本文主要是介绍Hadoop学习笔记(HDP)-Part.12 安装HDFS,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
Part.01 关于HDP
Part.02 核心组件原理
Part.03 资源规划
Part.04 基础环境配置
Part.05 Yum源配置
Part.06 安装OracleJDK
Part.07 安装MySQL
Part.08 部署Ambari集群
Part.09 安装OpenLDAP
Part.10 创建集群
Part.11 安装Kerberos
Part.12 安装HDFS
Part.13 安装Ranger
Part.14 安装YARN+MR
Part.15 安装HIVE
Part.16 安装HBase
Part.17 安装Spark2
Part.18 安装Flink
Part.19 安装Kafka
Part.20 安装Flume
十二、安装HDFS
1.安装libtirpc-devel
HDFS依赖libtirpc-devel,因此需要先安装libtirpc-devel。
创建yml文件,/root/ansible/libtirpc.yml
---
- hosts: allvars:var_package:- libtirpc-devel-0.2.4-0.16.el7.x86_64.rpmtasks:- name: copy install filescopy:src: "/opt/{{ item }}"dest: /root/loop: "{{ var_package }}"- name: install packageshell:cmd: "yum localinstall -y /root/{{ item }}"loop: "{{ var_package }}"- name: delete install filesfile:path: "/root/{{ item }}"state: absentloop: "{{ var_package }}"
执行
ansible-playbook /root/ansible/libtirpc.yml
2.安装服务
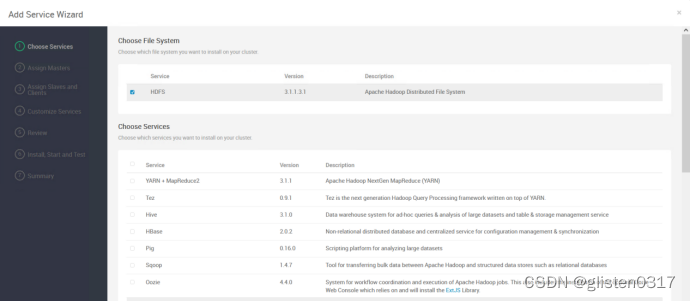
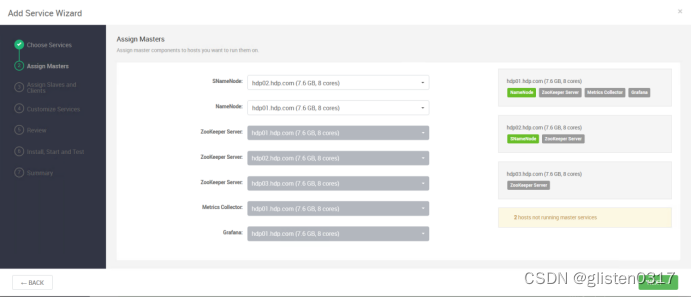
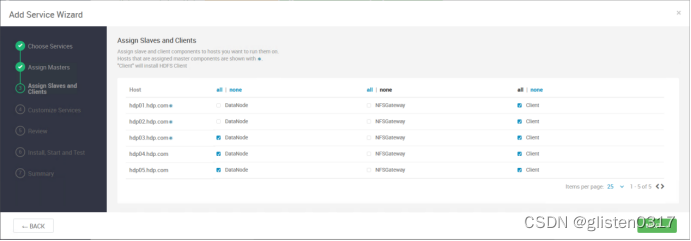
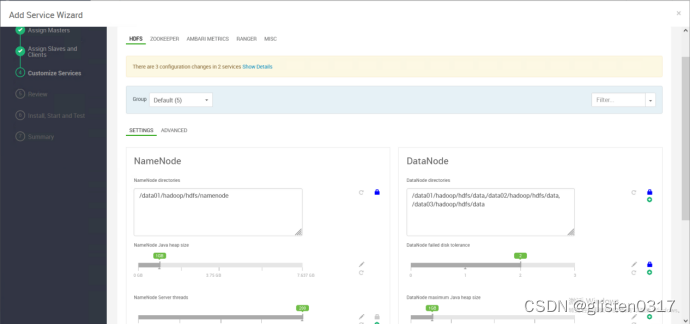
