本文主要是介绍Python字典去重竟然比集合去重快速40多倍,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这里写目录标题
- 对比代码
- 结果图
- 代码解析
对比代码
from glob import glob
from tqdm import tqdm
import time
path_list=glob("E:/sky_150b/任务组_20231207_2023/*.jsonl")
# for two in tqdm(path_list):
one=path_list[0]with open(one,"r",encoding="utf-8") as f:data=f.readlines()
start=time.time()
data_list={}
for i in tqdm(data):if data_list.get(i,False)==False:data_list[i]="1"
print(time.time()-start)
start=time.time()
data_list = set()for i in tqdm(data):data_list|=set(i)
print(time.time() - start)# with open(one, "w", encoding="utf-8") as f:# f.writelines([i for i in data_list.keys()])#结果图
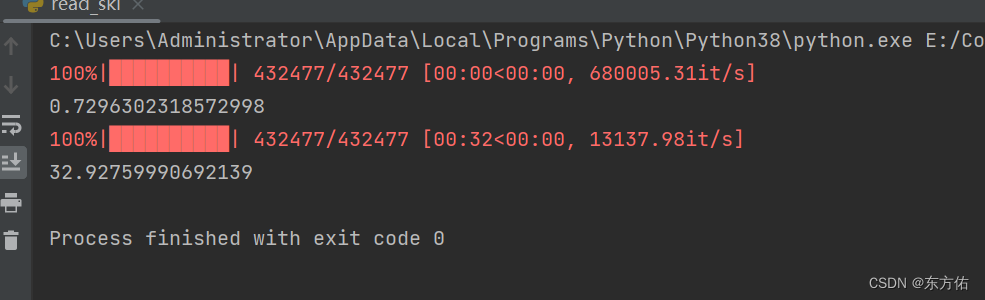
代码解析
这段代码的作用是比较两种方法分别用于处理一个文件中的数据重复项的时间效率。
具体流程如下:
-
导入需要用到的模块:
from glob import glob from tqdm import tqdm import timeglob模块用于查找匹配特定模式的文件路径名,它返回所有符合条件的文件路径列表。tqdm模块是一个用于在 Python 迭代器中添加进度条的库。 -
使用 glob 模块获取所有符合条件的文件路径名:
path_list=glob("E:/sky_150b/任务组_20231207_2023/*.jsonl")
这里使用了 glob() 函数获取了所有以 .jsonl 结尾文件的路径名,存储在 path_list 列表中。
-
对于每个文件路径名循环处理重复项:
one=path_list[0]with open(one,"r",encoding="utf-8") as f:data=f.readlines() start=time.time() data_list={} for i in tqdm(data):if data_list.get(i,False)==False:data_list[i]="1" print(time.time()-start) start=time.time() data_list = set()for i in tqdm(data):data_list|=set(i) print(time.time() - start)分别使用两种不同的方法处理文件中的重复项并计算时间。其中第一个循环使用了字典的键值对特性,通过判断键是否存在来去重,第二个循环则使用了 Python 内置的
set数据结构实现去重。time.time()函数用于获取当前时间戳,两次获取的时间戳相减即为整个循环处理时间。tqdm模块的作用是在循环时显示进度条,使得处理结果更加直观。
最终输出两种处理方法的时间。
这篇关于Python字典去重竟然比集合去重快速40多倍的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





