本文主要是介绍MybatisPlus集成baomidou-dynamic,多数据源配置使用、MybatisPlus分页分组等操作示例,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- MybatisPlus特性
- MybatisPlus支持数据库
- MybatisPlus 架构
- 多数据源应用场景
- pom
- 配置
- 示例代码
MybatisPlus特性
无侵入:只做增强不做改变,引入它不会对现有工程产生影响,如丝般顺滑
损耗小:启动即会自动注入基本 CURD,性能基本无损耗,直接面向对象操作
强大的 CRUD 操作:内置通用 Mapper、通用 Service,仅仅通过少量配置即可实现单表大部分 CRUD 操作,更有强大的条件构造器,满足各类使用需求
支持 Lambda 形式调用:通过 Lambda 表达式,方便的编写各类查询条件,无需再担心字段写错
支持主键自动生成:支持多达 4 种主键策略(内含分布式唯一 ID 生成器 - Sequence),可自由配置,完美解决主键问题
支持 ActiveRecord 模式:支持 ActiveRecord 形式调用,实体类只需继承 Model 类即可进行强大的 CRUD 操作
支持自定义全局通用操作:支持全局通用方法注入( Write once, use anywhere )
内置代码生成器:采用代码或者 Maven 插件可快速生成 Mapper 、 Model 、 Service 、 Controller 层代码,支持模板引擎,更有超多自定义配置等您来使用
内置分页插件:基于 MyBatis 物理分页,开发者无需关心具体操作,配置好插件之后,写分页等同于普通 List 查询
分页插件支持多种数据库:支持 MySQL、MariaDB、Oracle、DB2、H2、HSQL、SQLite、Postgre、SQLServer 等多种数据库
内置性能分析插件:可输出 SQL 语句以及其执行时间,建议开发测试时启用该功能,能快速揪出慢查询
内置全局拦截插件:提供全表 delete 、 update 操作智能分析阻断,也可自定义拦截规则,预防误操作
MybatisPlus支持数据库
MySQL,Oracle,DB2,H2,HSQL,SQLite,PostgreSQL,SQLServer,Phoenix,Gauss ,ClickHouse,Sybase,OceanBase,Firebird,Cubrid,Goldilocks,csiidb,informix,TDengine,redshift
达梦数据库,虚谷数据库,人大金仓数据库,南大通用(华库)数据库,南大通用数据库,神通数据库,瀚高数据库,优炫数据库,星瑞格数据库
MybatisPlus 架构
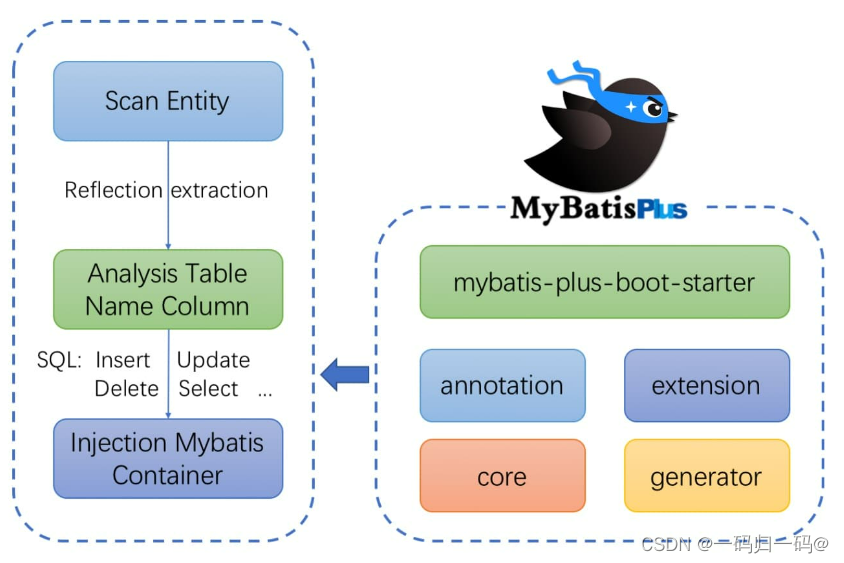
多数据源应用场景
1、是业务需求需要操作多个DB场景,比如:下单时,需要从用户库中查询用户信息,同时需要向订单库里插入一条订单;
2、读写分离场景;
常见的有2种实现方案,分别为:
- AOP + ThreadLocal ,如:Mybatis-plus的多数据源(dynamic-datasource);
- 语义解析,如:客户端侧:ShardingSphere-Jdbc,服务端侧:ShardingSphere-Proxy,阿里云、腾讯云proxy。
pom
<dependencies><!--mybatisPlus集成SpringBoot起步依赖--><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.4.2</version></dependency><!--MySQL 驱动依赖--><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.27</version></dependency><!--druid 数据连接池--><dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.1.20</version></dependency><dependency><groupId>com.baomidou</groupId><artifactId>dynamic-datasource-spring-boot-starter</artifactId><version>3.4.1</version></dependency><dependency><groupId>org.postgresql</groupId><artifactId>postgresql</artifactId><version>42.3.6</version></dependency></dependencies>
配置
配置文件
mybatis-plus.configuration.log-impl=org.apache.ibatis.logging.stdout.StdOutImpl
spring.datasource.dynamic.primary=mysql
spring.datasource.dynamic.strict=false
spring.datasource.dynamic.datasource.mysql.url=jdbc:mysql://192.168.0.111:3306/database?characterEncoding=UTF-8&useUnicode=true&useSSL=false&tinyInt1isBit=false¤tSchema=public
spring.datasource.dynamic.datasource.mysql.username=root
spring.datasource.dynamic.datasource.mysql.password=123456
spring.datasource.dynamic.datasource.mysql.driverClassName=com.mysql.cj.jdbc.Driver
spring.datasource.dynamic.datasource.mysql.type=com.alibaba.druid.pool.DruidDataSource
spring.datasource.dynamic.datasource.mysql.druid.maxActive=300
spring.datasource.dynamic.datasource.mysql.druid.initialSize=20
