笔记参考地址:https://morvanzhou.github.io/tutorials/machine-learning/ML-intro/
机器学习方法
1.1 机器学习
通常来说, 机器学习的方法包括:
- 监督学习 supervised learning:(有数据有标签)在学习过程中,不断的向计算机提供数据和这些数据对应的值,如给出猫、狗的图片并告诉计算机哪些是猫哪些是狗,让计算机去学习分辨
- 非监督学习 unsupervised learning:(有数据无标签)例给猫和狗的图片,不告诉计算机哪些是猫哪些是狗,而让它自己去判断和分类。不提供数据所对应的标签信息,计算机通过观察数据间特性总结规律
- 半监督学习 semi-supervised learning:综合监督和非监督,考虑如何利用少量有标签的样本和大量没标签的样本进行训练和分类
- 强化学习 reinforcement learning:把计算机丢到一个完全陌生的环境,或让它完成一项未接触过的任务,它自己会尝试各种手段,最后让自己成功适应,或学会完成任务的方法途径
- 遗传算法 genetic algorithm:通过淘汰机制设计最优的模型
神经网络
2.1 科普: 人工神经网络 VS 生物神经网络
人工神经网络靠的是正向和反向传播来更新神经元, 从而形成一个好的神经系统, 本质上, 这是一个能让计算机处理和优化的数学模型. 而生物神经网络是通过刺激, 产生新的联结, 让信号能够通过新的联结传递而形成反馈. 虽然现在的计算机技术越来越高超, 不过我们身体里的神经系统经过了数千万年的进化, 还是独一无二的, 迄今为止, 再复杂, 再庞大的人工神经网络系统也不能替代我们的小脑袋. 我们应该感到自豪, 也应该珍惜上天的这份礼物.
2.2 神经网络 (Neural Network)
讲述了一些神经网络的基础,输入层-隐藏层-输出层
2.3 卷积神经网络 CNN (Convolutional Neural Network)
卷积神经网络与普通神经网络的区别在于,卷积神经网络包含了一个由卷积层和子采样层构成的特征抽取器。在卷积神经网络的卷积层中,一个神经元只与部分邻层神经元连接。在CNN的一个卷积层中,通常包含若干个特征平面(featureMap),每个特征平面由一些矩形排列的的神经元组成,同一特征平面的神经元共享权值,这里共享的权值就是卷积核。卷积核一般以随机小数矩阵的形式初始化,在网络的训练过程中卷积核将学习得到合理的权值。共享权值(卷积核)带来的直接好处是减少网络各层之间的连接,同时又降低了过拟合的风险。子采样也叫做池化(pooling),通常有均值子采样(mean pooling)和最大值子采样(max pooling)两种形式。子采样可以看作一种特殊的卷积过程。卷积和子采样大大简化了模型复杂度,减少了模型的参数。
