本文主要是介绍告别 Microsoft SQL Server, 迎接 Babelfish,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

我们许多客户都表示不希望与专有数据库供应商合作,从而避免昂贵的成本开支以及繁琐的许可条款。但是,从旧式商用数据库迁移出来可能需要耗费大量时间和资源。迁移数据库时,可使用 Amazon Schema Conversion Tool 和 Amazon Database Migration Service 自动迁移数据库模式和数据。然而,迁移应用程序本身需要完成更多的工作量,包括重写与数据库交互的应用程序代码。主动性足够,但成本和风险往往是限制性因素。
如今, Babelfish for Aurora PostgreSQL 问世。有了 Babelfish,Amazon Aurora PostgreSQL 兼容版将能够理解 SQL Server 线路协议。这一工具让您以更低的成本、更快的速度将 SQL Server 应用程序迁移到 PostgreSQL, 迁移相关风险也更小。
在传统迁移所需的一部分时间内就可迁移完应用程序。您将继续使用应用程序目前所用的现有查询和驱动程序。只需将应用程序指向已激活 Babelfish 的 Amazon Aurora PostgreSQL 数据库即可。使用 Babelfish,Amazon Aurora PostgreSQL 将能理解 SQL Server 线路协议表格数据流 ( TDS ),并使 PostgreSQL 能够理解 SQL Server 使用的常用 T-SQL 命令。对 T-SQL 的支持包括 SQL 方言、静态游标、数据类型、触发器、存储过程和函数等元素。Babelfish 显著减少了应用程序所需的更改次数,从而降低了与数据库迁移项目相关的风险。采用 Babelfish 可节省使用 SQL Server 时的许可成本。Amazon Aurora 可以实现商用数据库的安全性、可用性和可靠性,而成本只有商用数据库的十分之一。