spring.datasource.dynamic.datasource.mysql.druid.maxWait=6000
spring.datasource.dynamic.datasource.mysql.druid.minIdle=20
spring.datasource.dynamic.datasource.mysql.druid.timeBetweenEvictionRunsMillis=60000
spring.datasource.dynamic.datasource.mysql.druid.minEvictableIdleTimeMillis=30000
spring.datasource.dynamic.datasource.mysql.druid.validationQuery=select 'x'
spring.datasource.dynamic.datasource.mysql.druid.testWhileIdle=true
spring.datasource.dynamic.datasource.mysql.druid.testOnBorrow=true
spring.datasource.dynamic.datasource.mysql.druid.testOnReturn=falsespring.datasource.dynamic.datasource.postgresql.url= jdbc:postgresql://127.0.0.1:5432/database?characterEncoding=UTF-8&useUnicode=true&useSSL=false&tinyInt1isBit=false¤tSchema=public
spring.datasource.dynamic.datasource.postgresql.username=postgres
spring.datasource.dynamic.datasource.postgresql.password=123456
spring.datasource.dynamic.datasource.postgresql.driverClassName=org.postgresql.Driver
spring.datasource.dynamic.datasource.postgresql.type=com.alibaba.druid.pool.DruidDataSource
spring.datasource.dynamic.datasource.postgresql.druid.maxActive=300
spring.datasource.dynamic.datasource.postgresql.druid.initialSize=20
spring.datasource.dynamic.datasource.postgresql.druid.maxWait=6000
spring.datasource.dynamic.datasource.postgresql.druid.minIdle=20
spring.datasource.dynamic.datasource.postgresql.druid.timeBetweenEvictionRunsMillis=60000
spring.datasource.dynamic.datasource.postgresql.druid.minEvictableIdleTimeMillis=30000
spring.datasource.dynamic.datasource.postgresql.druid.validationQuery=select 'x'
spring.datasource.dynamic.datasource.postgresql.druid.testWhileIdle=true
spring.datasource.dynamic.datasource.postgresql.druid.testOnBorrow=true
spring.datasource.dynamic.datasource.postgresql.druid.testOnReturn=false
配置类
解决分页失效问题
import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor;
import com.baomidou.mybatisplus.extension.plugins.inner.PaginationInnerInterceptor;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;@Configuration
@MapperScan("com.ais.**.mapper.**")
public class MybatisPlusConfig {@Beanpublic MybatisPlusInterceptor mybatisPlusInterceptor() {MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();interceptor.addInnerInterceptor(new PaginationInnerInterceptor());return interceptor;}
}
示例代码
实体类
@TableName(“tableName”)
@TableField
@TableId
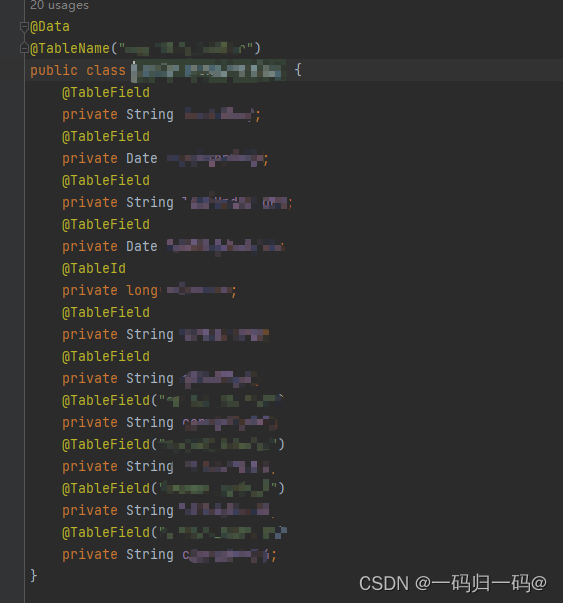
Mapper
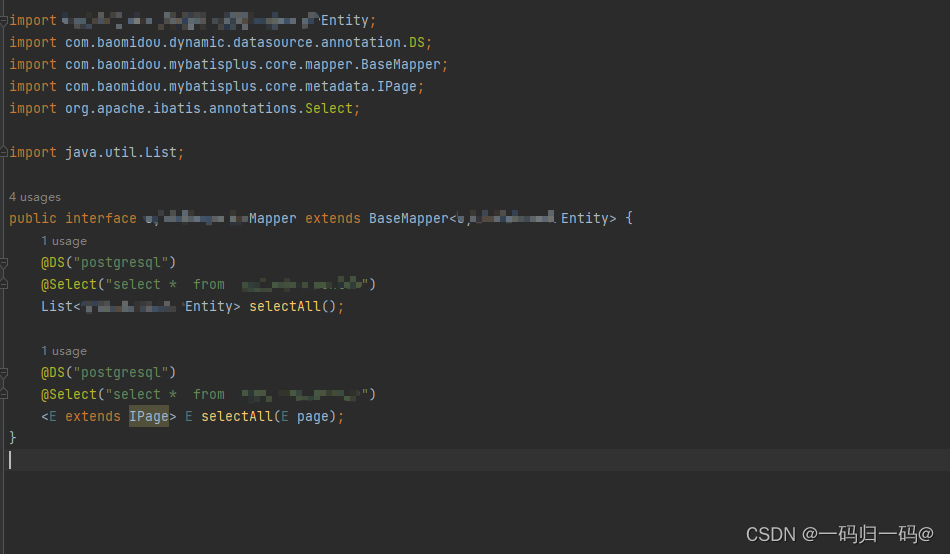
参考代码
import com.UserEntity;
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.baomidou.mybatisplus.core.metadata.IPage;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import lombok.extern.slf4j.Slf4j;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;import javax.annotation.Resource;
import java.util.ArrayList;
import java.util.List;@Slf4j
