本文主要是介绍Dinky之安装部署与基本使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Dinky之安装部署与基本使用
- Dinky概览
- Linux安装部署
- 解压到指定目录
- 初始化MySQL数据库
- 修改配置文件
- 加载依赖
- 启动Dinky
- Docker部署
- 启动dinky-mysql-server镜像
- 启动dinky-standalone-server镜像
- Dinky的基本使用
- 上传jar包
- Flink配置
- 集群管理
- 集群实例管理
- 集群配置管理
- 创建作业
- 语句编写与作业配置
- 发布运行作业
- 查看作业运行情况
- Dinky的其他功能服务
- Catalog
- 变量
- FlinkSQL环境
- 数据源
- 元数据中心
Dinky概览
Dinky是一个开箱即用的一站式实时计算平台以Apache Flink为基础,连接OLAP和数据湖等众多框架致力于流批一体和湖仓一体的建设与实践。
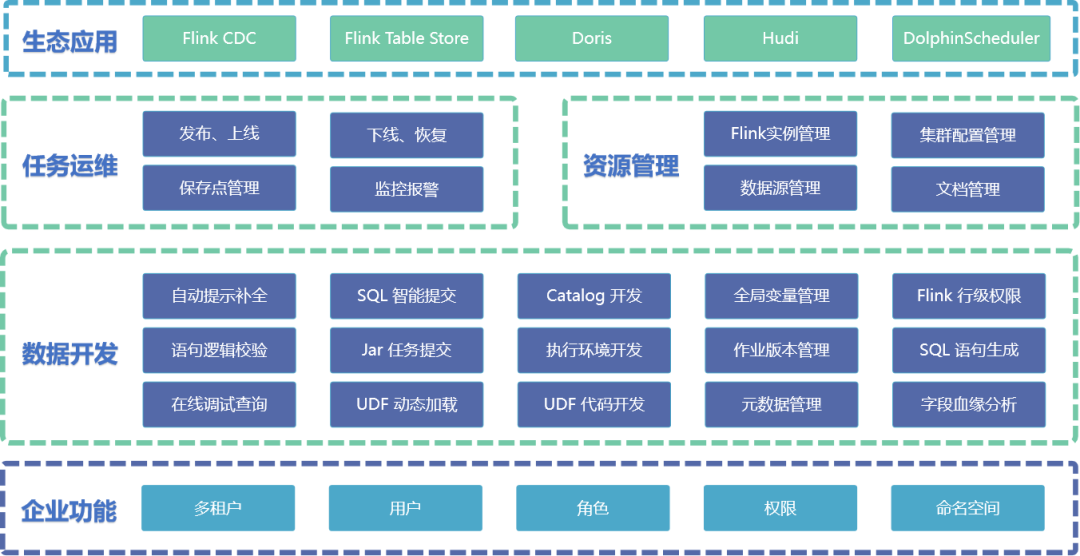
主要功能:
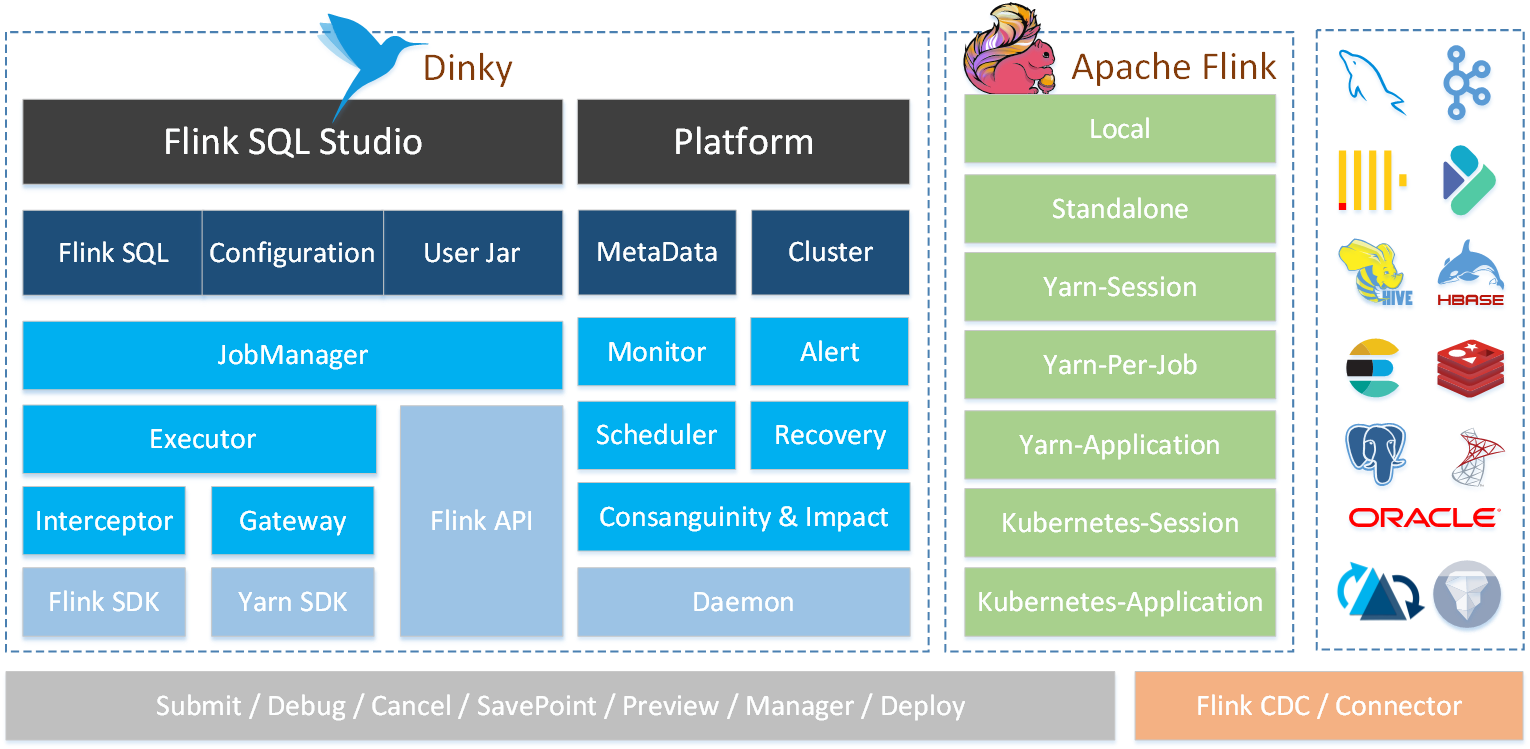
原理:
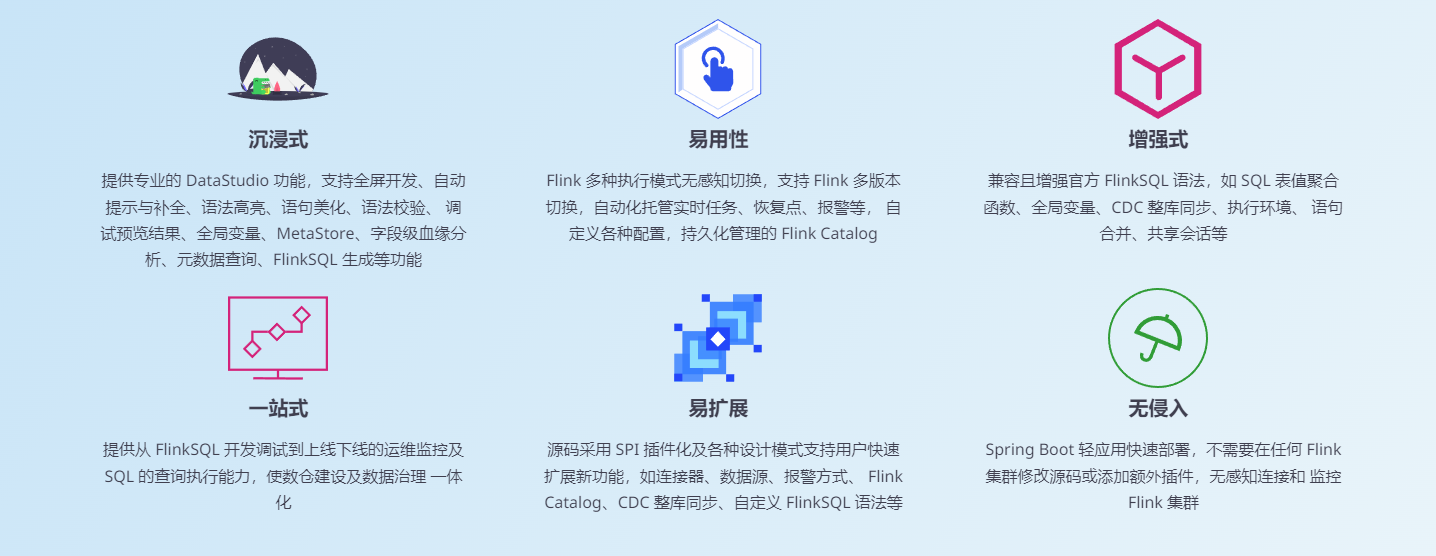
核心特性:
官网:http://www.dlink.top/
GitHub:https://github.com/DataLinkDC/dinky
文档:http://www.dlink.top/docs/next/get_started/quick_experience/
Linux安装部署
解压到指定目录
Dinky不依赖任何外部环境,完全解耦,支持同时连接多个不同的集群实例进行运维。
下载地址:https://github.com/DataLinkDC/dinky/releases
wget https://github.com/DataLinkDC/dinky/releases/download/v0.7.3/dlink-release-0.7.3.tar.gz
上传安装包并解压
tar -zxvf dlink-release-0.7.3.tar.gz -C /usr/local/programmv dlink-release-0.7.3 dinkycd dinky
初始化MySQL数据库
Dinky采用mysql作为后端的存储库,Dinky部署需要MySQL5.7 以上版本,需要创建Dinky的后端数据库,执行初始化sql文件
在Dinky/sql目录下分别放置了dinky.sql 、 upgrade/${version}_schema/mysql/mysql_ddl
如果第一次部署,直接执行sql/dinky-mysql.sql 如果之前已经部署,根据版本号执行upgrade目录下存放的相应版本升级sql
#登录mysql
mysql -uroot -p123456#创建数据库
create database dinky;# 切换数据库
use dinky;# 执行初始化sql文件
source /usr/local/program/dinky/sql/dinky.sql
修改配置文件
cd dinky/configvim ./application.yml
修改Dinky连接 mysql 的配置文件
spring:datasource:url: jdbc:mysql://${MYSQL_ADDR:node01:3306}/${MYSQL_DATABASE:dinky}?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&useSSL=false&zeroDateTimeBehavior=convertToNull&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=trueusername: ${MYSQL_USERNAME:root}password: ${MYSQL_PASSWORD:123456}driver-class-name: com.mysql.cj.jdbc.Driverapplication:name: dlink
加载依赖
Dinky需要具备自身的Flink环境,该Flink环境的实现需要用户自己在Dinky根目录下