在Serivces->Add Service中添加HDFS服务
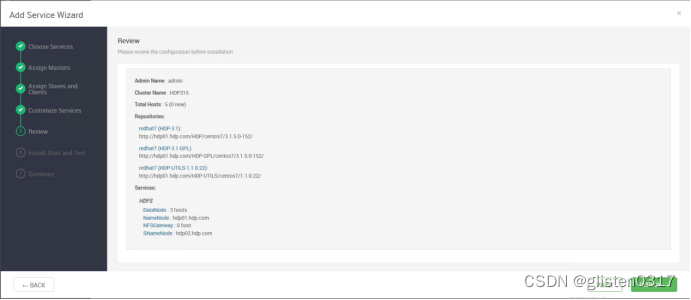
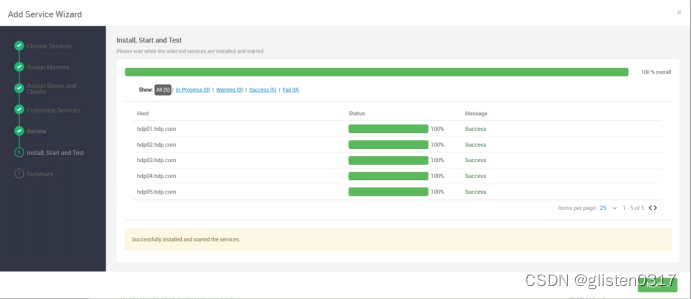
3.namenode HA
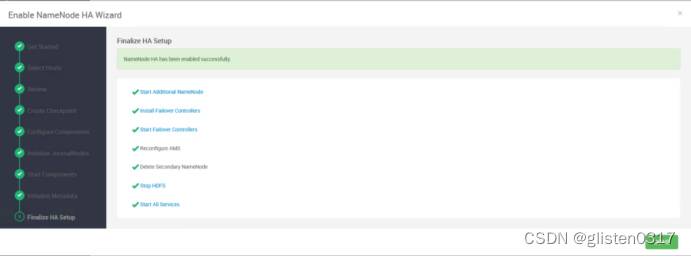
(1)启用HA
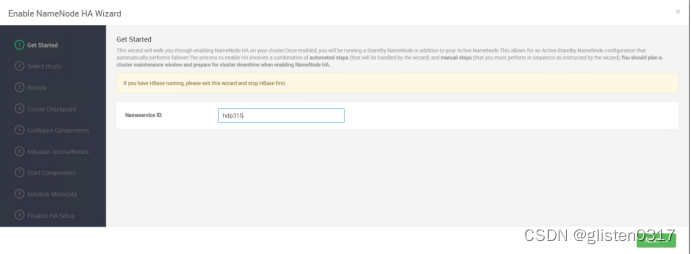
在ACTIONS->Enable NameNode HA中配置
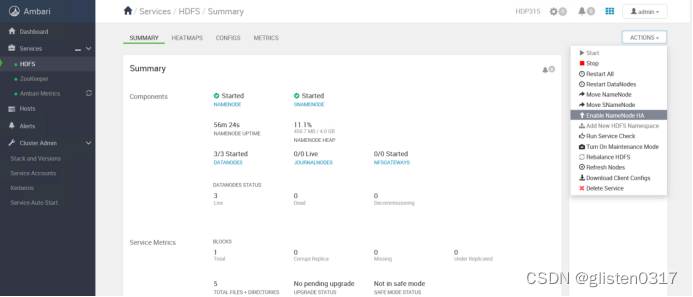
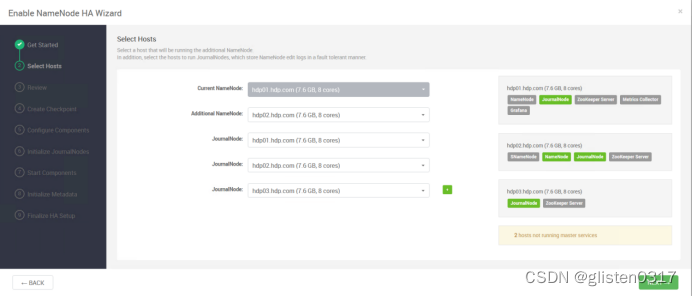
修改JournalNode的路径为/data01/hadoop/hdfs/journal
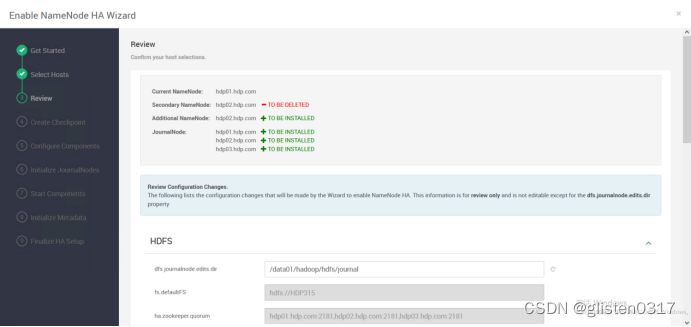
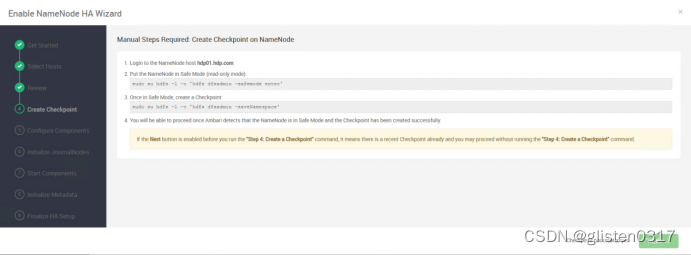
按照提示在hdp01上创建checkpoint
sudo su hdfs -l -c 'hdfs dfsadmin -safemode enter'
sudo su hdfs -l -c 'hdfs dfsadmin -saveNamespace'

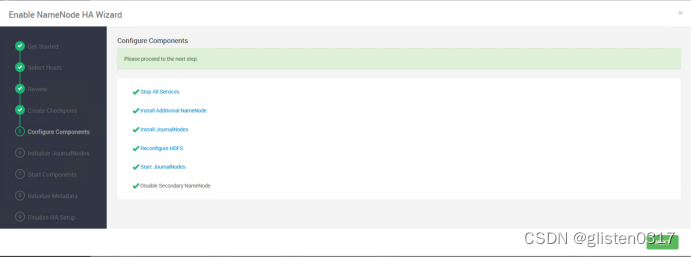
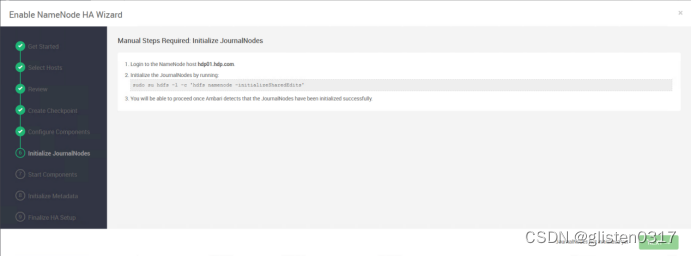
按照提示在hdp01上对JournalNode进行初始化
sudo su hdfs -l -c 'hdfs namenode -initializeSharedEdits'
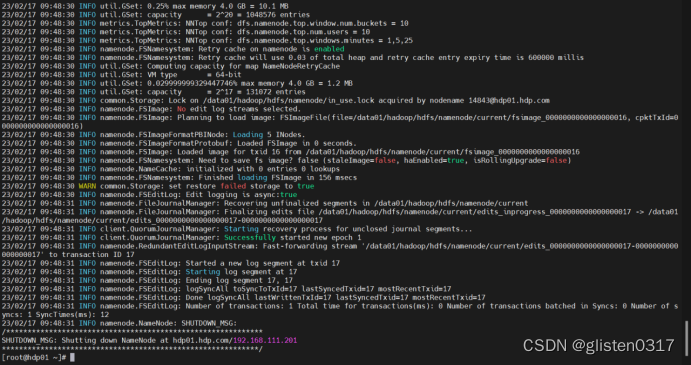
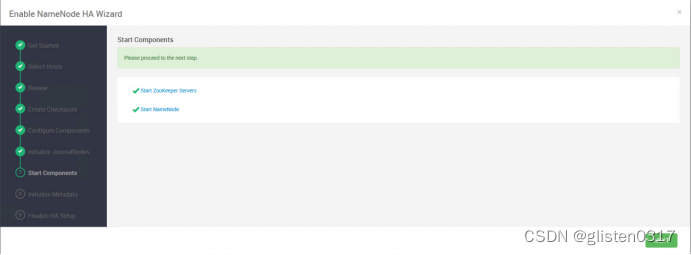
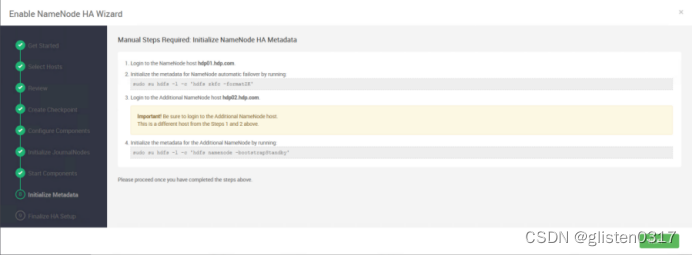
按照提示在hdp01上初始化元数据
sudo su hdfs -l -c 'hdfs zkfc -formatZK'
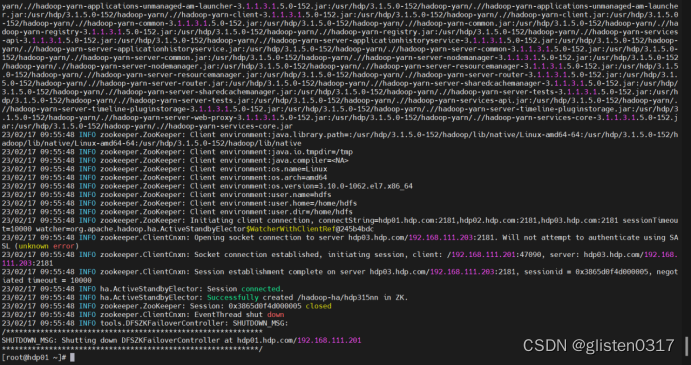
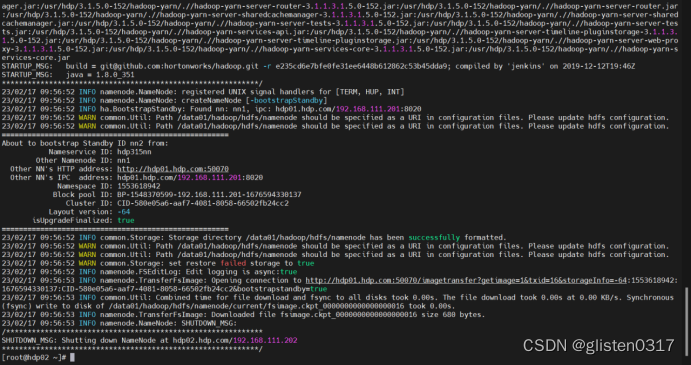
按照提示在hdp02上初始化元数据
sudo su hdfs -l -c 'hdfs namenode -bootstrapStandby'
(2)确认配置文件