@RunWith(SpringRunner.class)
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
public class MybatisTest {@Resourceprivate UserMapper mapper;/*** 分页操作 Mysql MybatisPlus*/@Testpublic void page() {IPage page = new Page(2, 2);IPage iPage = mapper.selectPage(page, null);System.out.println(iPage.getRecords());}/*** PGSQL 自定义SQL分页*/@Testpublic void pagePg() {IPage page = new Page(1, 1);IPage iPage = mapper.selectAll(page);System.out.println(iPage.getRecords());}/*** 分页加排序降序*/@Testpublic void sort() {IPage page = new Page(1, 10);QueryWrapper<Entity> queryWrapper = new QueryWrapper<>();//降序queryWrapper.orderByDesc("center_Id");//升序
// queryWrapper.orderByAsc("center_Id");IPage iPage = mapper.selectPage(page, queryWrapper);System.out.println(iPage.getRecords());}/*** 分页加排序降序 lambda 表达式*/@Testpublic void lambdaSort() {IPage page = new Page(1, 10);LambdaQueryWrapper<Entity> queryWrapper = new LambdaQueryWrapper<>();//降序queryWrapper.orderByDesc(Entity::getCenterId);//升序
// queryWrapper.orderByAsc(Entity::getCenterId);IPage iPage = mapper.selectPage(page, queryWrapper);System.out.println(iPage.getRecords());}/*** in条件过滤 lambda 表达式*/@Testpublic void selectIn() {IPage page = new Page(1, 10);LambdaQueryWrapper<Entity> queryWrapper = new LambdaQueryWrapper<>();List<Long> ids = new ArrayList<>();ids.add(1l);ids.add(2l);ids.add(3l);ids.add(4l);queryWrapper.in(Entity::getCenterId, ids);
// queryWrapper.notIn(Entity::getCenterId, ids);IPage iPage = mapper.selectPage(page, queryWrapper);System.out.println(iPage.getRecords());}/*** in条件过滤 lambda 表达式*/@Testpublic void selectInSql() {IPage page = new Page(1, 10);LambdaQueryWrapper<Entity> queryWrapper = new LambdaQueryWrapper<>();queryWrapper.inSql(Entity::getCenterId, "select center_Id from center where center_Id>5");
// queryWrapper.notIn(Entity::getCenterId, ids);IPage iPage = mapper.selectPage(page, queryWrapper);System.out.println(iPage.getRecords());}@Testpublic void select() {IPage page = new Page(1, 10);LambdaQueryWrapper<Entity> queryWrapper = new LambdaQueryWrapper<>();IPage iPage = mapper.selectPage(page, queryWrapper);System.out.println(iPage.getRecords());}/*** max 加分组*/@Testpublic void selectMax() {IPage page = new Page(1, 10);QueryWrapper<Entity> queryWrapper = new QueryWrapper<>();queryWrapper.select("max(center_id) as center_id").groupBy("created_By");IPage iPage = mapper.selectPage(page, queryWrapper);System.out.println(iPage.getRecords());}/*** count 加分组*/@Testpublic void selectCount() {IPage page = new Page(1, 10);QueryWrapper<Entity> queryWrapper = new QueryWrapper<>();queryWrapper.select("count(center_id) as count").groupBy("created_By");mapper.selectPage(page, queryWrapper);}
}
这篇关于MybatisPlus集成baomidou-dynamic,多数据源配置使用、MybatisPlus分页分组等操作示例的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