卷积神经网络包含输入层、隐藏层和输出层,隐藏层又包含卷积层和pooling层,图像输入到卷积神经网络后通过卷积来不断的提取特征,每提取一个特征就会增加一个feature map,所以会看到视频教程中的立方体不断的增加厚度,那么为什么厚度增加了但是却越来越瘦了呢,哈哈这就是pooling层的作用喽,pooling层也就是下采样,通常采用的是最大值pooling和平均值pooling,因为参数太多喽,所以通过pooling来稀疏参数,使我们的网络不至于太复杂
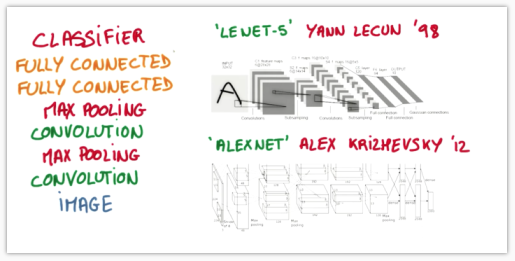
比较流行的一种搭建结构:
首先是输入的图片(image), 经过一层卷积层 (convolution), 然后在用池化(pooling)方式处理卷积的信息, 这里使用的是 max pooling 的方式. 然后在经过一次同样的处理, 把得到的第二次处理的信息传入两层全连接的神经层 (fully connected),这也是一般的两层神经网络层,最后在接上一个分类器(classifier)进行分类预测
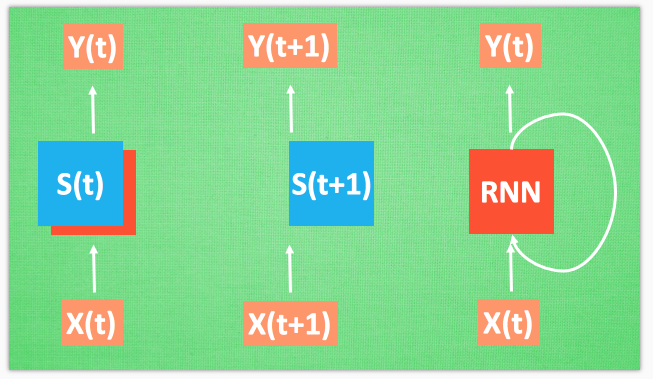
2.4 循环神经网络 RNN (Recurrent Neural Network)
每次 RNN 运算完之后都会产生一个对于当前状态的描述 , state. 我们用简写 S( t) 代替, 然后这个 RNN开始分析 x(t+1) , 他会根据 x(t+1)产生s(t+1), 不过此时 y(t+1) 是由 s(t) 和 s(t+1) 共同创造的. 所以我们通常看到的 RNN 也可以表达成这种样子
2.5 LSTM RNN 循环神经网络 (LSTM)
LSTM:long-short term memory 长短期记忆,是当下最流行的RNN形式之一。
沫凡举了一个红烧排骨的例子,设RNN中输入值为一句话“‘我今天要做红烧排骨, 首先要准备排骨, 然后…., 最后美味的一道菜就出锅了”。RNN分析今天做的什么,如果判断失误就要开始学习输入序列X和红烧排骨的关系,但红烧排骨出现的句首。
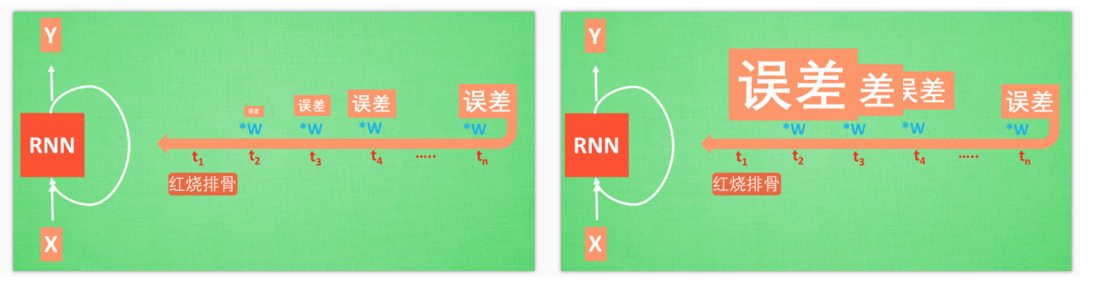
再来看看 RNN是怎样学习的吧. 红烧排骨这个信息原的记忆要进过长途跋涉才能抵达最后一个时间点. 然后我们得到误差, 而且在 反向传递 得到的误差的时候, 他在每一步都会 乘以一个自己的参数 W. 如果这个 W 是一个小于1 的数, 比如0.9. 这个0.9 不断乘以误差, 误差传到初始时间点也会是一个接近于零的数, 所以对于初始时刻, 误差相当于就消失了. 我们把这个问题叫做梯度消失或者梯度弥散 Gradient vanishing. 反之如果 W 是一个大于1 的数, 比如1.1 不断累乘, 则到最后变成了无穷大的数, RNN被这无穷大的数撑死了, 这种情况我们叫做剃度爆炸, Gradient exploding. 这就是普通 RNN 没有办法回忆起久远记忆的原因.