/etc/hadoop/conf/core-site.xml,是NameNode的核心配置文件,主要对NameNode的属性进行设置,也仅仅在NameNode节点生效。
nn和2nn时,fs.defaultFS为hdfs://hdp01.hdp.com:8020

改为nn HA后,fs.defaultFS为hdfs://hdp315,以高可用集群出现

| 参数 | 含义 | 配置值 |
|---|---|---|
| fs.defaultFS | 指定访问HDFS文件系统的URI,在HA集群中,此值必须和hdfs-site.xml中的dfs.nameservices配置值一致 | hdfs://hdp315 |
| ha.zookeeper.quorum | ZooKeeper集群的地址和端口。注意,数量一定是奇数,且不少于三个节点 | hdp01.hdp.com:2181,hdp02.hdp.com:2181,hdp03.hdp.com:2181 |
| fs.trash.interval | 定义.trash目录下文件被永久删除前保留的时间。在文件从HDFS永久删除前,用户可以自由地把文件从该目录下移出来并立即还原。默认值0,说明垃圾回收站功能是关闭的,一般开启这个会比较好,以防错误删除重要文件,单位是分钟 | 360 |
4.取消kerberos对页面的认证
正常情况下,kerberos对web页面也会进行认证,可取消掉;如果是对安全较高的场景下,需要在windows电脑上安装kerberos客户端,来实现身份认证,进而登录到web中。
如果未取消认证,会出现如下的界面

取消kerberos认证的配置
HDFS中CONFIGS->ADVANCED中,
Advanced core-site
hadoop.http.authentication.simple.anonymous.allowed:true
Custom core-site
hadoop.http.authentication.type:simple
重启hdfs服务后,namenode页面可以正常打开
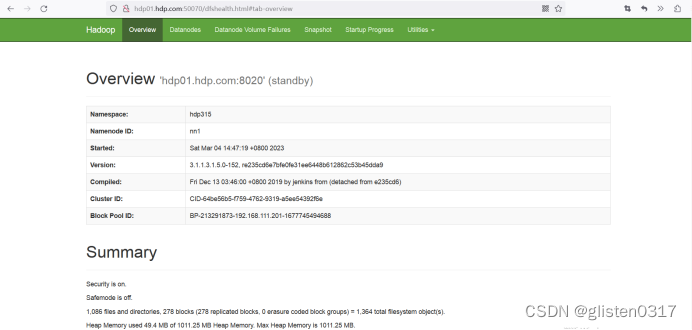
5.确认HDFS配置
(1)hdfs-site.xml文件
/etc/hadoop/conf/hdfs-site.xml,是HDFS的核心配置文件,主要配置NameNode、DataNode的一些基于HDFS的属性信息、在NameNode和DataNode节点生效。
| 参数 | 含义 | 配置值 |
