.1.com,myreplica.2.com" \
--max-lag-millis=1500 \
--user="gh-ost" \
--password="123456" \
--host=replica.with.rbr.com \
--database="my_schema" \
--table="my_table" \
--verbose \
--alter="engine=innodb" \
--switch-to-rbr \
--allow-master-master \
--cut-over=default \
--exact-rowcount \
--concurrent-rowcount \
--default-retries=120 \
--panic-flag-file=/tmp/ghost.panic.flag \
--postpone-cut-over-flag-file=/tmp/ghost.postpone.flag \
[--execute] # 指定了--execute才会实际运行复制数据和切换表的操作
2.连接到master
如果没有从库,或者不想使用它们,仍然可以直接在master上进行操作。 gh-ost 将直接在 master 上执行所有操作。 需要考虑复制延迟的情况
2.1 限制
- master必须开启row格式的binlog
- 必须指定–allow-on-master参数
2.2 示例
gh-ost \
--max-load=Threads_running=25 \
--critical-load=Threads_running=1000 \
--chunk-size=1000 \
--throttle-control-replicas="myreplica.1.com,myreplica.2.com" \
--max-lag-millis=1500 \
--user="gh-ost" \
--password="123456" \
--host=master.with.rbr.com \
--allow-on-master \
--database="my_schema" \
--table="my_table" \
--verbose \
--alter="engine=innodb" \
--switch-to-rbr \
--allow-master-master \
--cut-over=default \
--exact-rowcount \
--concurrent-rowcount \
--default-retries=120 \
--panic-flag-file=/tmp/ghost.panic.flag \
--postpone-cut-over-flag-file=/tmp/ghost.postpone.flag \
[--execute]
3.在从库上进行测试
这将在从库上执行迁移。 gh-ost 将短暂连接到master,但随后将在从库执行所有操作,而不修改master上的任何内容。 在整个操作过程中,gh-ost 将进行限制,以使从库保持最新。
3.1 参数指定
- --migrate-on-replica 向 gh-ost 指示它必须直接在从库上迁移表。 即使复制正在运行,它也会执行切换阶段。
- --test-on-replica 表示迁移仅用于测试目的。 在进行切换之前,复制会停止。 表被交换,然后又交换回来:原来的表返回到原来的位置。 两个表都停止复制。 您可以检查两者并比较数据。
3.2 示例
gh-ost \--user="gh-ost" \--password="123456" \--host=replica.with.rbr.com \--test-on-replica \--database="my_schema" \--table="my_table" \--verbose \--alter="engine=innodb" \--initially-drop-ghost-table \--initially-drop-old-table \--max-load=Threads_running=30 \--switch-to-rbr \--chunk-size=500 \--cut-over=default \--exact-rowcount \--concurrent-rowcount \--serve-socket-file=/tmp/gh-ost.test.sock \--panic-flag-file=/tmp/gh-ost.panic.flag \--execute
4.其他配置
4.1 配置文件
用--conf=/path/to/config/file.cnf替代用户名密码的配置
[client]
user=gh-ost
password=123456
4.2 特殊配置
4.2.1 双主复制
双主单写的架构,目前不支持双主双写架构
gh-ost --allow-master-master
# ghost会选择其中的一个master进行操作,当然你也可以指定master
gh-ost --allow-master-master --assume-master-host=a.specific.master.com
4.2.2 Tungsten复制
tungsten 复制是一种第三方复制,所以类似一个单独的程序,并不能通过常规查看主从拓扑的方式查到,这对这种可以选择在主库执行变更,如果连接到从库则需要开启tungsten的og-slave-updates。另外 --switch-to-rbr 不适用于 Tungsten 设置,因为复制过程是外部的,因此您需要确保在 Tungsten Replicator 连接到服务器并开始应用来自主服务器的事件之前将 binlog_format 设置为 ROW
gh-ost --tungsten --assume-master-host=the.topology.master.com
4.3 并发变更
- 不要处理同一张表
- 如果在不同的从库上运行(例如,replica1 上的 table1,replica2 上的 table2),则无需进一步配置。
- 如果从同一服务器运行(二进制文件在同一服务器上运行,无论使用哪个副本)
- 确保不要指定相同的 --serve-socket-file (或让 gh-ost 为您选择一个)
- 您可以选择使用相同的 --throttle-flag-file (最好使用 --throttle-additional-flag-file,有两个的原因,后一个文件用于共享)。
- 您可以选择使用相同的 --panic-flag-file。 这一切都取决于您的流程以及您希望如何控制迁移。
- 如果使用相同的检查框(master或slave,–host=everyone.uses.this.host),那么对于每个 gh-ost 进程,您还必须提供不同的、唯一的 --replica-server-id。 可以选择使用进程 ID(shell 中的 $$); 但你需要选择一个不会与另一个 gh-ost 或另一个正在运行的副本发生冲突的数字。
四、交互式命令
gh-ost 被设计为易于操作。 为此,它允许用户即使在运行时也可以控制其行为。
- Unix socket文件:通过 --serve-socket-file提供或由gh-ost确定,该接口始终处于运行状态。 当自行确定时,gh-ost 将在启动时和整个迁移过程中通告套接字文件的标识。