如下图左所示为LSTM的结构,比RNN多了输入控制、输出控制、忘记控制。

视频中的例子如上右图所示,LSTM多了对全局记忆的控制, 用粗线代替. 为方便理解, 把粗线想象成电影的主线剧情. 而原本的 RNN 体系就是分线剧情. 三个控制器都是在原始的 RNN 体系上, 我们先看输入方面 , 如果此时的分线剧情对于剧终结果十分重要, 输入控制就会将这个分线剧情按重要程度写入主线剧情 进行分析. 再看忘记方面, 如果此时的分线剧情更改了我们对之前剧情的想法, 那么忘记控制就会将之前的某些主线剧情忘记, 按比例替换成现在的新剧情. 所以主线剧情的更新就取决于输入和忘记 控制. 最后的输出方面, 输出控制会基于目前的主线剧情和分线剧情判断要输出的到底是什么.基于这些控制机制, LSTM 就像延缓记忆衰退的良药, 可以带来更好的结果.
2.6 自编码 (Autoencoder)
是一种神经网络的形式,能提取总结出数据的特征,类似于PCA主成分分析,即能给特征属性降维。
Autoencoder 简单来说就是将有很多Feature的数据进行压缩,之后再进行解压的过程。 本质上来说,它也是一个对数据的非监督学习,如果大家知道 PCA (Principal component analysis), 与 Autoencoder 相类似,它的主要功能即对数据进行非监督学习,并将压缩之后得到的“特征值”,这一中间结果正类似于PCA的结果。 之后再将压缩过的“特征值”进行解压,得到的最终结果与原始数据进行比较,对此进行非监督学习。
2.7 生成对抗网络 (GAN)
Generative Adversarial Nets

Generator 会根据随机数来生成有意义的数据 , Discriminator 会学习如何判断哪些是真实数据 , 哪些是生成数据, 然后将学习的经验反向传递给 Generator, 让 Generator 能根据随机数生成更像真实数据的数据. 这样训练出来的 Generator 可以有很多用途。
2.8 科普: 神经网络的黑盒不黑
神经网络可分区为 输入-黑盒-输出。黑盒所进行的操作可理解为对输入的特征进行加工,第一层加工后称为“代表特征”,下一层再对代表特征进行加工...这些特征往往只有计算机自己能看懂。与其说黑盒是在加工处理,不如说是在将一种代表特征转换成另一种代表特征。一次次特征之间的转换,也就是一次次的更有深度的理解。有时候代表特征太多了,人类没有办法看懂他们代表的是什么,然而计算机却能看清楚它所学到的规律,所以我们才觉得神经网络就是个黑盒。
2.9 神经网络 梯度下降
简单介绍了梯度下降方法,梯度下降法容易陷入局部解,在李宏毅《1天搞懂深度学习》笔记中也提到过。
2.10 迁移学习 Transfer Learning
已经训练好的模型上有可以借鉴的地方,可以去掉不需要用的层,在可用的基础上套上另外的神经网络,用这种移植的方式再进行训练,让它处理不同的问题。
神经网络技巧
3.1 检验神经网络 (Evaluation)
在神经网络的训练过程中,神经网络可能会存在着各种各样的问题,例如过拟合或者训练不够等等,所以需要进行检验。
3.2 特征标准化 (Feature Normalization)
当输入数据差别比较大的时候,在训练之间,先对数据预先处理:取值跨度大的特征数据, 我们浓缩一下, 跨度小的括展一下, 使得他们的跨度尽量统一。
通常用于特征标准化的途径有两种, 一种叫做 min max normalization, 它会将所有特征数据按比例缩放到0-1的这个取值区间. 有时也可以是-1到1的区间. 还有一种叫做 standard deviation normalization, 它会将所有特征数据缩放成平均值为0, 方差为1. 使用这些标准化手段. 我们不仅可以快速推进机器学习的学习速度, 还可以避免机器学习学得特扭曲。