plugins/flink${FLINK_VERSION}文件夹并上传相关的Flink依赖。
下载Flink
wget https://repo.huaweicloud.com/apache/flink/flink-1.17.0/flink-1.17.0-bin-scala_2.12.tgz
解压Flink
tar -zxvf flink-1.17.0-bin-scala_2.12.tgz
加载Flink依赖
对应 Flink 版本的依赖,放在Dinky 安装目录下 plugins/flink${FLINK_VERSION}下
cp flink-1.17.0/lib/* dinky/plugins/flink1.17/
加载Hadoop依赖
注意:Dinky当前版本的yarn的perjob与application执行模式依赖flink-shade-hadoop,需要额外添加flink-shade-hadoop-uber-3包。对于dinky来说,Hadoop3的uber依赖可以兼容hadoop2。
wget https://repository.cloudera.com/artifactory/cloudera-repos/org/apache/flink/flink-shaded-hadoop-3-uber/3.1.1.7.2.9.0-173-9.0/flink-shaded-hadoop-3-uber-3.1.1.7.2.9.0-173-9.0.jar
放到dinky/plugins目录
共享的JAR包放plugins目录,否则放不同版本的Flink目录下
cp flink-shaded-hadoop-3-uber-3.1.1.7.2.9.0-173-9.0.jar dinky/plugins/
启动Dinky
#启动
sh auto.sh start# 启动指令的第二个参数则是版本选择
sh auto.sh start 1.17#停止
sh auto.sh stop#重启
sh auto.sh restart 1.17#查看状态
sh auto.sh status# 查看启动日志信息
tail -f logs/dlink.log -n 200
服务启动后,默认端口 8888,访问:http://127.0.0.1:8888
默认用户名/密码: admin/admin
Docker部署
启动dinky-mysql-server镜像
Dinky采用mysql作为后端的存储库,启动该镜像提供Dinky的MySQL业务库能力
docker run --name dinky-mysql dinkydocker/dinky-mysql-server:0.7.2
出现以下日志,则启动成功
2023-07-12T08:47:52.930058Z 0 [Note] mysqld: ready for connections.
Version: '5.7.41' socket: '/var/run/mysqld/mysqld.sock' port: 3306 MySQL Community Server (GPL)
如果有mysql 服务,执行对应版本的SQL文件即可。
docker run --restart=always -p 8888:8888 -p 8081:8081 -e MYSQL_ADDR=IP:3306 --name dinky dinkydocker/dinky-standalone-server:0.7.2-flink14
启动dinky-standalone-server镜像
提供Dinky实时计算平台
docker run --restart=always -p 8888:8888 -p 8081:8081 -e MYSQL_ADDR=dinky-mysql:3306 --name dinky --link dinky-mysql:dinky-mysql dinkydocker/dinky-standalone-server:0.7.2-flink14
出现以下日志,则启动成功
Dinky pid is not exist in /opt/dinky/run/dinky.pid
FLINK VERSION : 1.14
........................................Start Dinky Successfully........................................
