本文主要是介绍如何使用Python核对文件夹内的文件,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
说明:日常工作中,我们经常会遇到这样的场景:核对A、B文件夹中文件的差异,找出A、B文件夹中不同部分的文件;
本文介绍如何使用Python来实现;
第一步:获取文件清单
首先,我们要获取到两个文件夹的所有文件名清单,这里假设A、B文件夹里面放的都是文件夹,没有多级目录。
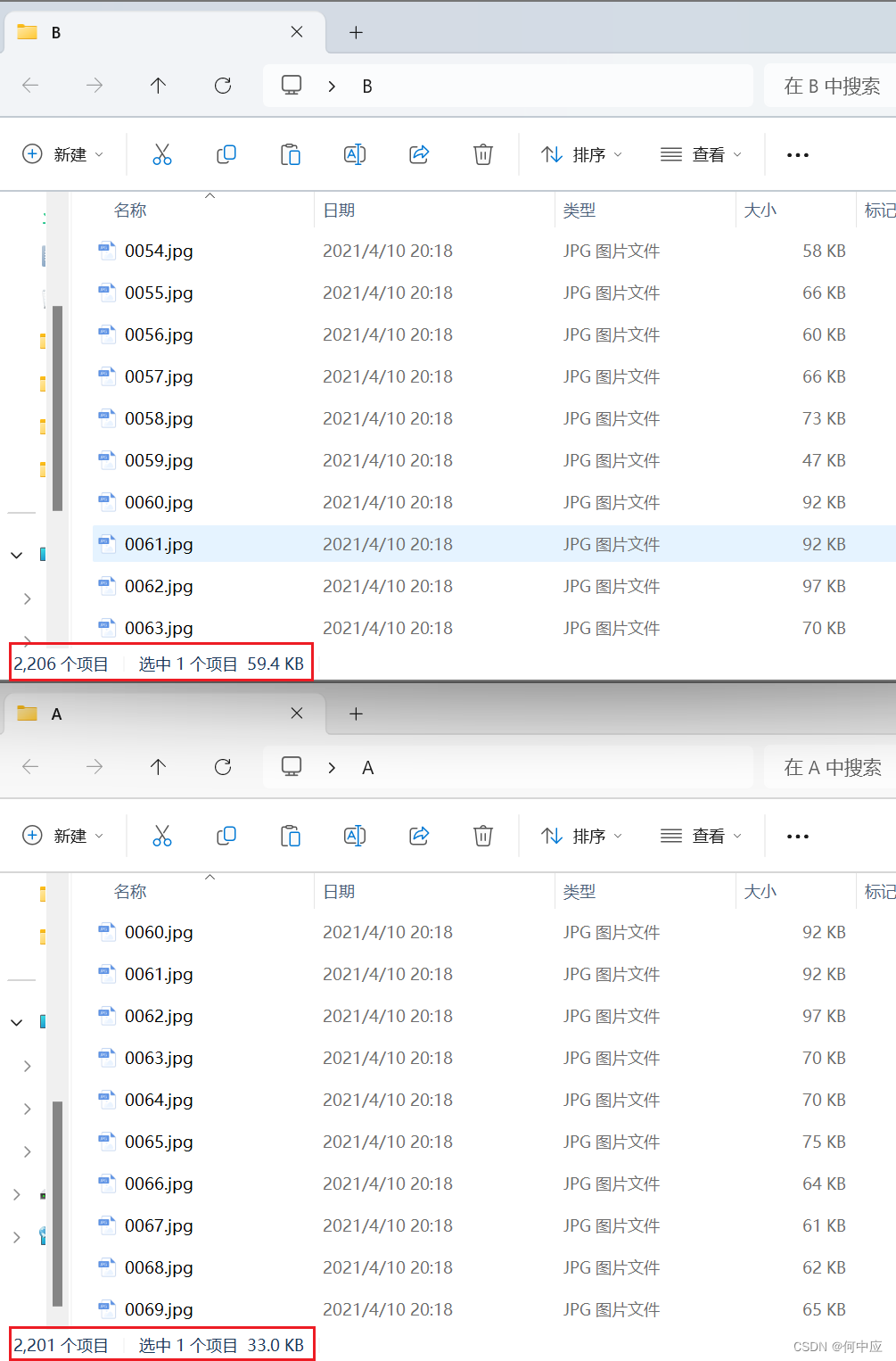
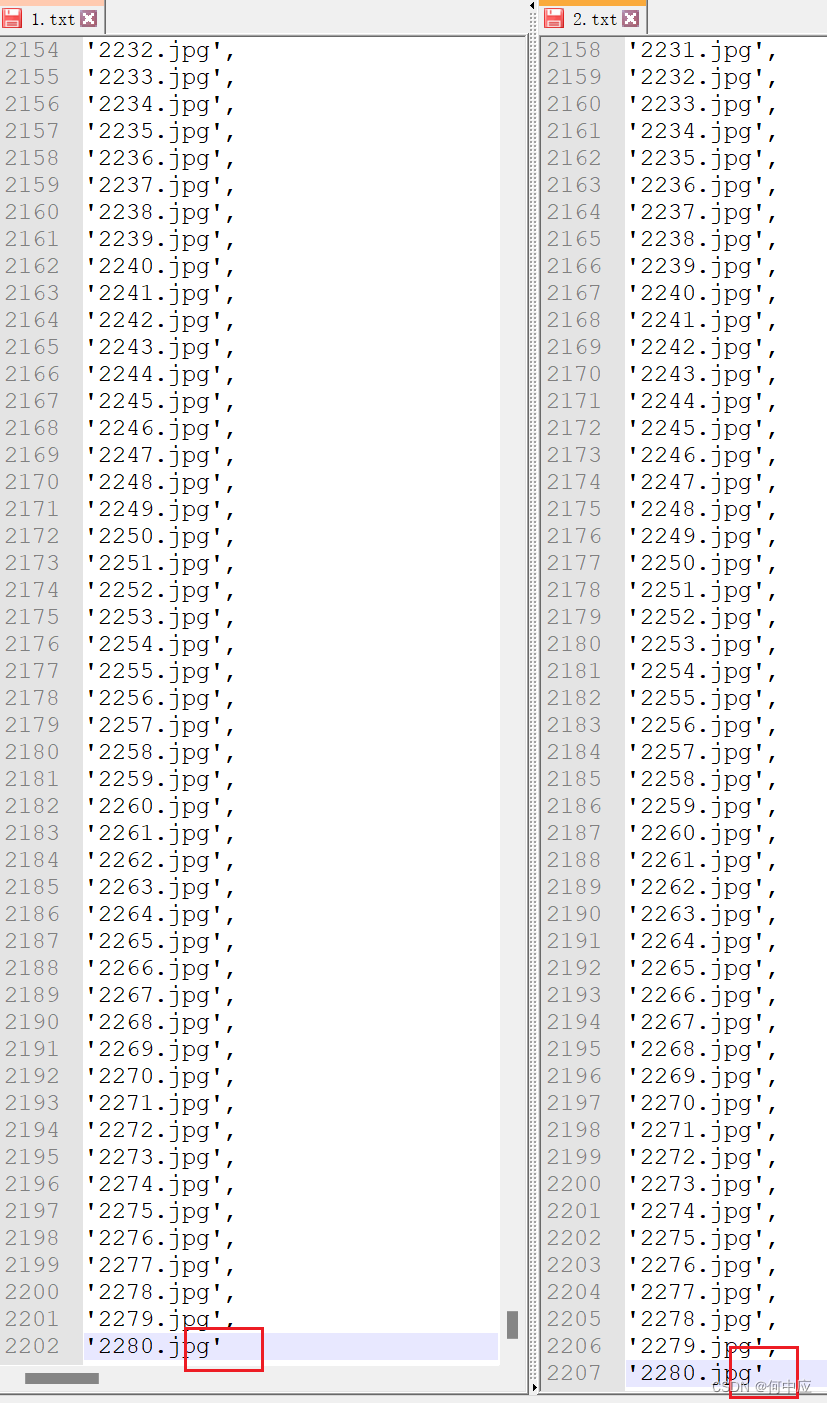
如上,A、B文件夹大部分文件都是同名的,只有部分文件有差异;
获取文件夹内的文件清单,有两种方法:
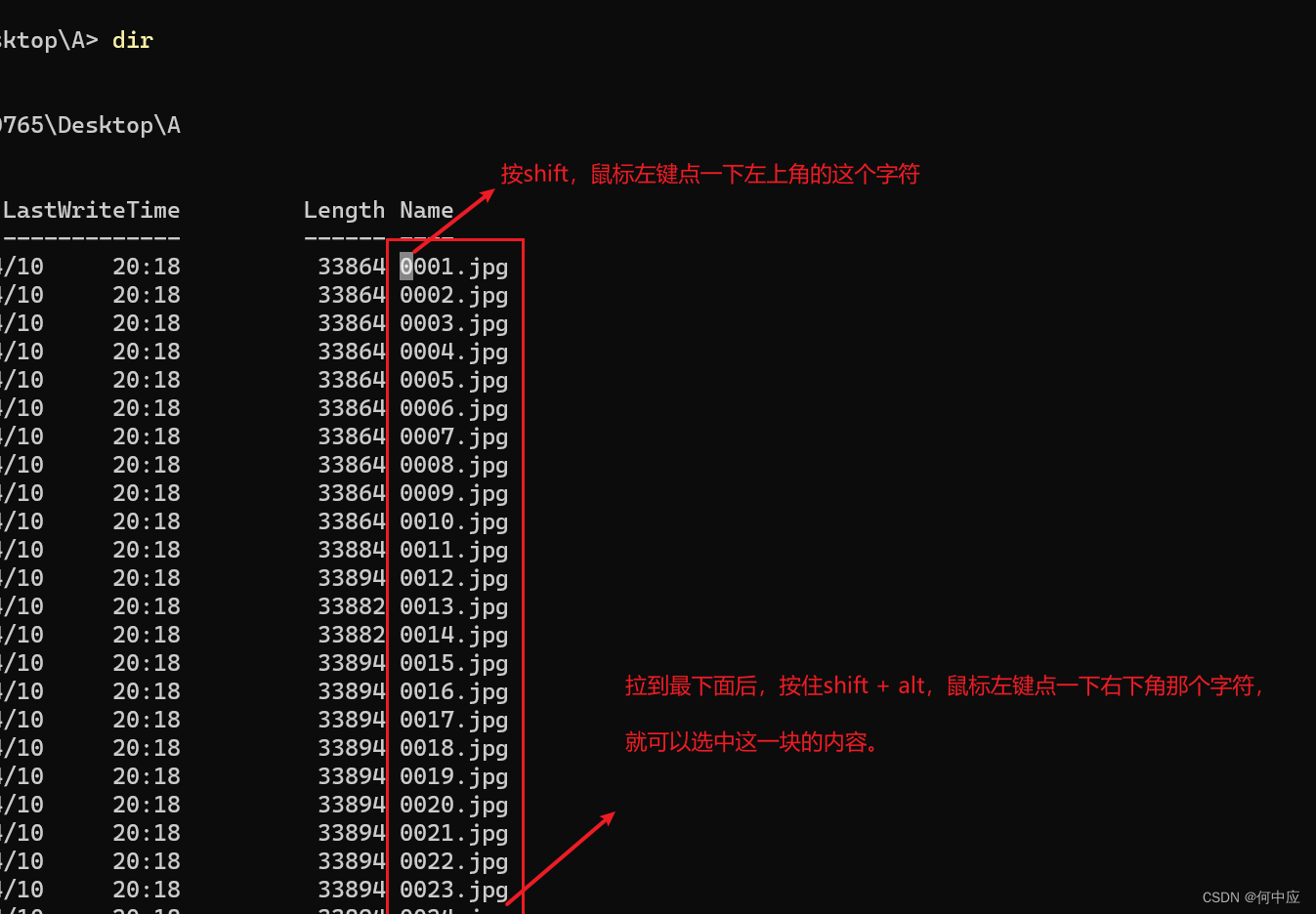
- 第一种:在目录内打开CMD,敲dir,把文件名案按列选中,复制下来;

有一种快一点的办法,可以不用按住拖动,选择左上角的字符,按shift选中,然后就可以松开了,再拉动滚动条到右下角的字符,按住shift + alt,再点一下字符。就可以选中这一块的内容。