3.3 选择好特征 (Good Features)
- 避免无意义的信息
- 避免重复性的信息
- 避免复杂的信息
3.4 激励函数 (Activation Function)
激励函数是为了解决日常生活中不能用线性方程所概括的问题。例如relu、sigmoid、tanh,将原有的线性方程变为非线性的。可自行创造激励函数,但需保证是可微分的,因为在backpropagation误差反向传递的时候,只有这些可微分的激励函数才能将误差传递回去。
当神经网络只有两三层的时候,激励函数的选用比较随意,但当层数较多的时候,不能随意选用激励函数,因为涉及到梯度爆炸、梯度消失的问题。
在CNN中推荐使用relu,RNN推荐tanh或relu。
3.5 过拟合 (Overfitting)
过拟合就是所谓的模型对可见的数据过度自信, 非常完美的拟合上了这些数据, 如果具备过拟合的能力, 那么这个方程就可能是一个比较复杂的非线性方程。
说白了,就是机器学习模型国过于自信。在李宏毅《1天搞懂深度学习》笔记中总结了几种方法。
在视频中也介绍了:
(1)增加数据量
(2)正则化
简化机器学习的关键公式为 y=Wx . W为机器需要学习到的各种参数. 在过拟合中, W 的值往往变化得特别大或特别小. 为了不让W变化太大, 我们在计算误差上做些手脚. 原始的 cost 误差是这样计算, cost = 预测值-真实值的平方. 如果 W 变得太大, 我们就让 cost 也跟着变大, 变成一种惩罚机制. 所以我们把 W 自己考虑进来. 这里 abs 是绝对值. 这一种形式的 正规化, 叫做 l1 正规化. L2 正规化和 l1 类似, 只是绝对值换成了平方. 其他的l3, l4 也都是换成了立方和4次方等等. 形式类似. 用这些方法,我们就能保证让学出来的线条不会过于扭曲.

(3)dropout
3.6 加速神经网络训练 (Speed Up Training)
- Stochastic Gradient Descent (SGD) :将数据分批处理
- Momentum:传统的权重参数ω的更新为ω=ω-η(∂L/∂ω),其中η为学习率,L为总损耗loss。Momentun更新方法为,ω=ω-η(∂L/∂ω)+Momentum
- AdaGrad:对学习率进行操作,每一个参数的学习率都不相同。
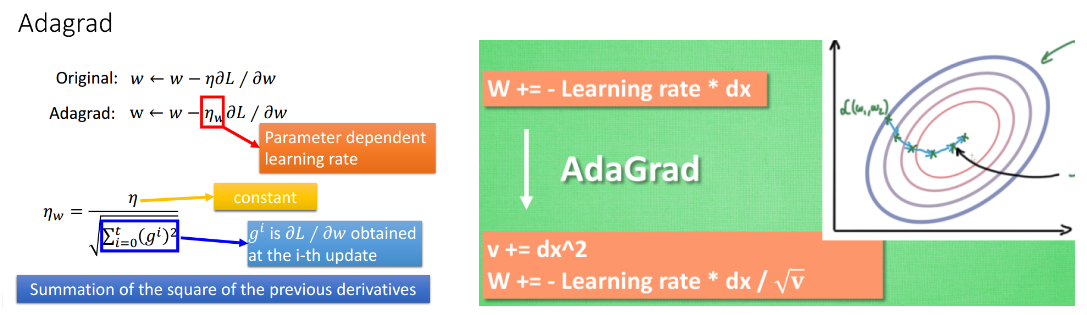
- RMSProp:结合AdaGrad和Momentum,但没有将Momentum完全合并,在Adam中补上了。

- Adam

3.7 处理不均衡数据 (Imbalanced data)
- 获取更多数据
- 更多评判方式:通常用准确率 accuracy, 或误差 cost来判断机器学习的成果。但在不均衡数据面前, 高的准确率和低的误差变得没那么重要. 所以我们得换一种方式评判。通过confusion matrix 来计算 precision 和 recall, 然后通过 precision 和 recall 再计算f1 分数。这种方式能成功地区分不均衡数据, 给出更好的评判分数。
- 重组数据,使之均衡
- 使用其他机器学习方法:如果使用的机器学习方法像神经网络等, 在面对不均衡数据时, 通常是束手无策. 不过有些机器学习方法, 像决策树, decision trees 就不会受到不均很数据的影响.
