本文主要是介绍grep、egrep、fgrep的用法与特性详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
[转载自]http://tanxw.blog.51cto.com/4309543/1361993
开篇
学习Linux也有一段时间了,对Linux多少也算是有点了解了,越是了解也就越对这个系统有兴趣,从0基础开始,已经学习了两周了吧,说实在的,很多的东西都是逻辑的问题,而学习Linux就是要熟悉命令,命令很多,要记的东西也很多,多得可以你让头皮发麻,不过话又说回来了,既然选择了这门技术,那就义无反顾的去做好做专,好了,总结一下这两周来感觉学起来比较用力的部分。
正文之:grep的详细介绍
grep和egrep是现在感觉比较难的一部分,主要是符号多,看得眼花了乱。
grep(global search regular expression and prind out the line)全称就叫全面搜索正则表达式 并打印行出来,简单来说就是文本搜索工具,根据用户指定的文本搜索模式对目标文本进行搜索,显示能够所匹配的行,当然,也可以把grep看也是一个文本过虑器。
格式:grep [options]... 'PATTERD模式' file....
模式:就是一个最基本的字符串
如:grep –A 1 '[r][[:punct:]]*[t]' /etc/passwd ''里的内容就是模式
grep的常用选项:
-v:反向匹配、显示不能别模式匹配到的行;
例:取出/etc/fstab不包含#号的行
gerp –v "#" /etc/fstab
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | [root@localhost xiao] # cat /etc/fstab # # /etc/fstab # Created by anaconda on Mon Feb 10 10:38:04 2014 # # Accessible filesystems, by reference, are maintained under '/dev/disk' # See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info # /dev/mapper/vg0-root / ext4 defaults 1 1 UUID=99e81364-46cb-4795-974a-6cc0ab91a46f /boot ext4 defaults 1 2 /dev/mapper/vg0-usr /usr ext4 defaults 1 2 /dev/mapper/vg0-var /var ext4 defaults 1 2 /dev/mapper/vg0-swap swap swap defaults 0 0 tmpfs /dev/shm tmpfs defaults 0 0 devpts /dev/pts devpts gid=5,mode=620 0 0 sysfs /sys sysfs defaults 0 0 proc /proc proc defaults 0 0 [root@localhost xiao] # grep -v "#" /etc/fstab /dev/mapper/vg0-root / ext4 defaults 1 1 UUID=99e81364-46cb-4795-974a-6cc0ab91a46f /boot ext4 defaults 1 2 /dev/mapper/vg0-usr /usr ext4 defaults 1 2 /dev/mapper/vg0-var /var ext4 defaults 1 2 /dev/mapper/vg0-swap swap swap defaults 0 0 tmpfs /dev/shm tmpfs defaults 0 0 devpts /dev/pts devpts gid=5,mode=620 0 0 sysfs /sys sysfs defaults 0 0 proc /proc proc defaults 0 0 |
-o:仅匹配被模式匹配到的字串,而非整行,就是仅显示匹配到的内容
例:只显示/etc/fstab为mapper的字串
grep -o "mapper" /etc/fstab
| 1 2 3 4 5 | [root@localhost xiao] # grep --color=auto -o "mapper" /etc/fstab mapper mapper mapper mapper |
-i:不区分大小写对文本进行匹配搜索

-E:支持扩展正则表达式
-A #:显示模式匹配到的行以及后面的N行 #代表你要显示多少行
例:显示/etc/passwd中shutdown用户后面3行

-B #:显示模式匹配到的行以及前面的N行
例:显示/etc/passwd中shutdown用户上面2行

-C #:显示模式匹配到的行以及上下的N行
例:显示/etc/passwd中shutdown用户上下面2行

其实,要用好grep的强大搜索功能,那就不得不说说正则表达式了:
正则表达式就是一类字符所书写出来的模式(pattern)、正则表达式基本上都是由元字符组成;
那什么是元字符呢:元字符不表示字符本身的意义,而是用于额外功能性的描述。
基本正则表达式的元字符:学习正则表达式主要是来学习其元字符的用法后慢慢组合这些元字符来表达到正则表达式的使用,grep在默认情况下只支持基本正则表达式。
注意:
模式当中一但包含元字符一定要用''或""号引起来,单双引号都可以、只不过如果其中出现了变量、并且我们希望做变量替换的话那就要使用""双引号了、否则可以不加区分的使用。
那就来说说元字符的通配:
.(点号):匹配任意的单个字符的
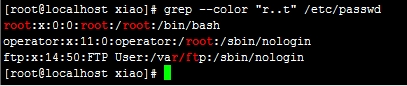
例:grep "r..t" /etc/passwd
rt加上两点被匹配到的只有4个字符,点号表示的是单个字符
[]:指定范围内的任意的单个字符
[0-9] [[:digit:]]:表示匹配0到9的任意单个数字、两种表示方法都可以
[a-z] [[:lower:]]:表示匹配小写的a到z的任意单个字母、即a-z
[A-Z] [[:upper:]]:表示匹配大写的A到Z的任意单个字母、即A-Z
[[:alpha:]]:表示英文大小写字母、即:a-z,A-Z
[[:space:]]:表示包含的空白字符、即空格键,tab键
[[:alnum:]]:表示包含数字大小写字母、即0-9,A-Z,a-z
[[:punct:]]:表示包含标点符号、即:" ' ? ! ; : # $...
例:显示/etc/fstab下含有数字的行
grep --color [0-9] /etc/fstab