虽然 SQL Server 已经发展了 30 多年,但我们估计它短期内也不会支持所有功能。然而,我们将专注于最常见的 T-SQL 命令并返回正确的响应或错误消息。例如,在 SQL Server(精度为四位小数)和 PostgreSQL(精度为两位小数)中,MONEY 数据类型具有不同的特征。这种细微的差别可能会导致四舍五入的错误,并对财务报告等下游流程产生重大影响。在这种情况以及许多其他情况下,Babelfish 将确保保留 SQL Server 数据类型的语义和 T-SQL 功能:我们创建了一个其行为符合 SQL Server 应用程序要求的 MONEY 数据类型。通过 Babelfish 连接创建具有此数据类型的表时,将获得符合 SQL Server 应用程序要求的此兼容数据类型和行为。
使用控制台创建 Babelfish 集群
为了展示 Babelfish 的工作原理,我们首先连接到控制台并创建新的 Amazon Aurora PostgreSQL 集群。该过程与常规 Amazon Aurora 数据库的过程没有区别。在 Amazon RDS Launch Wizard 中,首先要确保选择与 PostgreSQL 13.4 兼容的 Amazon Aurora 版本或更新版本。更新后的控制台具有附加筛选器,可帮助选择与 Babelfish 兼容的版本。
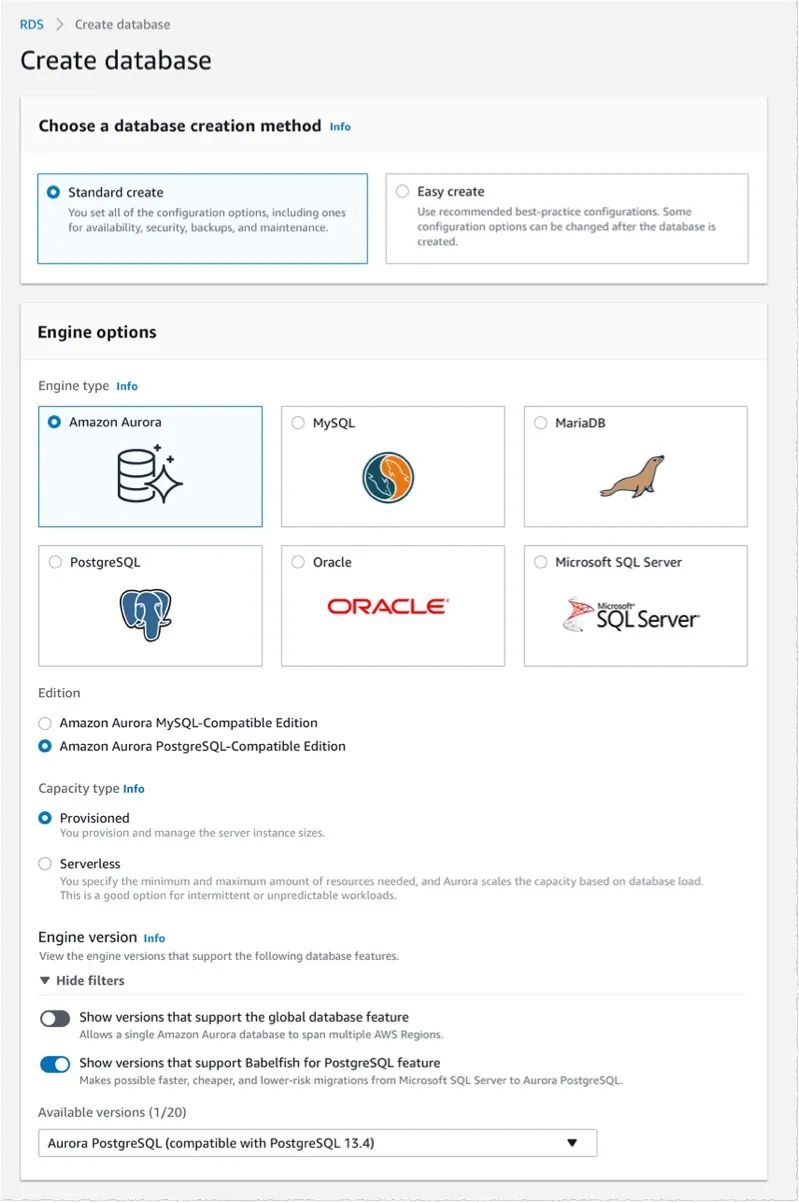
然后,在页面下方,选择选项 Turn on Babelfish(打开 Babelfish)。
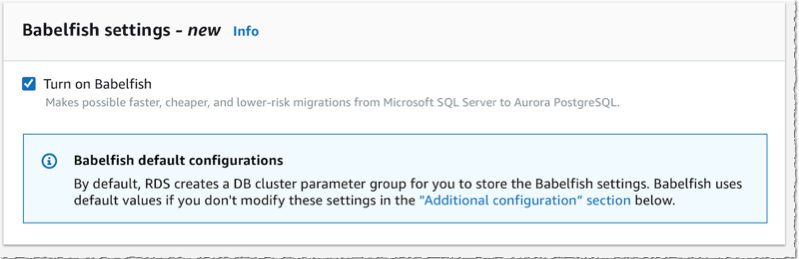
在监控部分,还要确保关闭了启用增强监控。此选项需要另外的 IAM 权限和准备工作(本演示中未介绍)。

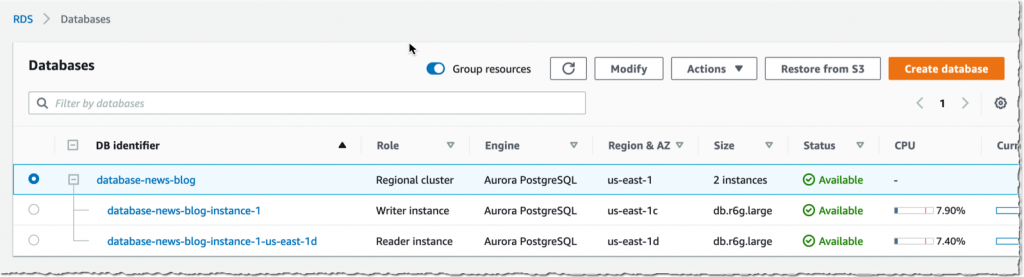
几分钟后,集群创建完毕,其中包括两个实例,一个写入器和一个读取器。
使用 Amazon CLI 创建 Babelfish 集群
或者,可以使用 Amazon CLI 创建集群。首先创建参数组来激活 Babelfish(控制台会自动执行):