- 修改算法
3.8 批标准化 (Batch Normalization)
和普通的数据标准化类似, 是将分散的数据统一的一种做法, 也是优化神经网络的一种方法.具有统一规格的数据, 能让机器学习更容易学习到数据之中的规律.
Batch normalization 的 batch 是批数据, 把数据分成小批小批进行 stochastic gradient descent. 而且在每批数据进行前向传递 forward propagation 的时候, 对每一层都进行normalization的处理。
Batch normalization 也可以被看做一个层面. 在一层层的添加神经网络的时候, 我们先有数据 X, 再添加全连接层, 全连接层的计算结果会经过 激励函数 成为下一层的输入, 接着重复之前的操作. Batch Normalization (BN) 就被添加在每一个全连接和激励函数之间.
之前说过, 计算结果在进入激励函数前的值很重要, 如果我们不单单看一个值, 我们可以说, 计算结果值的分布对于激励函数很重要. 对于数据值大多分布在这个区间的数据, 才能进行更有效的传递. 对比这两个在激活之前的值的分布. 上者没有进行 normalization, 下者进行了 normalization, 这样当然是下者能够更有效地利用 tanh 进行非线性化的过程.
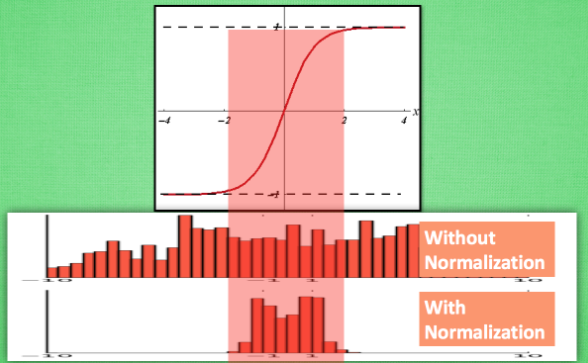
3.9 L1 / L2 正规化 (Regularization)
介绍了用来处理过拟合的方法之一。
强化学习
4.1 强化学习 (Reinforcement Learning)
是一类算法,让计算机“从无到有”,通过不断尝试,从错误中学习,最后找到规律,学会了达到目的的方法。
强化学习算法有:

4.2 强化学习方法汇总 (Reinforcement Learning)
介绍了强化学习的不同分类
-
Model-free 和 Model-based
-
基于概率和基于价值
-
回合更新和单步更新
- 在线学习和离线学习
4.3 Q Leaning
Q learning 决策
假设场景为正在写作业,用状态时s1表示,两个行为看电视a1和写作业a2,根据经验在s1状态下,a2带来的潜在奖励比较高。潜在奖励可用一个关于s和a的Q表格代替。如下所示:Q(s1,a1)< Q(s2,a2),所以判断a2为下一个行为,状态更新为s2,重复上述过程。在行为准则Q 表中寻找 Q(s2, a1) Q(s2, a2) 的值, 并比较他们的大小, 选取较大的一个. 接着根据 a2 我们到达 s3 并在此重复上面的决策过程. Q learning 的方法也就是这样决策的。
看完决策, 我看在来研究一下这张行为准则 Q 表是通过什么样的方式更改, 提升的.