........................................Restart Successfully........................................
Dinky的基本使用
上传jar包
当Flink使用YARN运行模式中的Application模式部署时,需要将flink和dinky相关依赖包上传到HDFS
1.上传dinky的JAR包
# 创建HDFS目录
hadoop fs -mkdir -p /dinky/jar/hadoop fs -put /usr/local/program/dinky/jar/dlink-app-1.17-0.7.3-jar-with-dependencies.jar /dinky/jar
2.上传flink的JAR包
# 创建HDFS目录
hadoop fs -mkdir /flink/jarhadoop fs -put /usr/local/program/flink/lib /flink/jarhadoop fs -put /usr/local/program/flink/plugins /flink/jar
Flink配置
当使用 Application 模式以及 RestAPI 时,需要修改相关Flink配置。提交FlinkSQL 的Jar文件路径指向:上传到HDFS中的Dinky的JAR包
hdfs://node01:9000/dinky/jar/dlink-app-1.17-0.7.3-jar-with-dependencies.jar

集群管理
提交FlinkSQL作业时,首先要保证安装了Flink集群。Flink当前支持的集群模式包括:Standalone 集群、Yarn 集群、Kubernetes 集群Dinky提供了两种集群管理方式,一种是集群实例管理,一种是集群配置管理。
集群实例管理
Dinky推荐在使用 Yarn Session、K8s Session、StandAlone类型时采用集群实例的方式注册集群,其他类型的集群只能查看作业信息。对于已经注册的集群实例,可以对集群实例做编辑、删除、搜索、心跳检测和回收等。
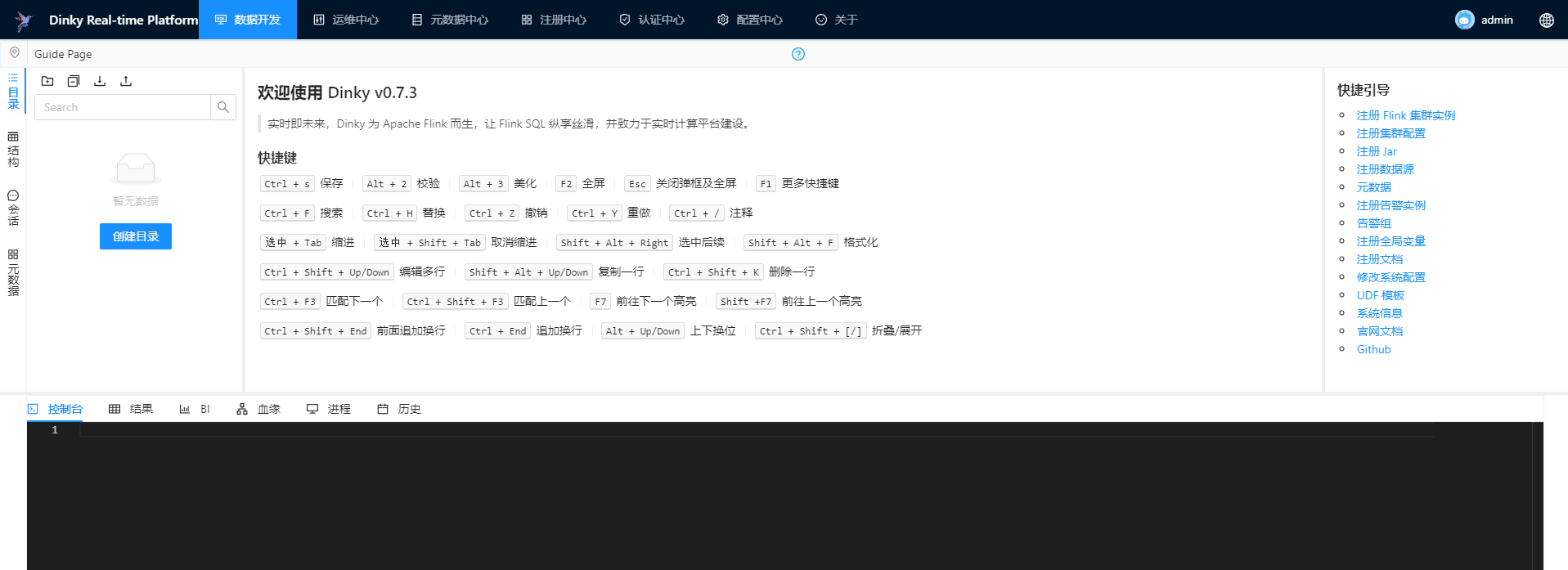
1.注册Standalone集群
启动Flink的Standalone模式
[root@node01 flink]# bin/start-cluster.sh
注册集群
配置成功则显示正常:

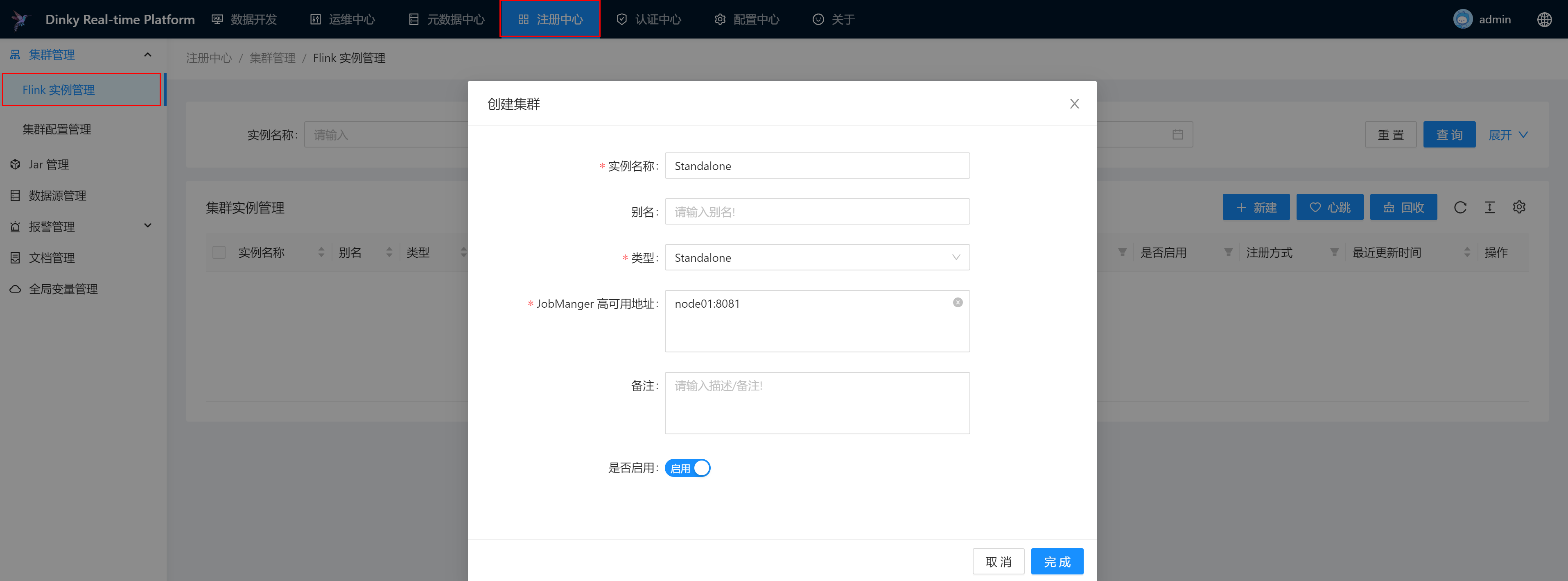
2.注册Yarn Session集群
启动Flink的YARN运行模式
[root@node01 flink]# bin/yarn-session.sh -d
启动日志如下,关注日志信息: Found Web Interface node02:42628 of application 'application_1689258255717_0002'.
