本文主要是介绍repmgr简介及配置,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
什么是REPMGR?
repmgr是一个开源工具套件,用于管理PostgreSQL服务器集群中的复制和故障转移。它使用工具来增强PostgreSQL的内置热备份功能,以设置备用服务器,监控复制以及执行管理任务,例如故障转移或手动切换操作。
repmgr是2010年由2ndQuadrant推出的PostgreSQL故障切换最流行的工具。
repmgr帮助DBA和系统管理员管理PostgreSQL数据库集群。通过利用PostgreSQL 9中引入的Hot Standby功能,repmgr极大地简化了设置和管理具有高可用性和可伸缩性要求的数据库的过程。
repmgr通过以下方式简化了管理和日常管理,提高了生产力并降低了PostgreSQL集群的总体成本:
- 监视复制过程
- 允许DBA发布高可用性操作,例如切换和故障切换。
可用性
(repmgr v4.0.4发布 - 2018年3月9日)
repmgr可通过 2ndQuadrant的Red Hat系列(RHEL,CentOS和Fedora)的YUM存储 库和Debian的PGDG的APT存储库(请使用Beta版的测试存储库 - 更多详细信息请参见下面的安装说明链接)获得。 您可以使用标准的yum和apt软件包管理器来与您的PostgreSQL实例一起安装repmgr。
- repmgr 3+需要PostgreSQL 9.3或更高版本
- repmgr 2.x需要PostgreSQL 9.1或9.2