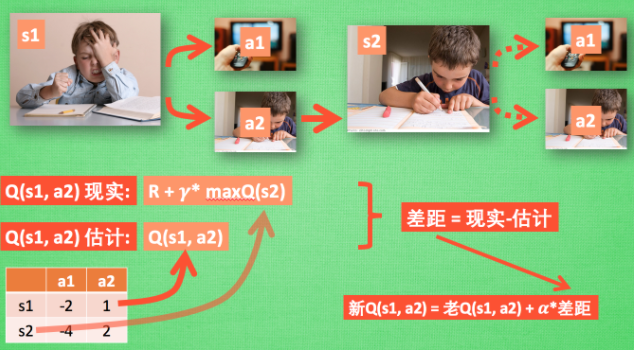
Q learning 更新
回到上述流程,根据Q表在s1状态时,因为a2的值大,采取了a2行为到达s2。此时开始更新用于决策的Q表,在实际中尚未采取行为,而是想象在s2上采取了每种行为,分别查看两种行为的Q值。设Q(s2, a2) >Q(s2, a1) , ∴把大的 Q(s2, a2) 乘上一个衰减值 gamma (比如是0.9) 并加上到达s2时所获取的奖励 R (这里还没有获取到我们的棒棒糖, 所以奖励为 0), 因为会获取实实在在的奖励 R , 我们将这个作为我现实中 Q(s1, a2) 的值, 但是我们之前是根据 Q 表估计 Q(s1, a2) 的值. 所以有了现实和估计值, 我们就能更新Q(s1, a2) , 根据 估计与现实的差距, 将这个差距乘以一个学习效率 alpha 累加上老的 Q(s1, a2) 的值 变成新的值. 但时刻记住, 我们虽然用 maxQ(s2) 估算了一下 s2 状态, 但还没有在 s2 做出任何的行为, s2 的行为决策要等到更新完了以后再重新另外做. 这就是 off-policy 的 Q learning 是如何决策和学习优化决策的过程.
Q learning 整体算法

每次更新我们都用到了 Q 现实和 Q 估计, 而且 Q learning 的迷人之处就是 在 Q(s1, a2) 现实 中, 也包含了一个 Q(s2) 的最大估计值, 将对下一步的衰减的最大估计和当前所得到的奖励当成这一步的现实。
最后我们来说说这套算法中一些参数的意义. Epsilon greedy 是用在决策上的一种策略, 比如 epsilon = 0.9 时, 就说明有90% 的情况我会按照 Q 表的最优值选择行为, 10% 的时间使用随机选行为. alpha是学习率, 来决定这次的误差有多少是要被学习的, alpha是一个小于1 的数. gamma 是对未来 reward 的衰减值。我们重写一下 Q(s1) 的公式, 将 Q(s2) 拆开, 因为Q(s2)可以像 Q(s1)一样,是关于Q(s3) 的, 所以可以写成这样, 然后以此类推, 不停地这样写下去, 最后就能写成这样, 可以看出Q(s1) 是有关于之后所有的奖励, 但这些奖励正在衰减, 离 s1 越远的状态衰减越严重.

4.4 Sarsa
Sarsa 的决策部分和 Q learning 一模一样, 因为我们使用的是 Q 表的形式决策, 所以我们会在 Q 表中挑选值较大的动作值施加在环境中来换取奖惩. 但是不同的地方在于 Sarsa 的更新方式是不一样的.
