本文主要是介绍【基于openGauss5.0.0简单使用DBMind】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
基于openGauss5.0.0简单使用DBMind
- 一、环境说明
- 二、初始化tpch测试数据
- 三、使用DBMind索引推荐功能
- 四、使用DBMind实现SQL优化功能
一、环境说明
- 虚拟机:virtualbox
- 操作系统:openEuler 20.03 TLS
- 数据库:openGauss-5.0.0
- DBMind:dbmind-5.0.0
注意:环境是基于x86架构
二、初始化tpch测试数据
-
使用普通用户如
omm登录服务器 -
执行如下命令下载测试数据库:
git clone https://gitee.com/xzp-blog/tpch-kit.git -
进入dbgen目录下,生成makefile文件:
cd /opt/software/tpch-kit/dbgen/ make -f Makefile -
连接openGauss数据库,创建tpch的database:
gsql -d postgres -p 15432 -r openGauss=# CREATE DATABASE tpch; openGauss=# \q -
创建8张测试表,执行如下命令:
cd /opt/software/tpch-kit/dbgen gsql -d tpch -f dss.ddl执行完成后,登录数据库查看,会看到如下8张表:
List of relationsSchema | Name | Type | Owner | Storage --------+----------+-------+-------+----------------------------------public | customer | table | omm | {orientation=row,compression=no}public | lineitem | table | omm | {orientation=row,compression=no}public | nation | table | omm | {orientation=row,compression=no}public | orders | table | omm | {orientation=row,compression=no}public | part | table | omm | {orientation=row,compression=no}public | partsupp | table | omm | {orientation=row,compression=no}public | region | table | omm | {orientation=row,compression=no}public | supplier | table | omm | {orientation=row,compression=no} -
生成8张表测试数据,执行如下命令:
cd /opt/software/tpch-kit/dbgen ./dbgen -vf -s 1执行结果如下:
[omm@opengauss01 dbgen]$ ./dbgen -vf -s 1 TPC-H Population Generator (Version 2.17.3) Copyright Transaction Processing Performance Council 1994 - 2010 Generating data for suppliers table/ Preloading text ... 100% done. Generating data for customers tabledone. Generating data for orders/lineitem tablesdone. Generating data for part/partsupplier tablesdone. Generating data for nation tabledone. Generating data for region tabledone. -
编写导入数据脚本LoadData.sh:
for i in `ls *.tbl`; dotable=${i/.tbl/}echo "Loading $table..."sed 's/|$//' $i > /opt/software/tmp/$igsql tpch -p 15432 -q -c "TRUNCATE $table"gsql tpch -p 15432 -c "\\copy $table FROM '/opt/software/tmp/$i' CSV DELIMITER '|'" done注意:当前数据库端口为15432
授予执行权限:[omm@opengauss01 dbgen]$ chmod +x LoadData.sh -
导入数据到8张表中,执行导入脚本LoadData.sh:
[omm@opengauss01 dbgen]$ sh LoadData.sh执行结果如下:
Loading customer... Loading lineitem... Loading nation... Loading orders... Loading partsupp... Loading part... Loading region... Loading supplier... -
检验数据是否已完成导入:
gsql -d tpch-p 15432 -r tpch=# select count(*) from supplier;查看了supplier表的总记录数为:10000条。
感兴趣可以全部查看8张表各自的总记录数,如下所示:至此,已完后TPCH测试数据的导入工作。
-
生成相关查询语句,为避免对原有查询语句脚本产生污染,将其复制到queries目录下:
cd /opt/software/tpch-kit/dbgen cp dists.dss queries/ cp qgen queries/ cd queries/ -
编写生成查询语句脚本genda.sh,内容如下:
cd /opt/software/tpch-kit/dbgen/queries vim genda.sh添加如下内容:
for i in {1..22}; do./qgen -d $i>$i_new.sql./qgen -d $i_new | sed 's/limit -1//' | sed 's/limit 100//' | sed 's/limit 10//' | sed 's/limit 20//' | sed 's/day (3)/day/' > queries.sql done -
执行脚本genda.sh:
cd /opt/software/tpch-kit/dbgen sh genda.sh -
验证生成的查询语句:
cd /opt/software/tpch-kit/dbgen/queries ls -l queries.sql结果如下:
[omm@opengauss01 queries]$ ls -l queries.sql -rw-r--r-- 1 omm dbgrp 12K Aug 29 23:49 queries.sql感兴趣可以查看下queries.sql内容,看下生成了哪些SQL语句
至此,已完成了查询语句的生成。 -
为了测试AP性能,以omm用户上传tpch_ap_data.sql(可点击下载)到/opt/software目录下,然后执行如下命令执行该sql文件:
gsql -d tpch -p 15432 -r -f /opt/software/tpch_ap_data.sql > /opt/software/tpch_ap_data.sql执行完成后,整个tpch数据库中相关表如下:
tpch=# \dList of relationsSchema | Name | Type | Owner | Storage --------+-----------------------------------+----------+-------+----------------------------------public | address_dimension | table | omm | {orientation=row,compression=no}public | address_dimension_address_key_seq | sequence | omm |public | customer | table | omm | {orientation=row,compression=no}public | date_dimension | table | omm | {orientation=row,compression=no}public | lineitem | table | omm | {orientation=row,compression=no}public | litemall_orders | table | omm | {orientation=row,compression=no}public | nation | table | omm | {orientation=row,compression=no}public | orders | table | omm | {orientation=row,compression=no}public | part | table | omm | {orientation=row,compression=no}public | partsupp | table | omm | {orientation=row,compression=no}public | region | table | omm | {orientation=row,compression=no}public | supplier | table | omm | {orientation=row,compression=no}public | user_dimension | table | omm | {orientation=row,compression=no}public | user_dimension_user_key_seq | sequence | omm |
三、使用DBMind索引推荐功能
- 第一种使用方式:
- 以gsql登录到数据库中
gsql -d tpch -p 15432 -r - 执行如下命令查看索引推荐
结果如下:select * from gs_index_advise(' SELECT ad.province AS province, SUM(o.actual_price) AS GMVFROM litemall_orders o,address_dimension ad,date_dimension ddWHERE o.address_key = ad.address_keyAND o.add_date = dd.date_keyAND dd.year = 2020AND dd.month = 3GROUP BY ad.provinceORDER BY SUM(o.actual_price) DESC');schema | table | column | indextype --------+-------------------+----------------------+-----------public | litemall_orders | address_key,add_date |public | address_dimension | |public | date_dimension | year | (3 rows)
- 以gsql登录到数据库中
- 第二种使用方式:
-
登录到DBMind的管理界面中,输入相关SQL语句:
select * from customer where c_acctbal > 6819.74 order by c_acctbal desc limit 10;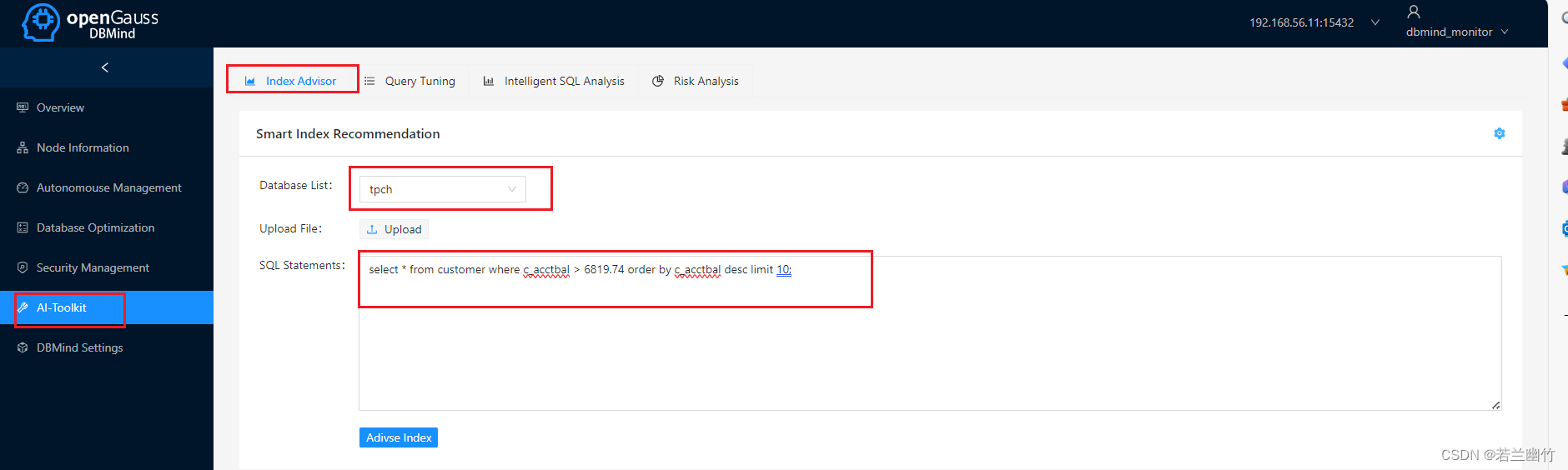
-
点击【Advise Index】按钮,正常情况下会看到如下内容:

-
四、使用DBMind实现SQL优化功能
- 登录到DBMind的管理界面中,输入相关SQL语句:
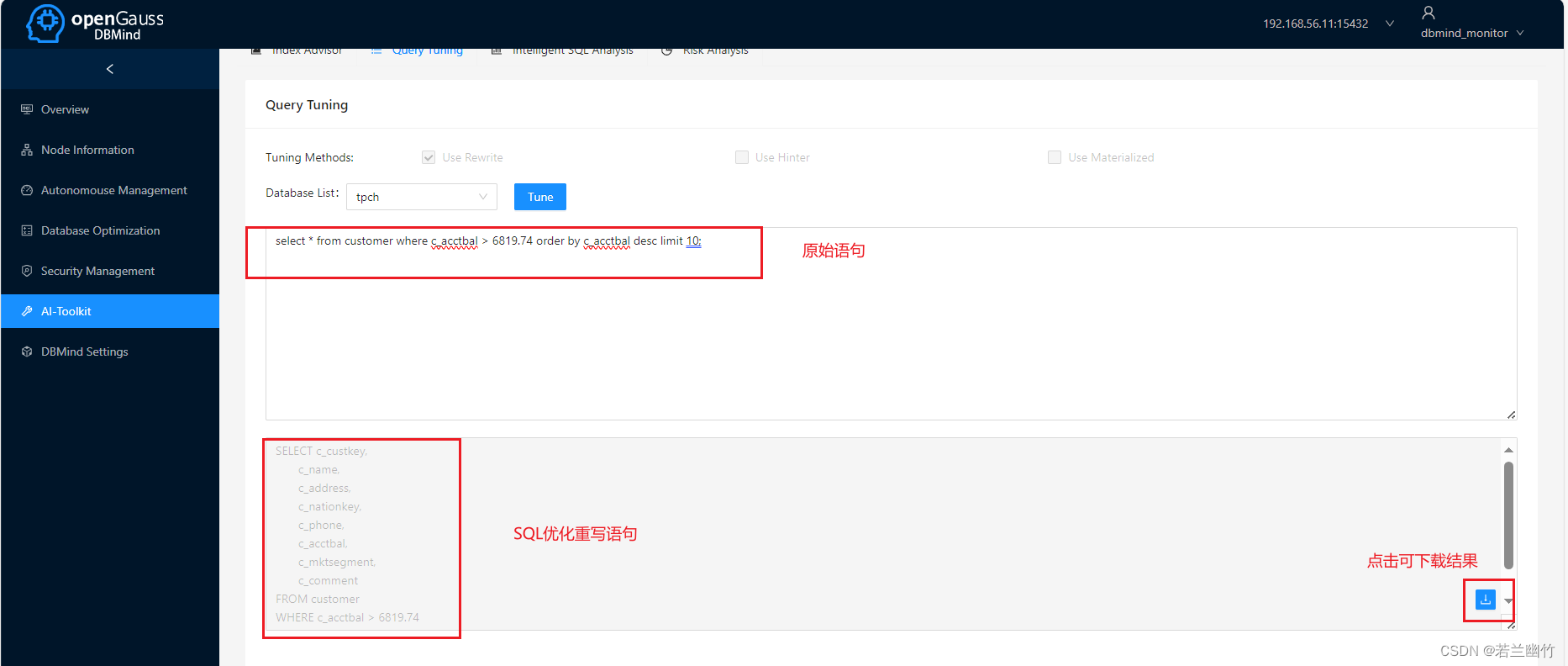
其他的有关DBMind的功能,大家感兴趣,可自行测试,希望对您有所帮助~~~~~
这篇关于【基于openGauss5.0.0简单使用DBMind】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