- TCP:如果提供了 --serve-tcp-port
两个接口可以同时服务。 两者都响应
1.命令详解
help:显示可用命令的简要列表
status:返回迁移进度和配置的详细状态摘要
sup:返回迁移进度的简要状态摘要
coordinates:返回被检查服务器的最新(尽管不完全是最新的)二进制日志坐标
applier:返回应用程序的主机名
inspector:返回检查器的主机名
chunk-size=<newsize>:修改chunk-size; 适用于下一次运行的复制迭代
dml-batch-size=<newsize>:修改dml-batch-size; 适用于下次应用二进制日志事件
max-lag-millis=<max-lag>:修改最大复制滞后阈值(毫秒,最小值为100,即0.1秒)
max-load=<max-load-thresholds>:修改最大负载配置; 适用于下一次运行的复制迭代格式必须为:some_status=<numeric-threshold>[,some_status=<numeric-threshold>...]例如:Threads_running=50,threads_connected=1000,然后您将写入/echo max-load=Threads_running=50,threads_connected=1000 到套接字。
critical-load=<critical-load-thresholds>: 修改关键负载配置(超过这些阈值将中止操作)格式必须为:some_status=<numeric-threshold>[,some_status=<numeric-threshold>...]例如:Threads_running=1000,threads_connected=5000,然后您将写入/echo critical-load=Threads_running=1000,threads_connected=5000 到套接字。
nice-ratio=<ratio>: 更改执行频率,范围为0到任何正整数,假如复制一行数据需要1ms,nice-ratio=0.5,那么久需要额外sleep 0.5*1ms
throttle-http:更改节流HTTP 端点
throttle-query:更改节流查询
throttle-control-replicas='replica1,replica2': 更改限制控制副本列表,这些是gh-ost将检查的副本。这需要一个逗号分隔的副本列表来检查并替换之前的列表。
throttle:强制暂停迁移
no-throttle:取消强制暂停(尽管其他限制原因可能仍然适用)
unpostpone:在gh-ost推迟切换阶段时,gh-ost指示停止推迟并立即进行切换。
panic:紧急中止操作
2.使用示例
$ echo status | nc -U /tmp/gh-ost.test.sample_data_0.sock
# Migrating `test`.`sample_data_0`; Ghost table is `test`.`_sample_data_0_gst`
# Migration started at Tue Jun 07 11:45:16 +0200 2016
# chunk-size: 200; max lag: 1500ms; dml-batch-size: 10; max-load: map[Threads_connected:20]
# Throttle additional flag file: /tmp/gh-ost.throttle
# Serving on unix socket: /tmp/gh-ost.test.sample_data_0.sock
# Serving on TCP port: 10001
Copy: 0/2915 0.0%; Applied: 0; Backlog: 0/100; Elapsed: 40s(copy), 41s(total); streamer: mysql-bin.000550:49942; ETA: throttled, flag-file$ echo status | nc -U /tmp/gh-ost.test.sample_data_0.sock
# Migrating `test`.`sample_data_0`; Ghost table is `test`.`_sample_data_0_gst`
# Migration started at Tue Jun 07 11:45:16 +0200 2016
# chunk-size: 200; max lag: 1500ms; dml-batch-size: 10; max-load: map[Threads_connected:20]
# Throttle additional flag file: /tmp/gh-ost.throttle
# Serving on unix socket: /tmp/gh-ost.test.sample_data_0.sock
# Serving on TCP port: 10001
Copy: 0/2915 0.0%; Applied: 0; Backlog: 0/100; Elapsed: 40s(copy), 41s(total); streamer: mysql-bin.000550:49942; ETA: throttled, flag-file# 对于接受参数作为值的命令,传递 ? (问号)获取当前值而不是设置新值
$ echo "chunk-size=?" | nc -U /tmp/gh-ost.test.sample_data_0.sock
250$ echo throttle | nc -U /tmp/gh-ost.test.sample_data_0.sock$ echo status | nc -U /tmp/gh-ost.test.sample_data_0.sock
# Migrating `test`.`sample_data_0`; Ghost table is `test`.`_sample_data_0_gst`
# Migration started at Tue Jun 07 11:56:03 +0200 2016
# chunk-size: 250; max lag: 1500ms; max-load: map[Threads_connected:20]
# Throttle additional flag file: /tmp/gh-ost.throttle
# Serving on unix socket: /tmp/gh-ost.test.sample_data_0.sock
# Serving on TCP port: 10001
Copy: 0/2915 0.0%; Applied: 0; Backlog: 0/100; Elapsed: 59s(copy), 59s(total); streamer: mysql-bin.000551:68067; ETA: throttled, commanded by user这篇关于gh-ost详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