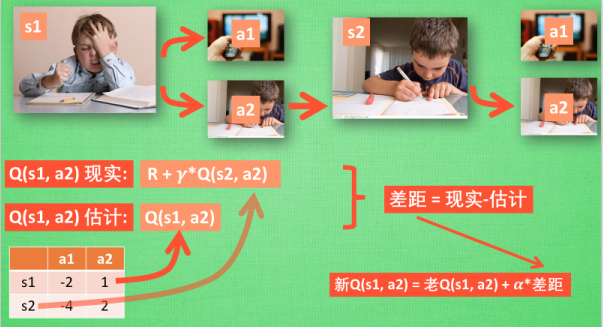
同样, 我们会经历正在写作业的状态 s1, 然后再挑选一个带来最大潜在奖励的动作 a2, 这样我们就到达了 继续写作业状态 s2, 而在这一步, 如果你用的是 Q learning, 你会观看一下在 s2 上选取哪一个动作会带来最大的奖励, 但是在真正要做决定时, 却不一定会选取到那个带来最大奖励的动作, Q-learning 在这一步只是估计了一下接下来的动作值. 而 Sarsa 是实践派, 他说到做到, 在 s2 这一步估算的动作也是接下来要做的动作. 所以 Q(s1, a2) 现实的计算值, 我们也会稍稍改动, 去掉maxQ, 取而代之的是在 s2 上我们实实在在选取的 a2 的 Q 值. 最后像 Q learning 一样, 求出现实和估计的差距 并更新 Q 表里的 Q(s1, a2).

从算法来看, 这就是他们两最大的不同之处了. 因为 Sarsa 是说到做到型, 所以我们也叫他 on-policy, 在线学习, 学着自己在做的事情. 而 Q learning 是说到但并不一定做到, 所以它也叫作 Off-policy, 离线学习.
4.5 Sarsa(lambda)
Sarsa 是一种单步更新法, 在环境中每走一步, 更新一次自己的行为准则, 我们可以在这样的 Sarsa 后面打一个括号, 说他是 Sarsa(0)。
lambda 值表示代替我们想要选择的步数。lambda 是脚步衰减值, 都是一个在 0 和 1 之间的数.
当 lambda 取0, 就变成了 Sarsa 的单步更新, 当 lambda 取 1, 就变成了回合更新, 对所有步更新的力度都是一样. 当 lambda 在 0 和 1 之间, 取值越大, 离宝藏越近的步更新力度越大. 这样我们就不用受限于单步更新的每次只能更新最近的一步, 我们可以更有效率的更新所有相关步了.
4.6 DQN
Deep Q Network:融合了神经网络和 Q learning
我们使用表格来存储每一个状态 state, 和在这个 state 每个行为 action 所拥有的 Q 值,但当状态太多时,如果全用表格存储,不仅占用内存还耗时。通过在神经网络中输入状态和动作,输出得到Q值,则无需记录。或直接输入状态,输出动作值。再按照Q learning来的原则,选用拥有最大值的动作当做下一步要做的动作。
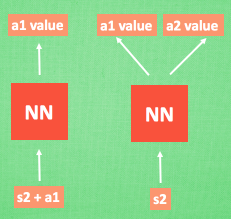
DQN两大利器:
- Experience replay:DQN 有一个记忆库用于学习之前的经历,每次DQN更新时,可随机抽取之前的一些经历进行学习,打乱了经历之间的相关性,也使得神经网络更新更有效率
- Fixed Q-targets:在DQN中使用到两个结构相同但参数不同的神经网络,预测Q估计的神经网络具备最新的参数,而预测Q显示的神经网络使用的参数是很久以前的
4.7 Policy Gradients
不同于Q learning这种基于值的方法,policy gradients不分析奖励值,直接输出行为。因此能在一个连续区间挑选动作。
通过奖惩机制来进行更新操作。
4.8 Actor Critic
合并了以值为基础 (比如 Q learning) 和以动作概率为基础 (比如 Policy Gradients) 两类强化学习算法
Actor-Critic 的 Actor 的前生是 Policy Gradients, 这能让它毫不费力地在连续动作中选取合适的动作, 而 Q-learning 做这件事会瘫痪. 那为什么不直接用 Policy Gradients 呢? 原来 Actor Critic 中的 Critic 的前生是 Q-learning 或者其他的以值为基础的学习法 , 能进行单步更新, 而传统的 Policy Gradients 则是回合更新, 这降低了学习效率.