aws rds create-db-cluster-parameter-group \--db-cluster-parameter-group-name myapp-babelfish \--db-parameter-group-family aurora-postgresql13 \--description "babelfish APG 13"
aws rds modify-db-cluster-parameter-group \--db-cluster-parameter-group-name myapp-babelfish \--parameters "ParameterName=rds.babelfish_status,ParameterValue=on,ApplyMethod=pending-reboot" \*左滑查看更多
然后创建数据库集群(使用下面的命令时,调整安全组 ID 和子网组名称):
aws rds create-db-cluster \--db-cluster-identifier awsnewblog-cli-demo \--master-username postgres \ --master-user-password Passw0rd \--engine aurora-postgresql \--engine-version 13.4 \--vpc-security-group-ids sg-abcd1234 \--db-subnet-group-name default-vpc-1234abcd \--db-cluster-parameter-group-name myapp-babelfish
{"DBCluster": {"AllocatedStorage": 1,"AvailabilityZones": ["us-east-1c","us-east-1d","us-east-1a"],"BackupRetentionPeriod": 1,"DBClusterIdentifier": "awsnewblog-cli-demo","Status": "creating",... <redacted for brevity> ...}
}*左滑查看更多
创建集群后,使用以下命令创建实例
aws rds create-db-instance \--db-instance-identifier myapp-db1 \--db-instance-class db.r5.4xlarge \--db-subnet-group-name default-vpc-1234abcd \--db-cluster-identifier awsnewblog-cli-demo \--engine aurora-postgresql
{"DBInstance": {"DBInstanceIdentifier": "myapp-db1","DBInstanceClass": "db.r5.4xlarge","Engine": "aurora-postgresql","DBInstanceStatus": "creating",... <redacted for brevity> ...*左滑查看更多
连接到 Babelfish 集群
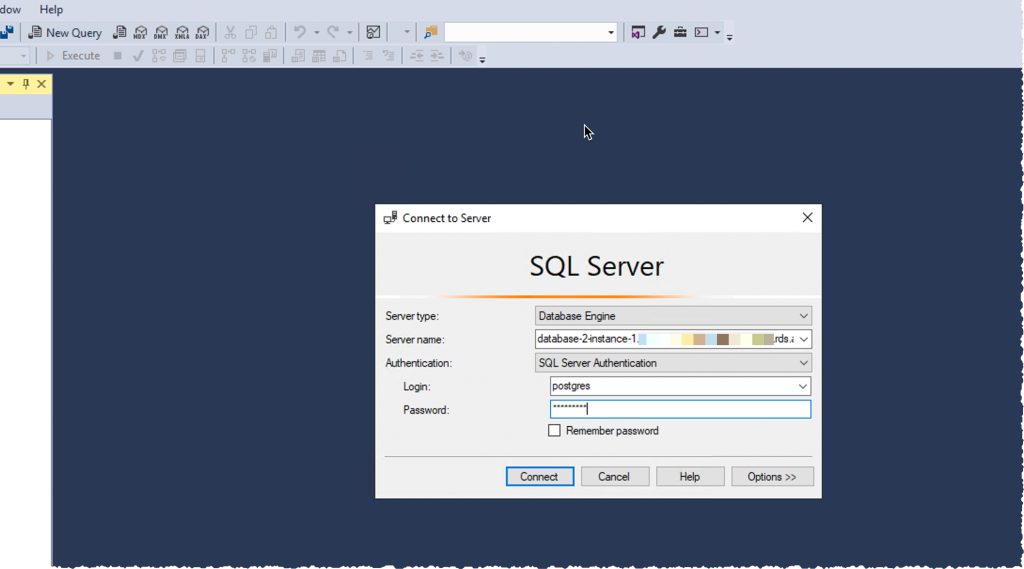
集群和实例准备就绪后,将与写入器实例连接以创建数据库本身。可以使用 SQL Server Management Studio (SSMS) 或其他 SQL 客户端(如 sqlcmd)连接到实例。Windows 客户端必须能够连接到 Babelfish 集群,确保 RDS 安全组授权来自 Windows 主机的连接。
在 Windows 上使用 SSMS 时,在工具栏中选择新查询,然后输入数据库 Amazon DNS 名称,并将其作为服务器名称。 选择 SQL Server 身份验证,然后输入数据库登录名和密码。点击连接。
重要提示:请勿通过 SSMS 对象资源管理器进行连接。请务必通过新查询按钮使用查询编辑器进行连接。目前,Babelfish 支持查询编辑器,但不支持对象资源管理器。