|---|---|---|
| dfs.nameservices | 指定一个逻辑上的HDFS集群服务名,该服务名是自定义的。当外界访问HDFS集群时,入口就是这个服务名 | HDP |
| dfs.ha.namenodes.[nameservice ID] | 指定两个NameNode的唯一标识,名字随便起,相互不重复即可,在HDFS集群管理中会用到 | nn1,nn2 |
| dfs.namenode.rpc-address.[nameservice ID].[name node ID] | 指定nn01、nn02的RPC地址 | hdp01.hdp.com:8020 hdp02.hdp.com:8020 |
| dfs.namenode.http-address.[nameservice ID].[name node ID] | 指定nn01、nn02的http地址 | hdp01.hdp.com:50070 hdp02.hdp.com:50070 |
| dfs.namenode.shared.edits.dir | 指定集群的两个NameNode共享edits文件目录时,使用JournalNode集群的信息 | qjournal://hdp01.hdp.com:8485;hdp02.hdp.com:8485;hdp03.hdp.com:8485/hdp315nn |
| dfs.journalnode.edits.dir | 指定JournalNode集群在对NameNode的元数据目录进行共享时,数据在本地磁盘存储的路径 | /data01/hadoop/hdfs/journal |
| dfs.replication | 指定DataNode存储数据块的副本数量。默认值是3个,现在有3个DataNode,该值不大于3即可 | 3 |
| dfs.ha.fencing.methods | 配置隔离机制,一旦需要NameNode切换,使用shell方式进行操作 | shell(/bin/true) |
| dfs.namenode.name.dir | 用于确定将HDFS文件系统的元信息保存在什么目录下。如果这个参数设置为多个目录,那么这些目录下都保存着元信息的镜像备份,推荐多个磁盘路径存放元数据 | /data01/hadoop/hdfs/namenode |
| dfs.datanode.data.dir | 用于确定将HDFS文件系统的数据存储在本地磁盘哪个目录下。可以将这个参数设置为多个磁盘分区上的不同目录,即可将HDFS数据分布在多个不同磁盘分区上 | /data01/hadoop/hdfs/data,/data02/hadoop/hdfs/data,/data03/hadoop/hdfs/data |
