二叉树的三叉链式存储
三叉链式存储的思想是让每个节点不仅“记住”它的左,右两个节点,还要“记住”它的父节点,因此每个节点需要left,right,parent三个指针。
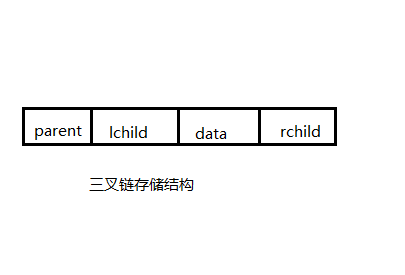
三叉链表存储方式是对二叉链表的一种改进,通过为树节点添加一个parent引用,可以让每个节点都能非常方便地访问其父节点。
三叉链表存储二叉树的节点定义
//三叉链表存储二叉树的节点定义class Node{Object data; //节点数据Node left; //左孩子指针Node rigth; //右孩子指针Node parent; //父节点指针public Object getData() {return data;}}



