本文主要是介绍Dropwizard-metric的使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
背景
近期在开发中用到了dropwizard-metric作为监控metric的埋点框架,由于是分布式的系统,前期曾经对比过hadoop-metric的实现和dropwizard-metric的实现,因为开发的项目后续会和hadoop的项目有一定的上下游关系,所以考虑排除掉hadoop的引用,防止后续出现循环依赖等问题。所以深度的调研了dropwizard-metric的使用,发现alluxio,ozone,ratis等项目都或多或少的使用了dropwizard-metric框架,所以本文详细的介绍一下dropwizard-metric的使用。
dropwizard-metric介绍
官方的介绍为,它提供了一个强大的组件包,可以用来衡量生产环境中关键组件的行为方法。简化来说就是监控!大家现在普遍接受的架构多半是promethus+grafa,那promethus的数据来源就依赖系统中的埋点,dropwizard-metric就是这样一个框架,它支持埋点并将数据以多种形式report对外暴漏供用户使用。
首先,当然需要引入mvn依赖,注意版本号,当前官方文档最新的release版本为4.2,之前的release已经停止维护了。
<dependencies><dependency><groupId>io.dropwizard.metrics</groupId><artifactId>metrics-core</artifactId><version>${metrics.version}</version></dependency>
</dependencies>下面介绍dropwizard中的几个常用的埋点类型:
-
Counter :递增的数据,配置告警和监控时需要使用diff
-
Gauge: 使用与瞬时值,比如查看当前队列长度等等
-
Timer: 使用try with resource包含,可以用来查看try包含的操作的执行时间
-
Histograms:用来查看各种延迟信息,95th,99th,最大值,最小值等等
-
Meter:一段时间内发生的请求数,可以用来计算QPM,QPS等等?这个暂时没用到
-
healthCheck:可用于监控某些链接是否正常,状态是否正常等等,如连接数据库,定期check
埋点操作完成后,要进行数据的report, 该框架提供了多种report方法,其中包含:
- jmxReporter, report之后可以从VisualVM查看当前的metric值
- httpReporter, 需要增加引用, 该引用作用是默认认为你的系统中使用jetty等或者其他框架的web框架,可以将metric的数据暴露到http界面中
<dependency><groupId>io.dropwizard.metrics</groupId><artifactId>metrics-servlets</artifactId><version>${metrics.version}</version>
</dependency>- ConsoleReporter: 将metric信息打印到控制台,可以设置时间间隔
- Log4jReporter: 将metric信息通过日志的形式打印
- 其它的还有CSVReporter, GraphiteReporter
dropwizard-metric的使用
需要有一个全局的registry负责注册系统中的所有metric,注意healthCheck的使用方式有些不同,后面单独讲解
private final MetricRegistry metrics = new MetricRegistry();有了registry就可以之后可以用来注册具体的指标类型使用了。
- gauge, 其中getValue可以自己定义一个方法,用来获取某一个瞬时值
metrics.register("testGaugeSize", () -> getValue());- counter, 注册之后可以调用counter的icr()和dec()等方法
// 注册
private final Counter testCounter = metrics.counter("testCounterNums");// 使用
testCounter.icr();
testCounter.dec();- meter,用来计算QPM或QPS等等,可以放在一个统一的入口位置。
// 注册
private final Meter meterTest = metrics.meter("meterTest");// 使用
public void handleRequest(Request request, Response response) {meterTest.mark();
}- timer, 用来计算某一些操作的耗时,可以使用try with resource的形式,或者使用try finally记得要关闭context即可
private final Timer testTimer = metrics.timer("testTimer");public String handleRequest(Request request, Response response) {try(final Timer.Context context = testTimer.time()) {// 一些处理逻辑,也就是计算耗时的部分}