| dfs.permissions.enabled | 表示是否在HDFS中开启权限检查,true表示开启,false表示关闭,生产环境建议开启 | true |
(2)NameNode内存
NameNode的内存计算:
每个文件块大概占用150byte,hdp01-02的内存为8G,能存储的文件块为
810241024*1024/150Byte≈5700万
在ambari上配置后内存后,会同步更新到/etc/hadoop/conf/hadoop-env.sh
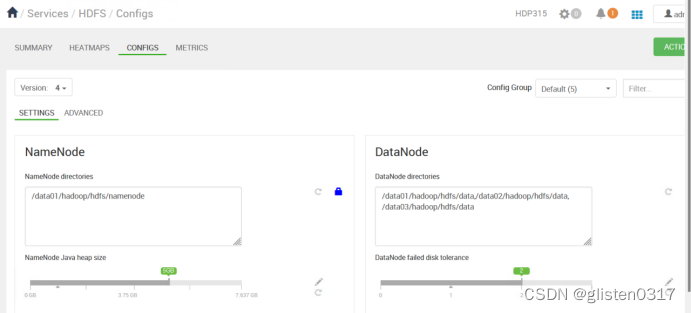

在SETTINGS中将内存设置为5G,然后通过ADVANCED下的Advanced hadoop-env中的参数进行传递
export HADOOP_NAMENODE_INIT_HEAPSIZE=“-Xms{{namenode_heapsize}}”
然后在配置文件hadoop-env.sh中,可以看到内存已经更改为5G
export HADOOP_NAMENODE_INIT_HEAPSIZE=“-Xms5120m”
(3)NameNode心跳
NameNode不仅要应对客户端的请求,还需要对DataNode的心跳进行接收,这些均需要线程
具体在hdfs-site.xml中设置
<property><name>dfs.namenode.handler.count</name><value>21</value></property>
d f s . n a m e n o d e . h a n d l e r . c o u n t = 20 × log e C l u s t e r S i z e dfs.namenode.handler.count = 20\times\log_e^{Cluster Size} dfs.namenode.handler.count=20×logeClusterSize,比如集群规模(DataNode台数)为3台时,此参数设置为21。
(4)ZooKeeper中namenode的配置
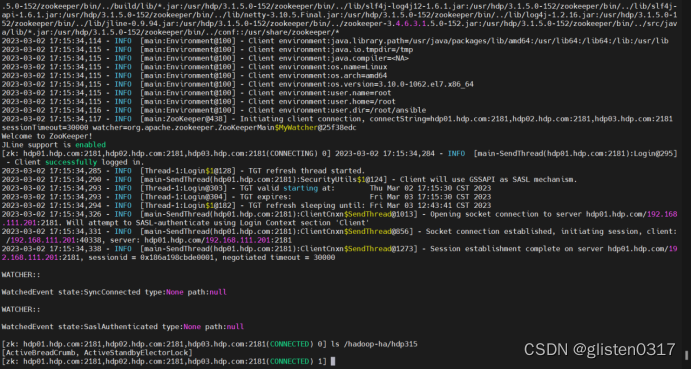
NameNode的HA依赖于ZooKeeper,启用后在zk下会产生节点目录。因为已经开启了kerberos认证,因此在查看前应该先以服务principal登录到kdc上,然后才有权限查看到namenode的目录