Actor-Critic 涉及到了两个神经网络, 而且每次都是在连续状态中更新参数, 每次参数更新前后都存在相关性, 导致神经网络只能片面的看待问题, 甚至导致神经网络学不到东西. Google DeepMind 为了解决这个问题, 修改了 Actor Critic 的算法:
Actot Critic+DQN→Deep Deterministic Policy Gradient
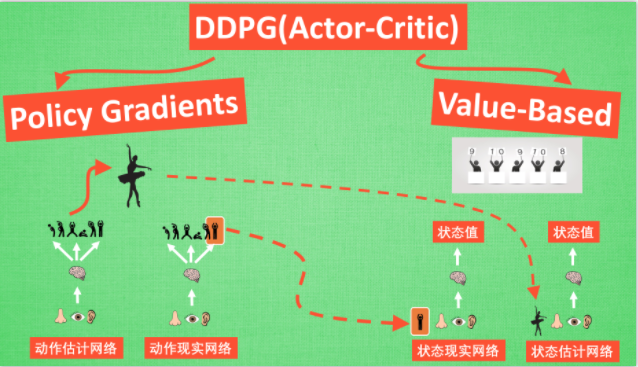
4.9 Deep Deterministic Policy Gradient (DDPG)
Deep:顾名思义, 就是走向更深层次, 在DQN 中使用一个记忆库和两套结构相同, 但参数更新频率不同的神经网络能有效促进学习. 那我们也把这种思想运用到 DDPG 当中, 使 DDPG 也具备这种优良形式. 但是 DDPG 的神经网络形式却比 DQN 的要复杂一点点.
Deterministic:改变了输出动作的过程, 斩钉截铁的只在连续动作上输出一个动作值.
DDPG神经网络:与 Actor-Critic 形式差不多, 也需要有基于 策略 Policy 的神经网络 和基于 价值 Value 的神经网络, 但是为了体现 DQN 的思想, 每种神经网络我们都需要再细分为两个, Policy Gradient 这边, 我们有估计网络和现实网络, 估计网络用来输出实时的动作, 供 actor 在现实中实行. 而现实网络则是用来更新价值网络系统的. 所以我们再来看看价值系统这边, 我们也有现实网络和估计网络, 他们都在输出这个状态的价值, 而输入端却有不同, 状态现实网络这边会拿着从动作现实网络来的动作加上状态的观测值加以分析, 而状态估计网络则是拿着当时 Actor 施加的动作当做输入.在实际运用中, DDPG 的这种做法的确带来了更有效的学习过程.
4.10 Asynchronous Advantage Actor-Critic (A3C)
- 平行训练:采用Actor-Critic形式,拷贝多个副本平行训练,综合考量所有后再进行下一步
- 多核训练:在不同的核上并行运算
4.11 AlphaGo Zero 为什么更厉害?
进化算法
5.1 遗传算法 (Genetic Algorithm)
用进化理论来解决复杂问题
5.2 进化策略 (Evolution Strategy)
遗传算法和进化策略共享着一些东西. 他们都用遗传信息, 比如 DNA 染色体, 一代代传承, 变异. 来获取上一代没有的东西.然后通过适者生存, 不适者淘汰的这一套理论不断进化着.
一般的遗传算法使用的 DNA 是二进制编码的,而进化策略用的是实数。
在进化策略中, 可以有两种遗传性系被继承给后代, 一种是记录所有位置的均值, 一种是记录这个均值的变异强度, 有了这套体系, 我们就能更加轻松自在的在实数区间上进行变异了。
5.3 神经网络进化 (Neuro-Evolution)
介绍了一些进化的方法,比如在神经网络上加上遗传算法或进化策略、并行强化学习等。