连接后,使用 select @@version 语句检查版本,然后点击工具栏中的绿色执行按钮。阅读屏幕底部的语句检查结果。

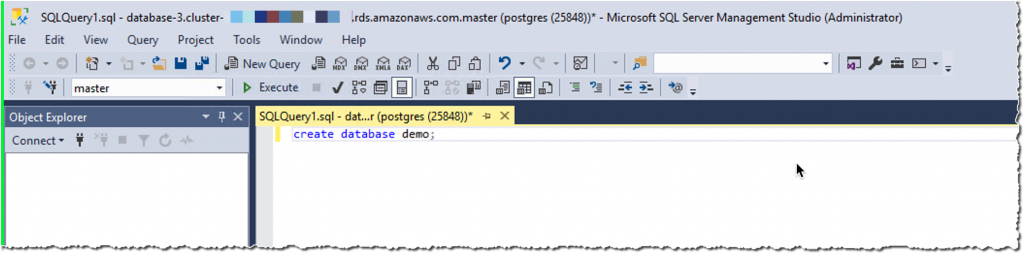
最后,使用 create database demo 语句在实例上创建数据库。
默认情况下,Babelfish 在单数据库模式下运行。在这种模式下,每个实例最多可以有一个用户数据库。这种情况允许在 SQL Server 和 PostgreSQL 之间建立一个紧密的模式名称映射。或者,可以在创建集群时打开多数据库模式。这一操作可让您为每个实例创建多个用户数据库。在 PostgreSQL 中,用户数据库被映射到多个模式,并将数据库名称作为前缀。
运行应用程序
为了演示,将使用 SQLServerTutorial.net 提供的数据库模式作为其 SQL Server 教程的一部分来创建模式并用数据填充。在此演示中使用的 SQL 脚本和应用程序 C# 代码可在我的 GitHub 存储库中找到。非常感谢同事 Auja 提供 C# 演示应用程序。
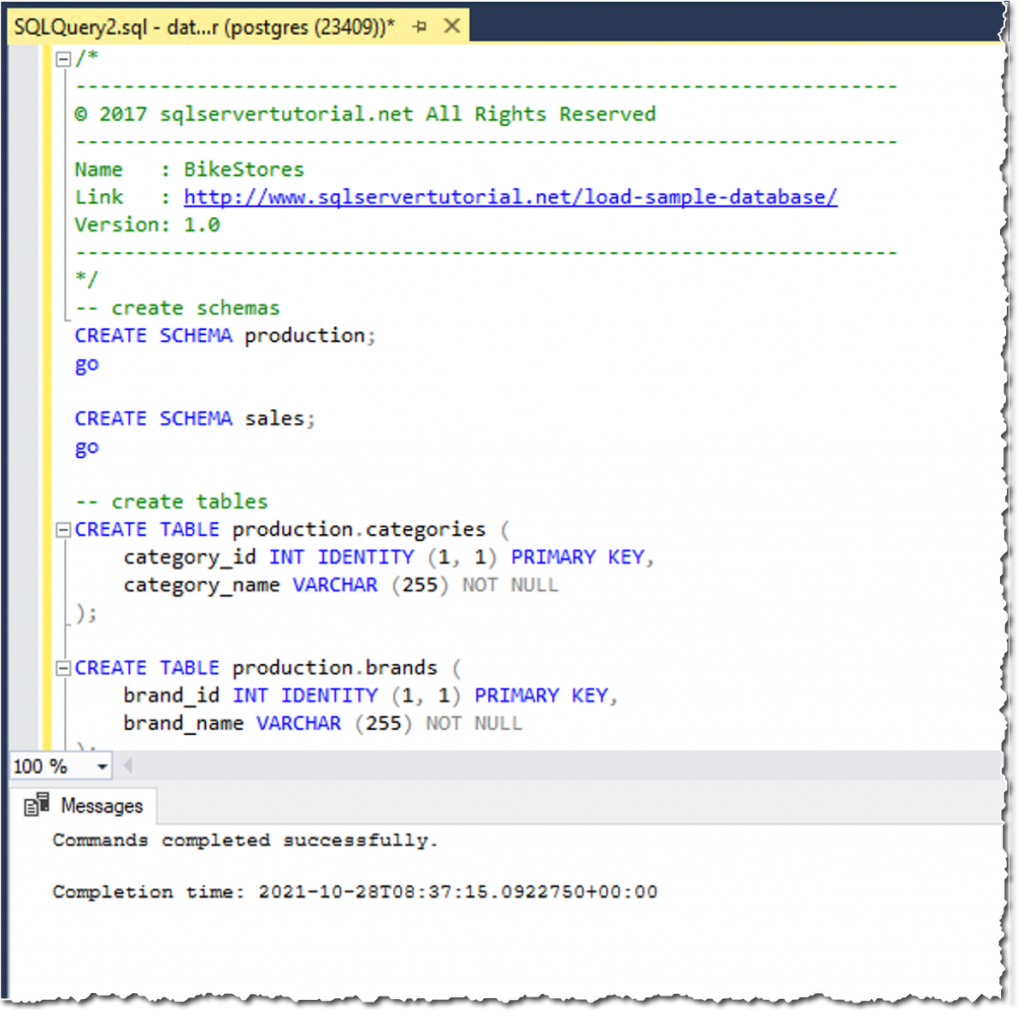
在 SQL Server Management Studio 中,打开 create_objects.sql 脚本,然后选择顶部工具栏上的绿色执行图标。出现一条确认消息提示数据库模式已创建。
使用 load_data.sql 脚本重复此操作,以便在新创建的表中加载数据。数据加载需要几分钟才能运行。
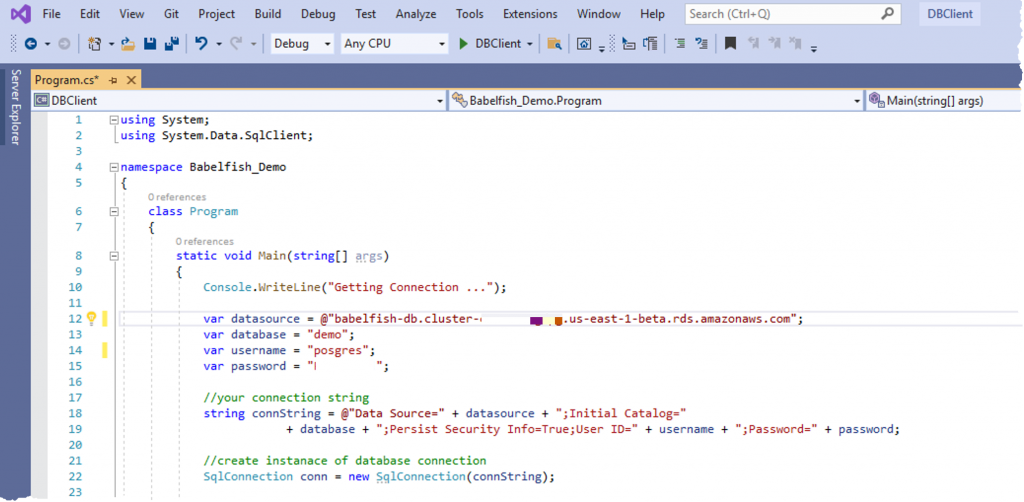
现在数据库已经加载完毕,打开 Auja 提供的为访问 SQL Server 数据库而开发的 C# 应用程序。修改两行代码:
第 12 行:键入之前创建的 Babelfish 集群的 Amazon DNS 名称。请注意,使用了集群中“写入”节点的 Amazon DNS 名称。
第 15 行:键入创建数据库集群时输入的密码。