2023-07-13 22:50:08,081 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Cannot use kerberos delegation token manager, no valid kerberos credentials provided.
2023-07-13 22:50:08,088 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Submitting application master application_1689258255717_0002
2023-07-13 22:50:08,393 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImpl [] - Submitted application application_1689258255717_0002
2023-07-13 22:50:08,393 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Waiting for the cluster to be allocated
2023-07-13 22:50:08,396 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Deploying cluster, current state ACCEPTED
2023-07-13 22:50:12,939 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - YARN application has been deployed successfully.
2023-07-13 22:50:12,939 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface node02:42628 of application 'application_1689258255717_0002'.
JobManager Web Interface: http://node02:42628
2023-07-13 22:50:13,131 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli [] - The Flink YARN session cluster has been started in detached mode. In order to stop Flink gracefully, use the following command:
$ echo "stop" | ./bin/yarn-session.sh -id application_1689258255717_0002
If this should not be possible, then you can also kill Flink via YARN's web interface or via:
$ yarn application -kill application_1689258255717_0002
Note that killing Flink might not clean up all job artifacts and temporary files.
注册集群,根据提示输入相应信息:
配置成功则显示正常:

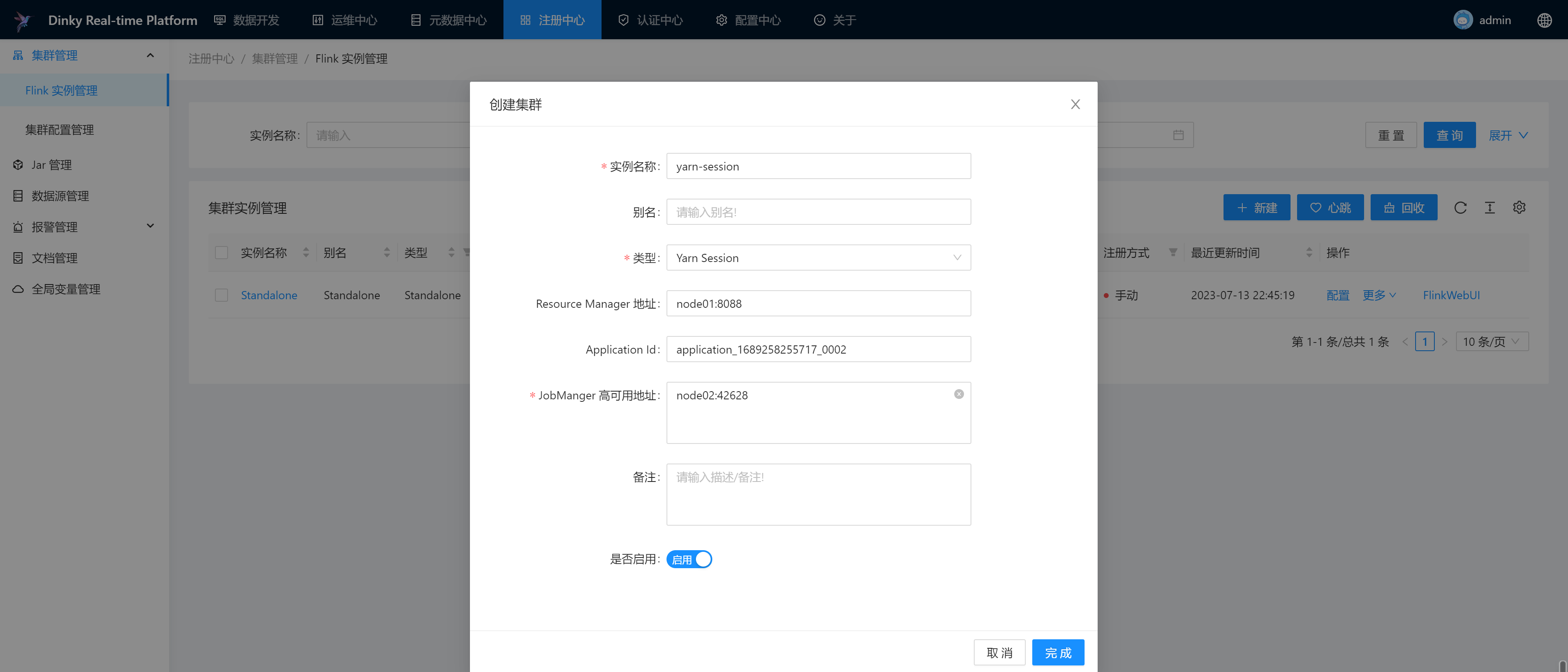
集群配置管理
Dinky推荐在使用Yarn Per Job、Yarn Application、K8s Application类型时采用集群配置的方式注册集群。对于已经注册的集群配置,可以对集群配置做编辑、删除和搜索等
填写核心参数:
Hadoop配置文件路径:/usr/local/program/hadoop/etc/hadoop,指服务器Hadoop配置路径lib路径:hdfs://node01:9000/flink/jar,指HDFS中包含Flink运行时依赖JAR的路径Flink配置文件路径:/usr/local/program/flink/conf,指服务器Flink的配置文件路径
点击测试,测试连接成功,则代表配置无问题
创建作业
创建一个目录demo,选中右键,创建作业,类型选择FlinkSql。创建完成后,就可以在作业下编写SQL及配置作业参数

语句编写与作业配置
当FlinkSQL编写完成后,即可进行作业的配置。在作业配置中,可以选择作业执行模式、Flink 集群、SavePoint策略等配置,对作业进行提交前的配置。
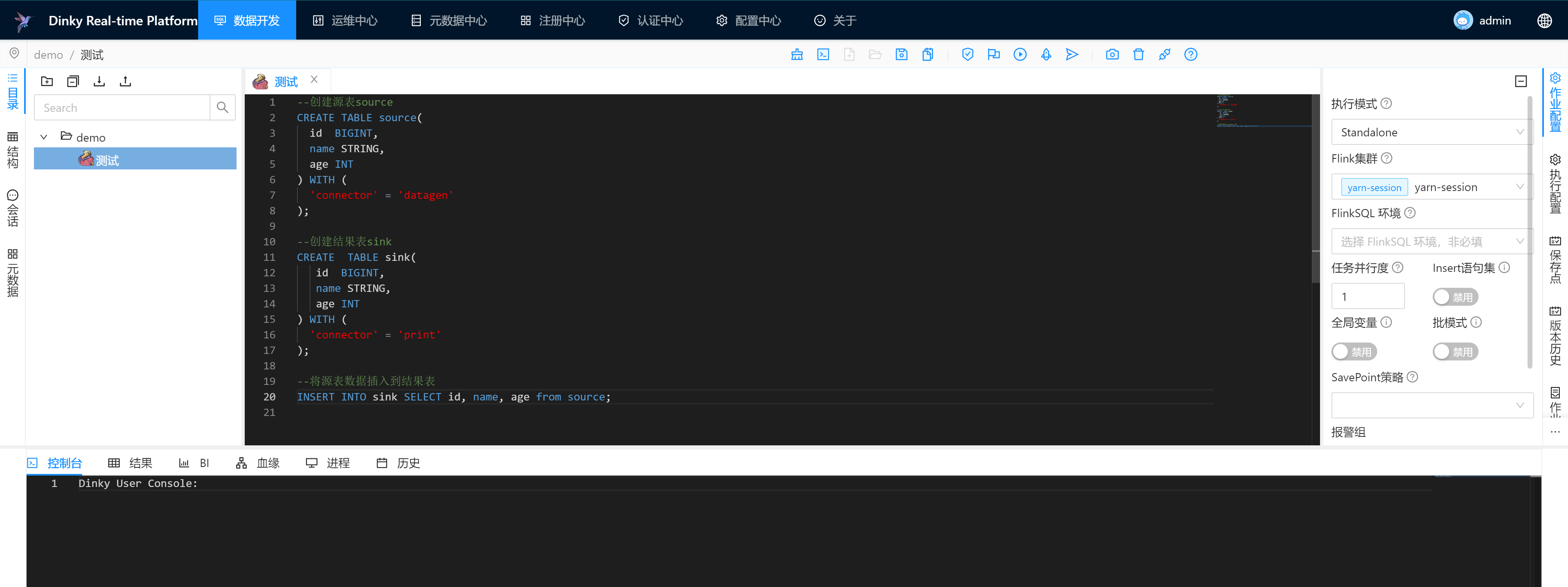
作业SQL
--创建源表source
CREATE TABLE source(id BIGINT,name STRING,age INT
) WITH ('connector' = 'datagen'
);--创建结果表sink
CREATE TABLE sink(id BIGINT,name STRING,age INT
) WITH ('connector' = 'print'
);--将源表数据插入到结果表
INSERT INTO sink SELECT id, name, age from source;
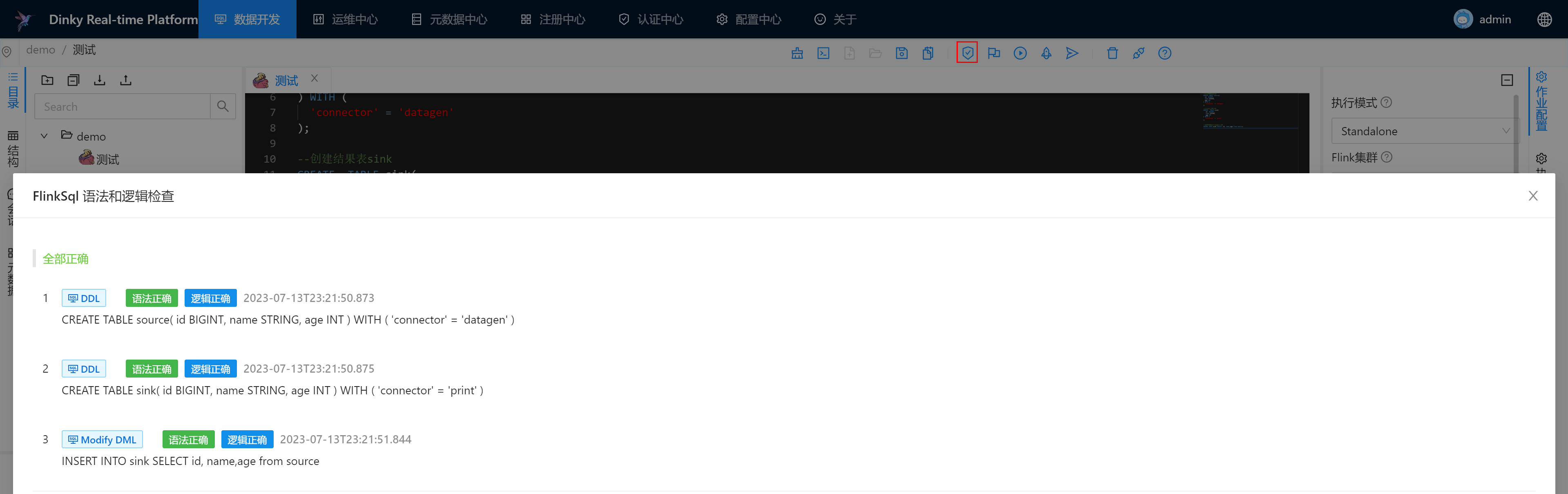
语法检查
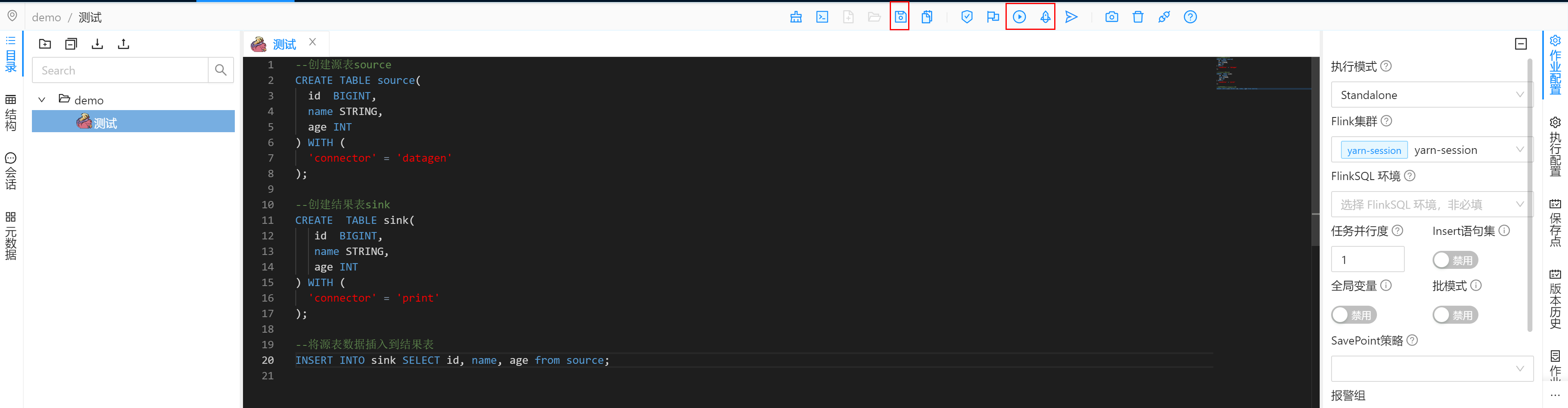
发布运行作业
保存后,选择执行SQL或者提交作业
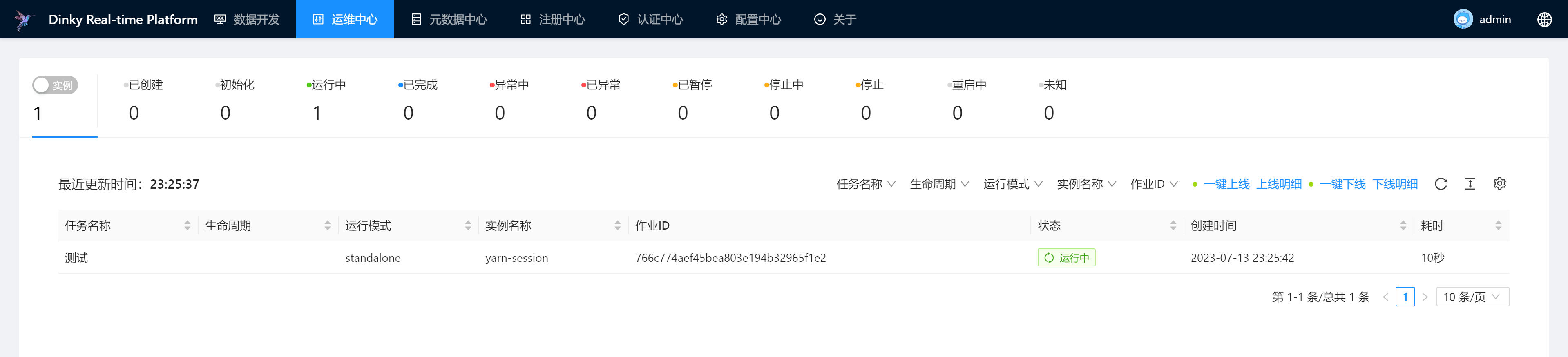
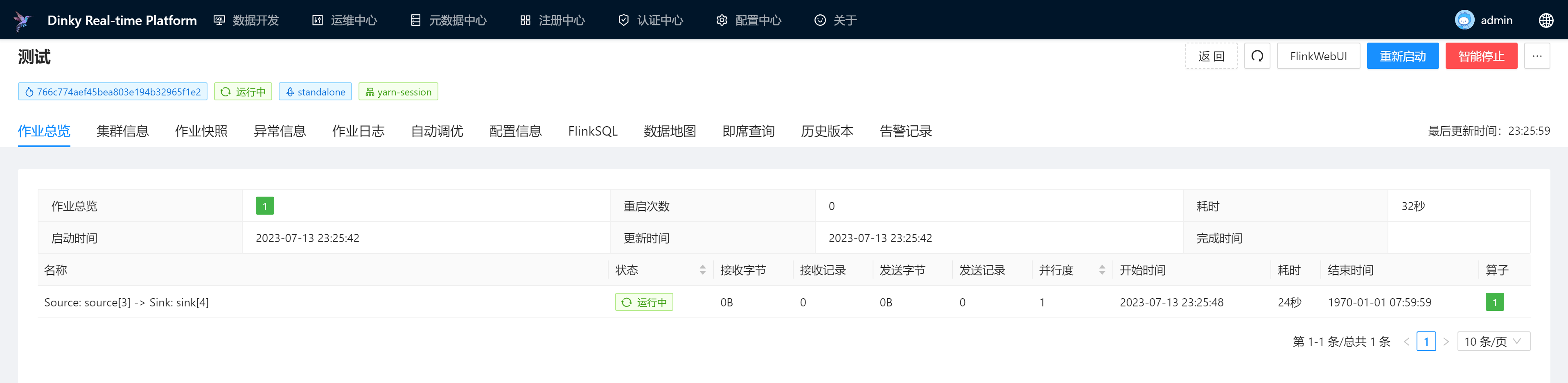
查看作业运行情况
提交执行后,可以到运维中心查看作业的运行情况。
Dinky的其他功能服务