kinit -kt /etc/security/keytabs/nn.service.keytab nn/hdp01.hdp.com@HDP315.COM
/usr/hdp/3.1.5.0-152/zookeeper/bin/zkCli.sh -server hdp01.hdp.com:2181,hdp02.hdp.com:2181,hdp03.hdp.com:2181
ls /hadoop-ha/hdp315nn
6.常用命令
因为开启了kerberos认证,所以需要先以这个principal登录,才能进行操作,否则会报错`

kinit -kt /etc/security/keytabs/nn.service.keytab nn/hdp01.hdp.com@HDP315.COM
(1)直接操作
①mkdir:创建路径
hdfs dfs -mkdir /testhdfs
②ls: 显示目录信息
hdfs dfs -ls /
③cat:显示文件内容
hdfs dfs -cat /testhdfs/test0219.txt
④chmod、chown:更改权限及归属
hdfs dfs -chmod 777 /testhdfs/test0219.txt
hdfs dfs -chown hdfs:hadoop /testhdfs/test0219.txt
⑤cp:从HDFS的一个路径拷贝到HDFS的另一个路径
hdfs dfs -cp /testhdfs/test0219.txt /testhdfs/tmp/
⑥rm:删除文件或文件夹
hdfs dfs -rm /testhdfs/tmp/test0219.txt
⑦mv:在HDFS目录中移动文件
hdfs dfs -mv /testhdfs/test0219.txt /testhdfs/tmp/
⑧tail:显示一个文件的末尾1kb的数据
hdfs dfs -tail /testhdfs/tmp/test0219.txt
⑨rm -r:递归删除目录及目录里面内容
hdfs dfs -rm -r /testhdfs/tmp/
⑩du:统计文件夹的大小信息
第一列标示该目录下总文件大小
第二列标示该目录下所有文件在集群上的总存储大小和你的副本数相关,默认副本数是3,所以第二列的是第一列的三倍(第二列内容=文件大小*副本数)
hdfs dfs -du -s -h /testhdfs
hdfs dfs -du -s -h /testhdfs/test0219.txt