点击这里查看使用yum和apt的详细安装说明
点击这里下载最新的tarball
点击此处查看发行说明
配置
以下图示和解释代表生产数据库中repmgr的一些最常见的配置。
1 Primary + 1 Standby
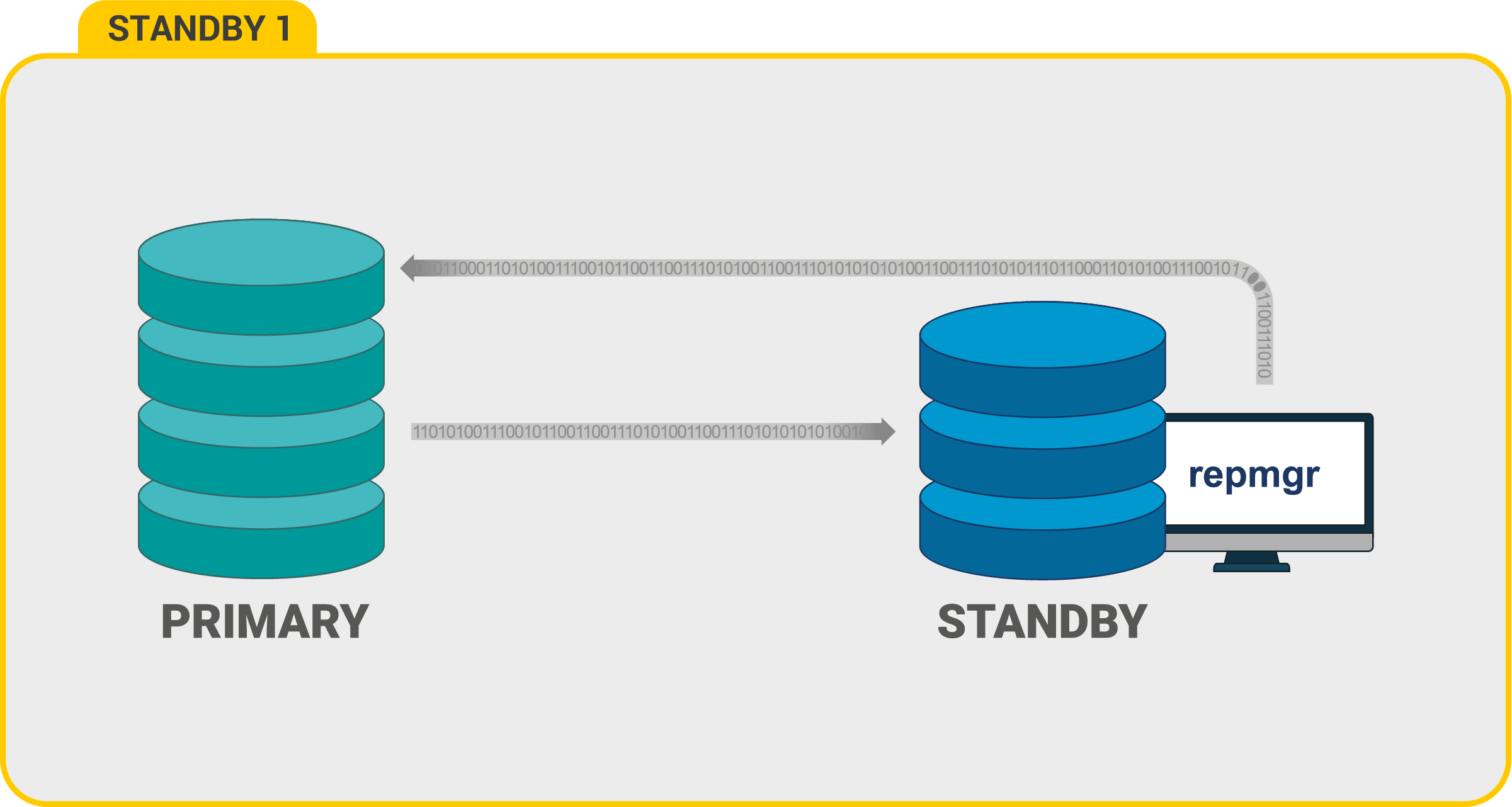
这里,在主节点发生故障的情况下,将repmgr配置为备用以进行故障切换。
1 Primary + 2 Standbys

这里,在主节点发生故障的情况下,在2个待机节点上配置repmgr以进行故障切换。其他备用节点配置为高可用性(HA),因此在故障转移后至少有一个备用节点仍然存在。
1 Primary + 3 Standbys + 1 Witness
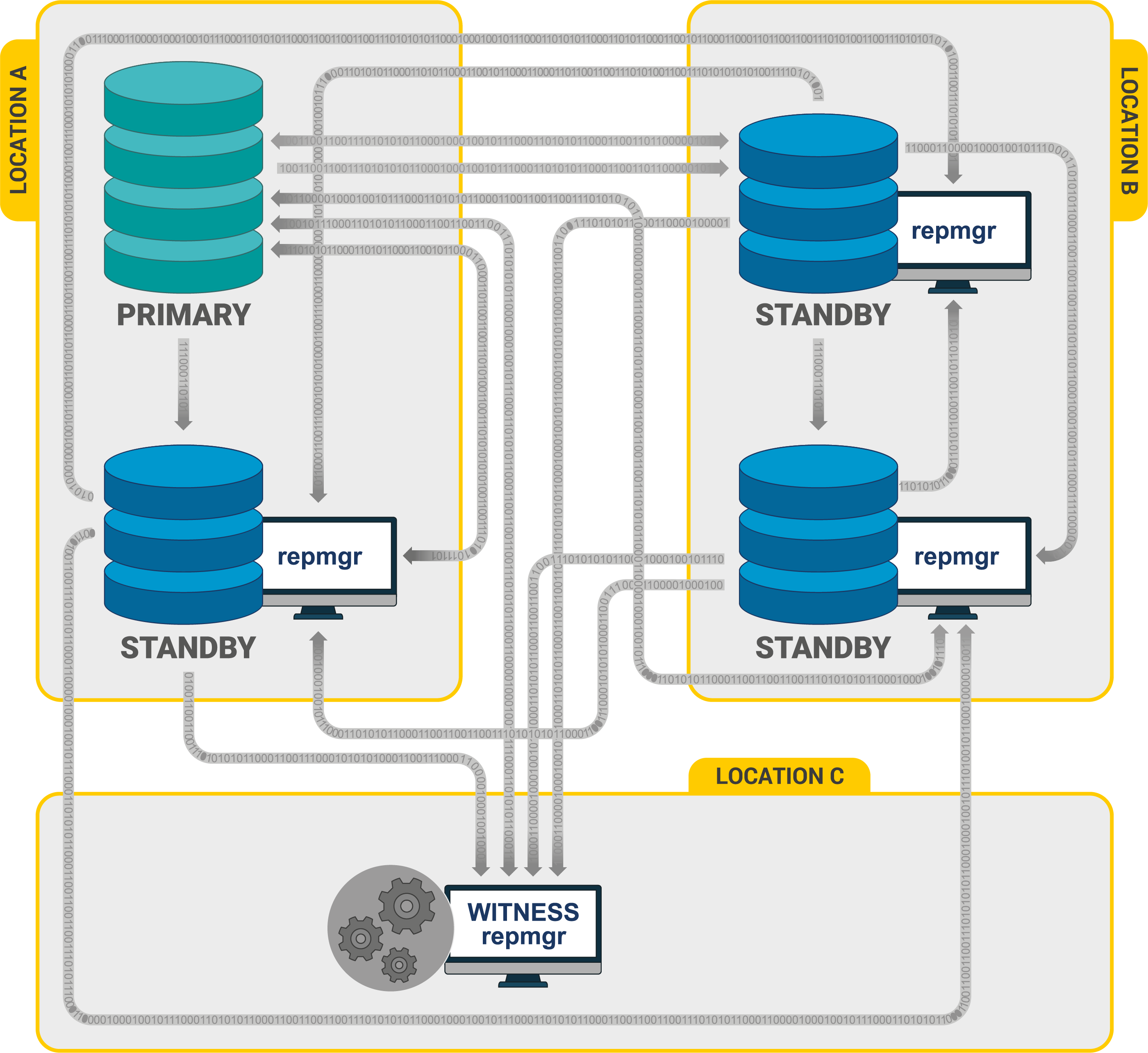 在这里,位置B的待机是位置A完全不可用的情况下的最后一个位置。此处的Witness服务器确保在两个位置之间的网络中断的情况下,位置B处的待机模式不会将其自身升级为主要模式,即阻止脑裂情况。
在这里,位置B的待机是位置A完全不可用的情况下的最后一个位置。此处的Witness服务器确保在两个位置之间的网络中断的情况下,位置B处的待机模式不会将其自身升级为主要模式,即阻止脑裂情况。
翻译自:https://repmgr.org
https://www.2ndquadrant.com/en/resources/repmgr/
By 徐云鹤
这篇关于repmgr简介及配置的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