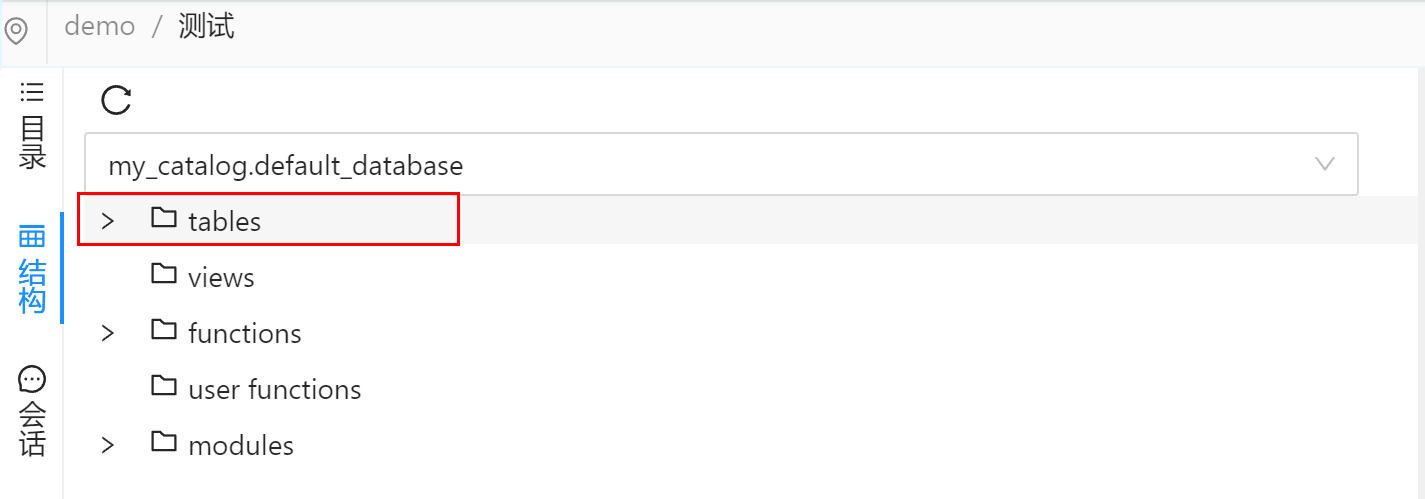
Catalog
Dinky可以利用MySQL持久化Flink元数据,只需要在FlinkSQL的作业配置中选择DefaultCatalog,即可使用MySQL来存储,否则Flink采用基于内存catalog
Mysql Catalog 持久化目前默认的Catalog为my_catalog,默认的FlinkSQLEnv为DefaultCatalog。
将元数据信息保存到 Mysql以后,可以查看MySQL元数据、使用Mysql Catalog,即在作业中无需再显式声明DDL 语句,如建表操作。

变量
1.局部变量
定义变量的语法如下:
key1 := value1;
定义及使用变量
-- 定义变量
myKey := source;-- 使用变量
select * from ${myKey};
还需要在作业配置中开启全局变量

2.全局变量
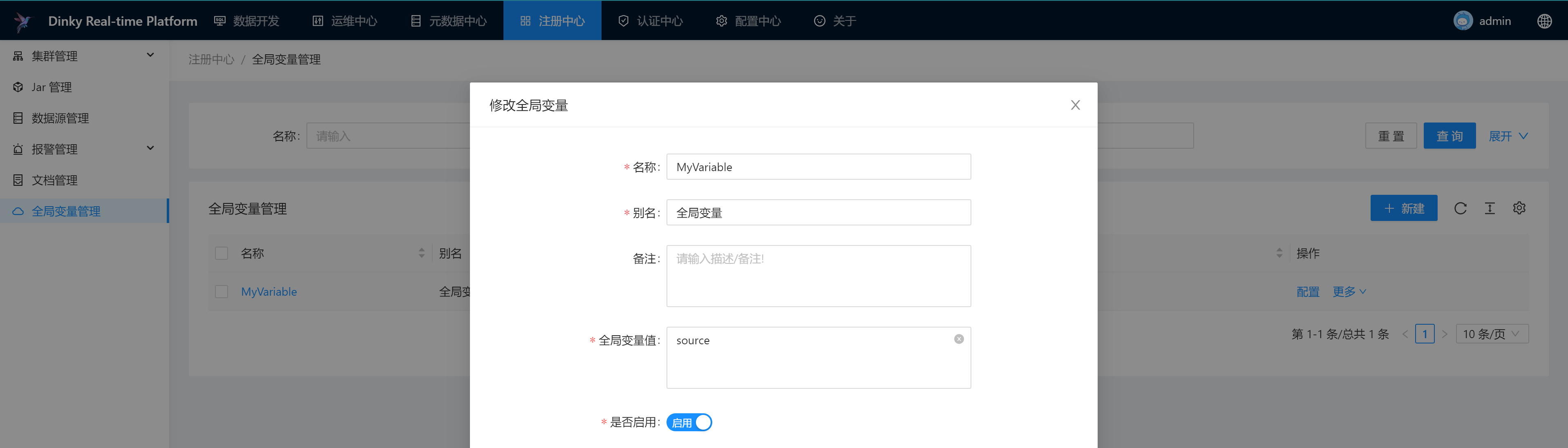
执行使用全局变量
-- 使用全局变量
select * from ${MyVariable};
3.查看变量
-- 定义变量
myKey := source;-- 查看单个变量
SHOW FRAGMENT myKey;-- 查看所有变量
SHOW FRAGMENTS;
FlinkSQL环境
在执行 FlinkSQL 时,会先执行FlinkSqlEnv 内的语句。适用于所有作业的SET、DDL语法统一管理的场景。
新建作业,类型选择FlinkSqlEnv
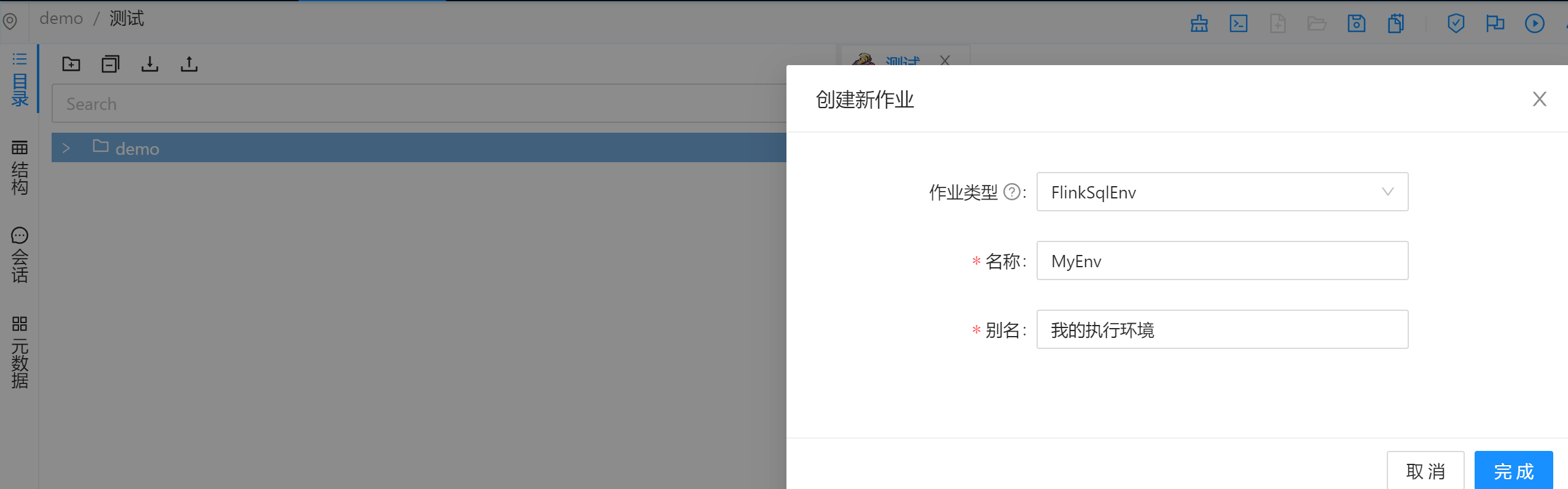
定义一些执行环境变量

使用自定义FlinkSQL环境

数据源
创建数据源

配置参考示例:

Flink 连接配置:
避免私密信息泄露,同时作为全局变量复用连接配置,在FlinkSQL中可使用 ${名称} 来加载连接配置,如 ${ods}。说明:名称指的是英文唯一标识,即如图所示的名称。注意需要开启全局变量(原片段机制)