⑪setrep:设置HDFS中文件的副本数量
hdfs dfs -setrep 10 /testhdfs/test0219.txt

(2)上传文件
①moveFromLocal:把本地的文件剪切到HDFS上
hdfs dfs -moveFromLocal /home/hdfs/test0219.txt /testhdfs/
将hdfs家目录下的test0219.txt上传到HDFS根目录下的testhdfs文件夹
②copyFromLocal:将本地文件复制到HDFS上
hdfs dfs -copyFromLocal /home/hdfs/test0219-1.txt /testhdfs/
③put:等同于copyFromLocal,生产环境更习惯用put
hdfs dfs -put /home/hdfs/test0219-2.txt /testhdfs/
④AppendToFile:将一个本地文件的内容追加到一个HDFS文件末尾
hdfs dfs -appendToFile /home/hdfs/test0219-2.txt /testhdfs/test0219-1.txt
(3)下载文件
①copyToLocal:将HDFS上文件复制到本地目录上
hdfs dfs -copyToLocal /testhdfs/test0219.txt /home/hdfs/
②get:等同于copyToLocal,生产环境更习惯用get
hdfs dfs -get /testhdfs/test0219.txt /home/hdfs/
7.常见错误
(1)namenode启动失败
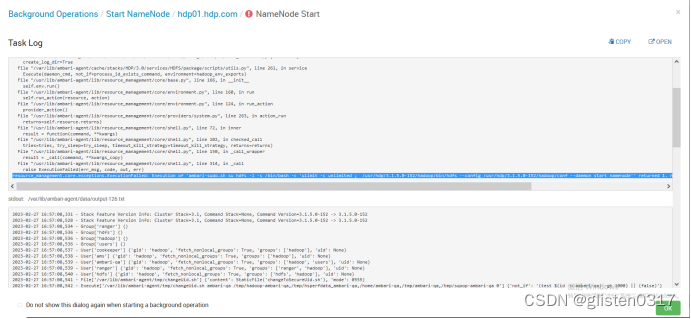
查看50070端口是否被占用,如被占用则kill掉
(2)HA后namenode重启报错
启用HA后重启namenode遇到报错:
resource_management.core.exceptions.ExecutionFailed: Execution of 'ambari-sudo.sh su hdfs -l -s /bin/bash -c 'ulimit -c unlimited ; /usr/hdp/3.1.5.0-152/hadoop/bin/hdfs --config /usr/hdp/3.1.5.0-152/hadoop/conf --daemon start namenode'' returned 1. namenode is running as process 15506. Stop it first.