例:显示/etc/fstab中包含大写字母的行
grep --color "[[:upper:]]" /etc/fstab

[^]:表示指定范围外的任意单个字符、就是使用了脱字符取反
例:显示/etc/fstab中数字以外的内容
grep --color [^[:digit:]] /etc/fstab

字符的次数匹配:用来匹配其前面的字符的次数的
*:(星号)匹配其紧挨着星号的字符出现任意次
例:x*y就是x可以出现意次、包括0次
.*:(点星)匹配任意长度的任意字符
\?:表示其前面的字符出现0次或者1次、\是转译字符
例:x\?y:可以匹配到的只有xy和y
\{m\}:匹配m次 如:x\{4\}y表示y前面的x出现4前就可以被匹配到
\{m,n\}:至少m次,至多n次
\{m,\}:至少m次
\{0,n\}:至多匹配n次、0不可以省略
例:找出/etc/fstab文件中一位数或两位数
grep --color '\<[0-9]\{1,2\}\>' /etc/fstab
\{1,2\}:表示0-9的数字出现的至有1位、至多有2位、

位置锚定符:用于指定字符出现的位置
^:用于锚定行首,如(^Char) 匹配到的字符必须出现有行首的
$:用于锚定行尾,如(Char$) grep 'bash$' /etc/passwd
^$:空白行、查找一个文件中所出现的空白行 ^hello$表示只有hello的行
例:显示/etc/fstab中以#号开头的行
grep --color "^#" /etc/fstab

单词的锚定:
\<char:锚定词首,\<[r]表示一行以r开头的单词都可以匹配、也可以使用\b表示
char\>:锚定词尾,一行以r开头的单词都可以匹配、\b
\<hello\>:表示精确锚定hello这个单词
\<h…o\>:表示以h开头、以o结尾、中间跟了任意三个字符的单词
例:显示/etc/passwd中以stu开头的单词
grep --color "\<stu" /etc/passwd 只要是以stu开头的单词都会被匹配到

分组元字符:
\(\):分组 \是转译字符
例:\(ab\)*xy
ab括起来表示一个组了,表示xy前面的ab组现出任意次,可以被匹配到的
abxy,ababxy,ababababxy,abababababababxy,......
引用: 对分组的字符块进行引用
\1:后向引用,引用前面的第一个左括号以及与之对应的右括号中模式所匹配到的内容
\2:后向引用,引用前面的第二个左括号以及与之对应的右括号中模式所匹配到的内容
.......
例:\(a.b\)xy\1 可以匹配到的有(abxyab不可以匹配到)
akbxyakb,a3bxya3b,aYbxyaYb
例:我们来看这个例子、找出以下love与之对应的lover、like与之对应的liker
He like his lover.
She love her liker.
He love his lover.
She like her liker.

正文之:egrep的详细介绍
egrep:使用扩展正则表达式来构建模式,相当于grep –E、通常写成egrep、用法基本上跟grep的相同、只是有些不需要\转译
元字符:字符匹配
.:匹配任意单个字符
[]:指定范围内的任意单个字符
次数匹配:
*:匹配其紧挨着星号的字符出现任意次
?:表示其前面的字符出现0次或者1次
+:匹配其前面的字符至少1次
{m}:匹配其前面的字符m次
{m,n}:至少m次,至多n次
{m,}:至少m次
{0,n}:至多n次
例:找出/etc/fstab文件中一位数或两位数
egrep --color '\<[0-9]{1,2}\>' /etc/fstab {}不需要转译

做位置锚定:
^:行首锚定
$:行尾锚定
\<:词首
\>:词尾
分组:
():分组
|:或者 ab|xy意思为ab或者xy a(b|x)y意思为aby或者axy
正文之:fgrep的详细介绍
fgrep:fash,它不解析正则表达式、想找什么就跟什么就可以了;
例:
fgrep "/bin/bash" /etc/passwd
例:显示/etc/fstab中含有defaults的行
fgrep --color "defaults" /etc/fstab

结束
常用的大概的内容应该就这些吧,这些都是学习当中的基本用法和我个人的笔记,总结并记下,以便以后查找,同时,虽然是刚学习的,也希望我个人的总结可以帮到更多的人,哦了,不多说了,就总结到这里了,欢迎大神来指点。
这篇关于grep、egrep、fgrep的用法与特性详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