}- histograms,直方图,顾名思义是一算一些最大值,最小值,平均值,中位数等等
private final Histogram testHistogram = metrics.histogram("testHistogram");public void handleRequest(Request request, Response response) {// etctestHistogram.update(response.getContent().length);
}- Health_check的使用和以上有一些差别,如下:
// 需要单独注册registry,不和上边的metric类型公用
final HealthCheckRegistry healthChecks = new HealthCheckRegistry();
// 使用方式,需要先继承HealthCheck的类,实现自己的check逻辑
public class DatabaseHealthCheck extends HealthCheck {private final Database database;public DatabaseHealthCheck(Database database) {this.database = database;}@Overridepublic HealthCheck.Result check() throws Exception {if (database.isConnected()) {return HealthCheck.Result.healthy();} else {return HealthCheck.Result.unhealthy("Cannot connect to " + database.getUrl());}}
}
// 注册到全局的healthChecks中
healthChecks.register("testHealthCheck", new DatabaseHealthCheck(database));- 可以注册一些dropwizard原生的JVM或者GC相关的数据到registry当中,可以帮助定位JVM的相关问题
-
registry.registerAll(new JvmAttributeGaugeSet()); registry.registerAll(new GarbageCollectorMetricSet()); registry.registerAll(new MemoryUsageGaugeSet()); registry.registerAll(new ClassLoadingGaugeSet());
dropwizard-metric的report方式
report的方式有多种,一般常用的可能有jmxReporter, httpReporter在本文中只是简单的举例,大家可以根据自己的用法继续探索挖掘。
- jmxReporter
需要增加mvn引用
<dependency><groupId>io.dropwizard.metrics</groupId><artifactId>metrics-jmx</artifactId><version>${metrics.version}</version>
</dependency>使用方式也比较简单:
// registry为上文提到的全局registry
final JmxReporter reporter = JmxReporter.forRegistry(registry).build();
reporter.start();在以上完成后,可以使用VisualVM查看是否被report到JVM的MBeans中,使用java中自带的即可,但是需要安装Mbeans的插件,安装成功后可以看到如下:

- HttpReporter, 该reporter的方式为用户可视化的方式看到metric
需要额外的引用
<dependency><groupId>io.dropwizard.metrics</groupId><artifactId>metrics-servlets</artifactId><version>${metrics.version}</version>
</dependency>使用方式为,项目中的web服务,自定义一个servlet并将它加到你的httpServer中,类似
addServlet("metrics", "/metrics", MetricsServlet.class);servlet注册成功后,可以从界面上看到如下界面:
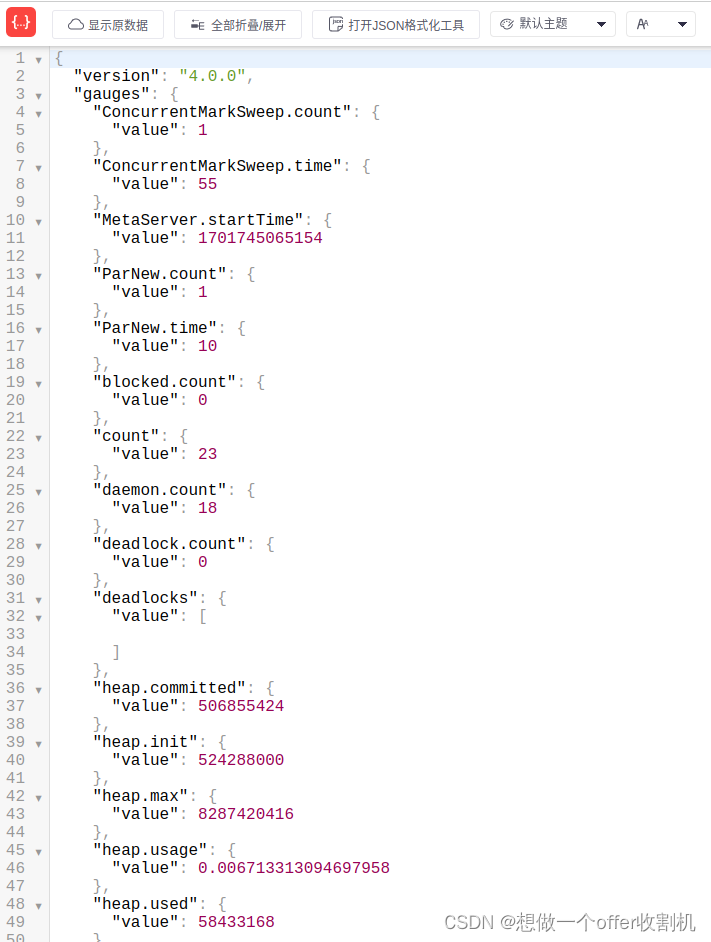
其它的reporter的使用方式,在此不再多余的讲解,感兴趣可以直接查看官方文档other-reporting
其它思考
按照当前的使用方式,每个metric定义的时候都需要使用registry.counter或者.timer或者.meter才能使用这个metric,很样就导致metric的对象实现在项目中特别琐碎,可能放到任何一个你需要监控的类中,在用户使用过程中可以参考hadoop的@Metric的注解,自定义实现一个注解,用来标注metric的类型,name等等,在类加载的过程中将指标register到全局registry中,使用起来更加的方便,其他人在使用时可以直接标注注解即可,不需要学习更多的dropwizard-metric的使用方法即可参与到代码实现中。
这篇关于Dropwizard-metric的使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