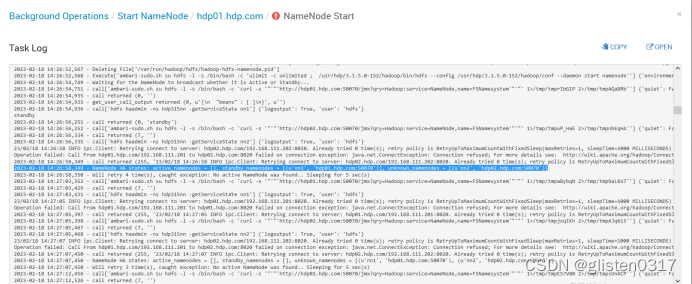
查看日志/var/log/hadoop/hdfs/hadoop-hdfs-namenode-hdp01.log,确认为journalnode问题
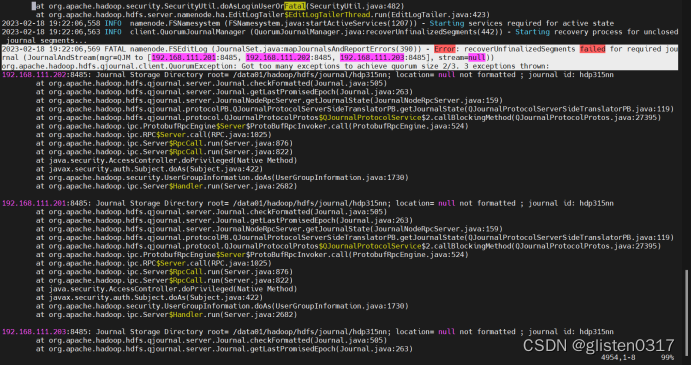
查看journalnode日志,发现目录没有格式化
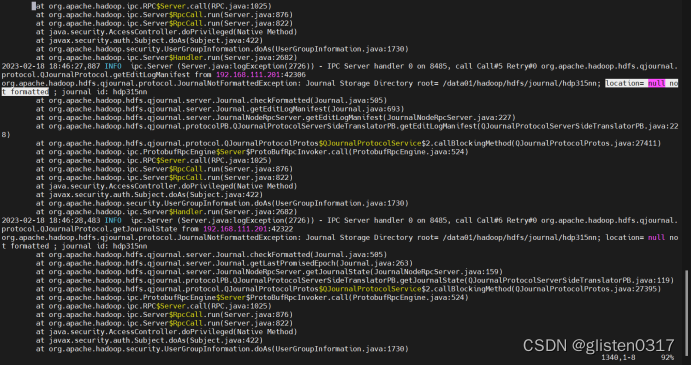
查看/data01/hadoop/hdfs/journal/下文件,发现为空,需要重新格式化
hdfs namenode -initializeSharedEdits
再次启动namenode后仍报错
再次查看日志/var/log/hadoop/hdfs/hadoop-hdfs-namenode-hdp01.log,
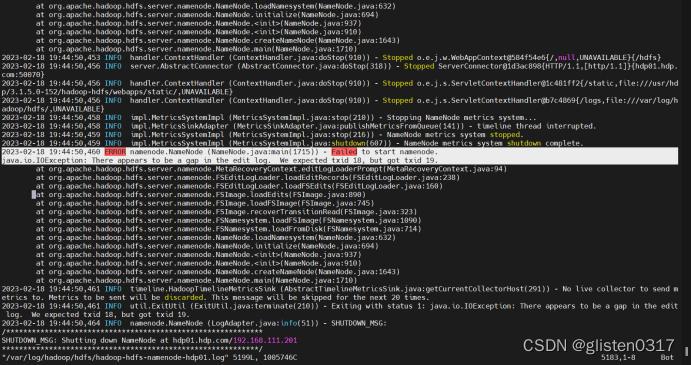
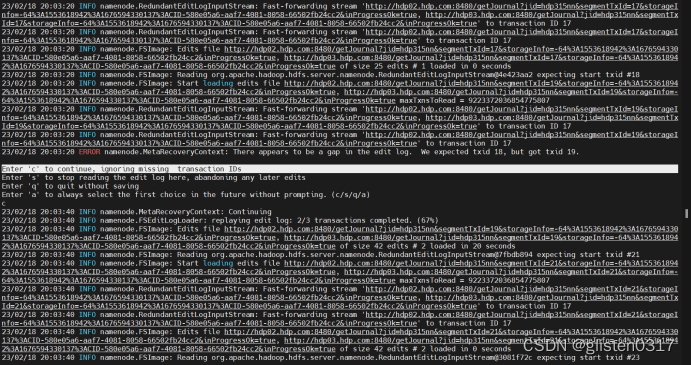
说明namenode元数据发生损坏,需要恢复元数据后,才能启动namenode。恢复过程中,遇到提示有错误的时候,按c继续恢复即可
/usr/hdp/3.1.5.0-152/hadoop/bin/
hadoop namenode -recover
这篇关于Hadoop学习笔记(HDP)-Part.12 安装HDFS的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