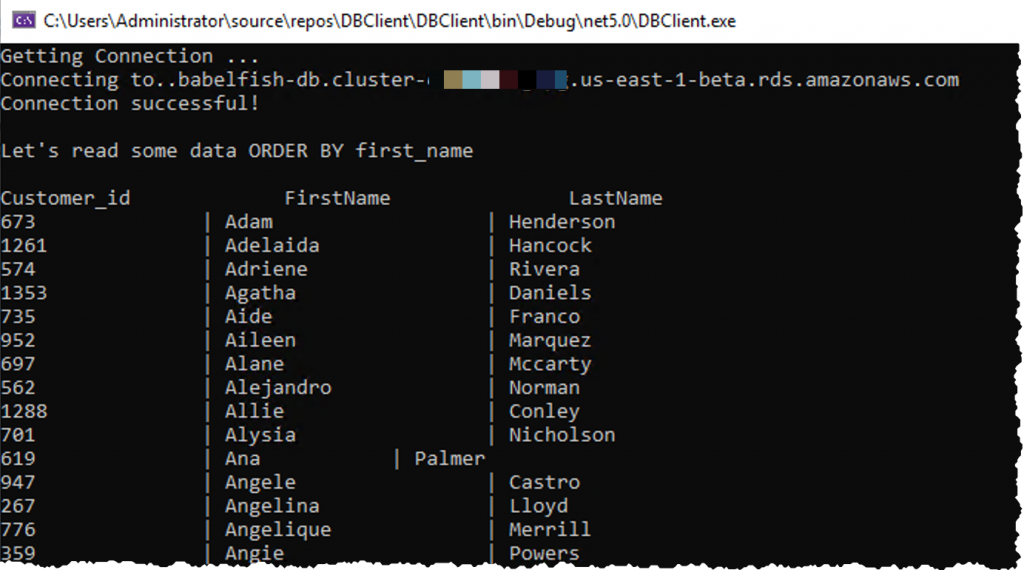
就是这么简单!此应用程序无需进行其他修改。这段用于查询和与 SQL Server 交互而编写的代码只是在使用了 Babelfish 的 Amazon Aurora PostgreSQL 上按原样工作。
开源透明度
我们决定对 Babelfish 背后的技术开源以创建适合 PostgreSQL 的 Babelfish 开源项目。它将使用宽松的 Apache 2.0 和 PostgreSQL 许可证,这意味着可以按照自己认为合适的方式修改、调整或分发 Babelfish。随着时间的推移,我们正在将 Babelfish 转为在 GitHub 上全开放开发,因此从一开始就十分透明。如今,无论您是不是 AWS 客户,任何人都可以使用 Babelfish 代替 SQL Server,快速、轻松且经济高效地将应用程序迁移到开源 PostgreSQL。我们相信,Babelfish 将让更广泛的客户和开发人员能够使用 PostgreSQL,尤其是那些最初为 SQL Server 编写了大量复杂应用程序的客户和开发人员。
可用性
适用于 Aurora PostgreSQL 的 Babelfish 今天在所有公开可用的亚马逊云科技区域上市,不收取额外费用。
PS:如果想知道 Babelfish 这个名字的由来,请记住答案是 42。或者点击下方 “阅读原文” 寻找更多关于答案的线索。
本篇作者

Sébastien Stormacq
自从在八十年代中期首次接触 Commodore 64 以来,Seb 一直在编写代码。他激励构建人员,利用自己的激情、热心、以客户为中心的态度、好奇心和创造力,发掘亚马逊云科技云的价值。他的兴趣包括软件架构、开发工具和移动计算。

扫描上方二维码即刻注册

听说,点完下面4个按钮
就不会碰到bug了!
这篇关于告别 Microsoft SQL Server, 迎接 Babelfish的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