'hostname' = 'localhost','port' = '3306','username' = 'root','password' = '123456','server-time-zone' = 'UTC'
Flink 连接模板:
Flink连接模板作用是为生成 FlinkSQL DDL而扩展的功能。
注意引用变量的前后逗号,使用此方式作业右侧必须开启全局变量${schemaName} 动态获取数据库,${tableName} 动态获取表名称
'connector' = 'mysql-cdc','hostname' = 'localhost','port' = '3306','username' = 'root','password' = '123456','server-time-zone' = 'UTC','scan.incremental.snapshot.enabled' = 'true','debezium.snapshot.mode'='latest-offset' ,'database-name' = '${schemaName}','table-name' = '${tableName}'
注意:
定义数据源的名称可以作为的变量键,定义数据源的Flink连接配置可以作为变量的值

元数据中心
当对数据源配置完成后,可以查看表的详细信息与对应的建表语句,查看建表语句功能很实用
具体操作: 数据开发->左侧点击 元数据->选中当前创建的数据源 -> 展开库 -> 右键单击 表名 -> 点击 SQL生成 -> 查看FlinkDDL
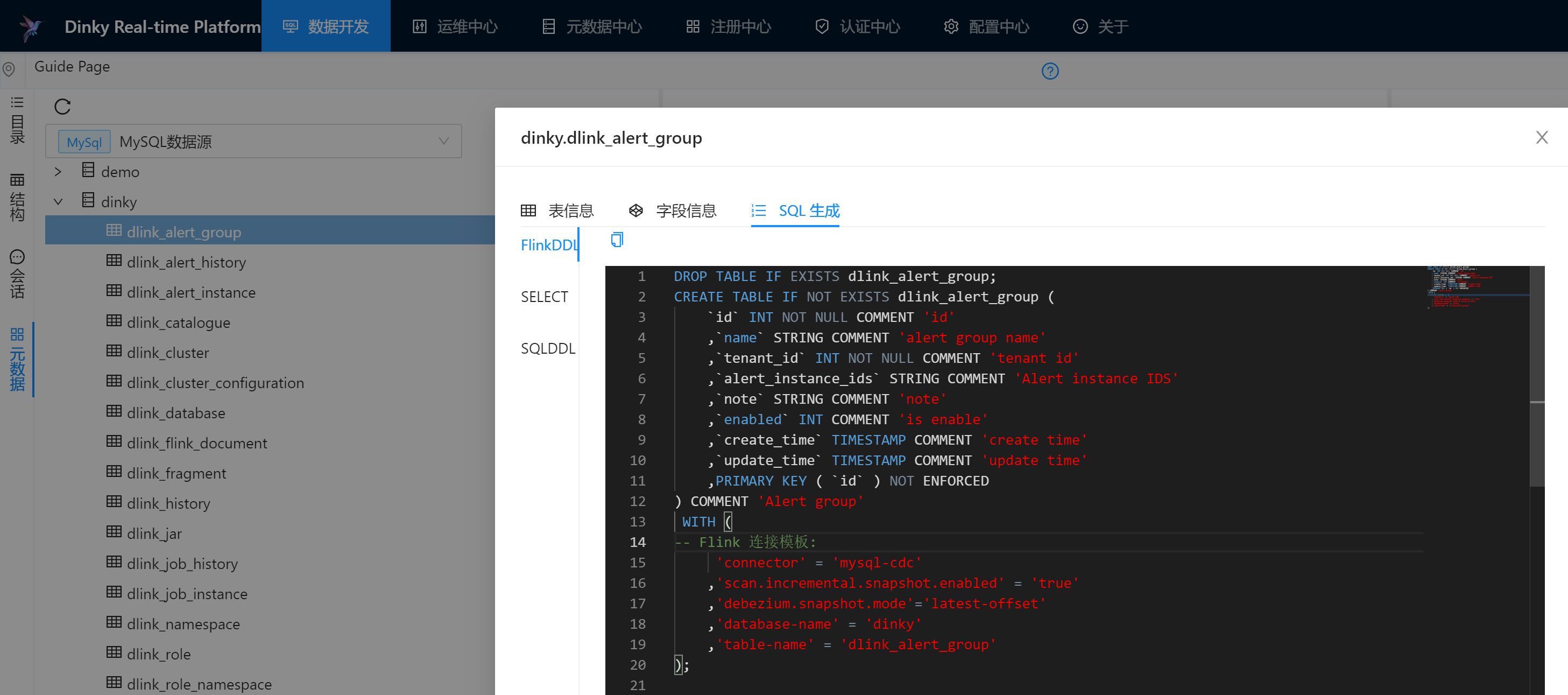
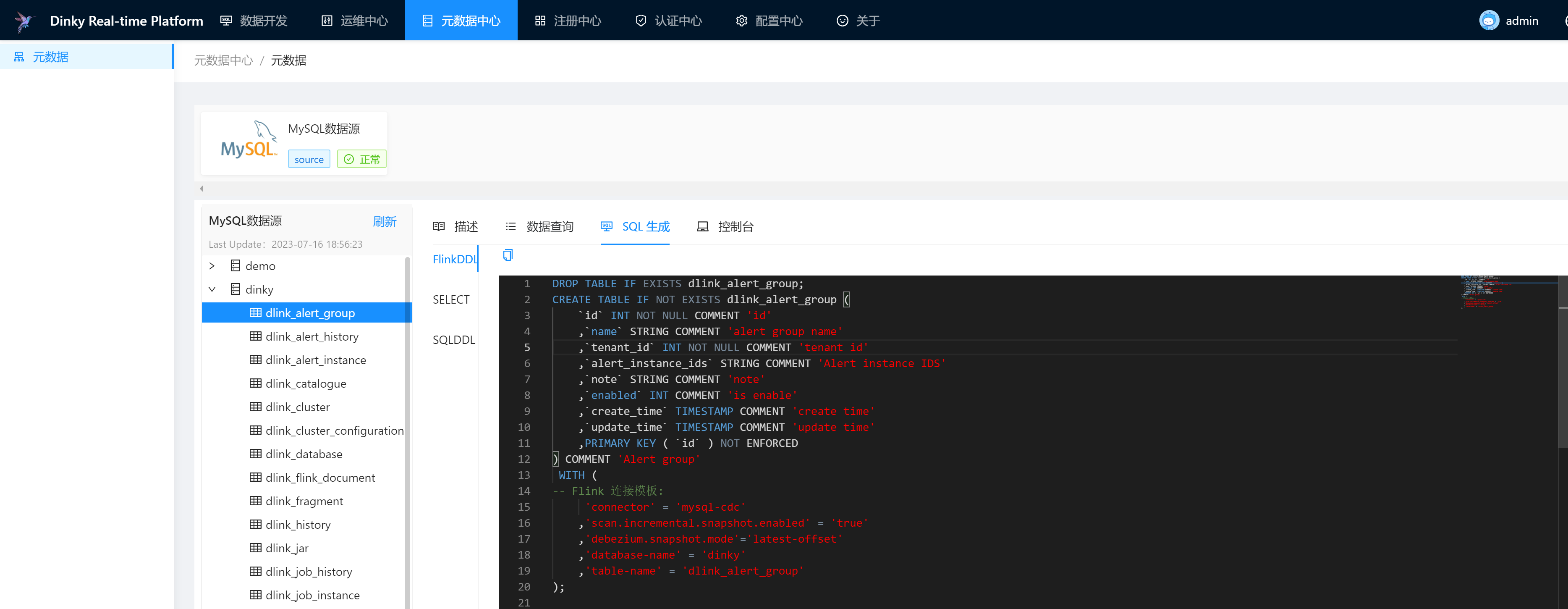
也可以在添加完数据源后,在元数据中心可以访问
这篇关于Dinky之安装部署与基本使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