- 第二种:第一种方式,在文件量巨大的时候,命令窗口可能会打印很久,而且还会清除上面的信息,找不到开头的内容。这时,可以输入下面这行CMD命令,表示把当前目录的文件信息打印到1.txt文件里;
dir > 1.txt
生成文件后,就可以随便操作了。
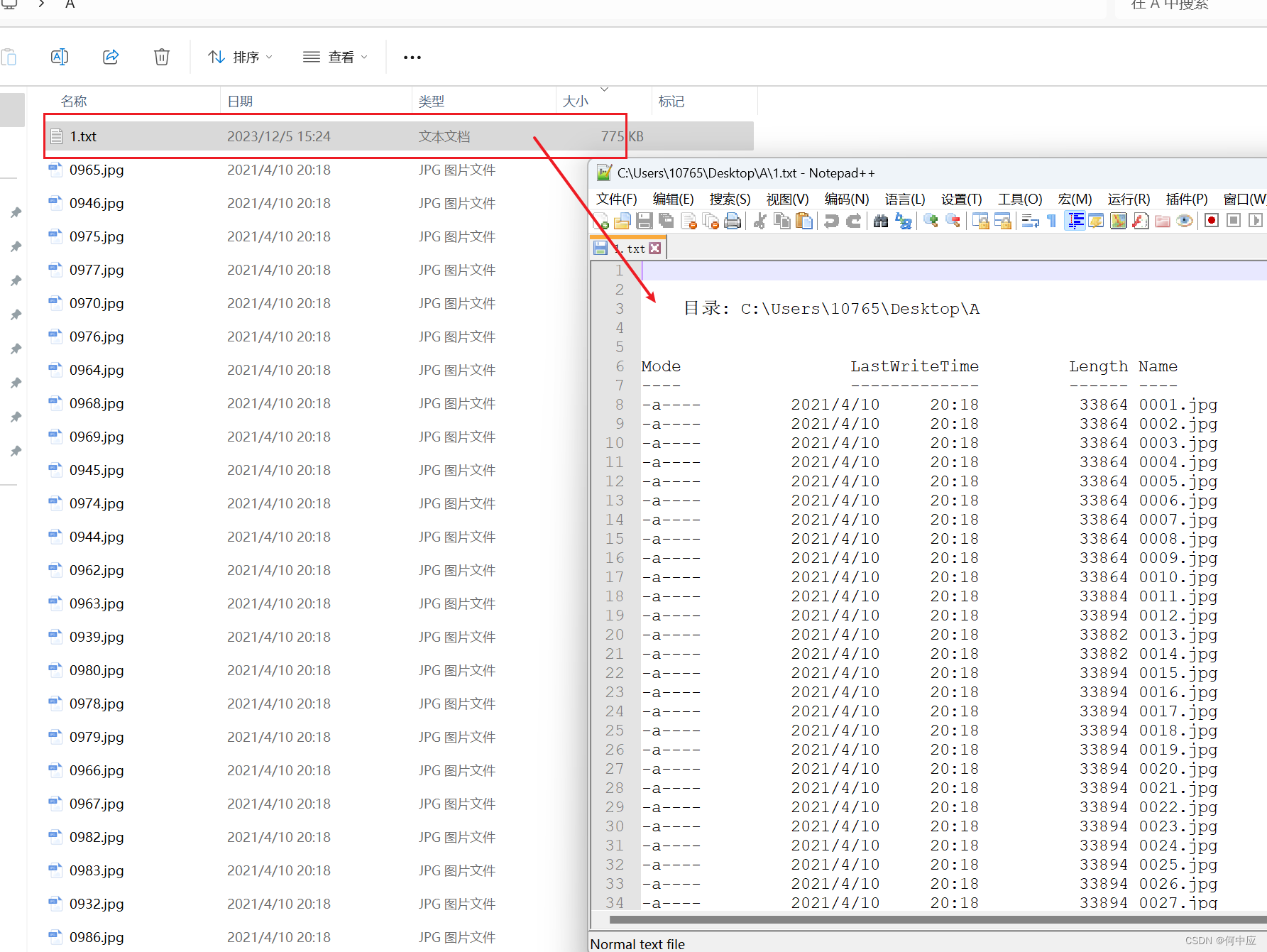
最终,我们可以得到两个文件夹内所有的文件清单,如下:

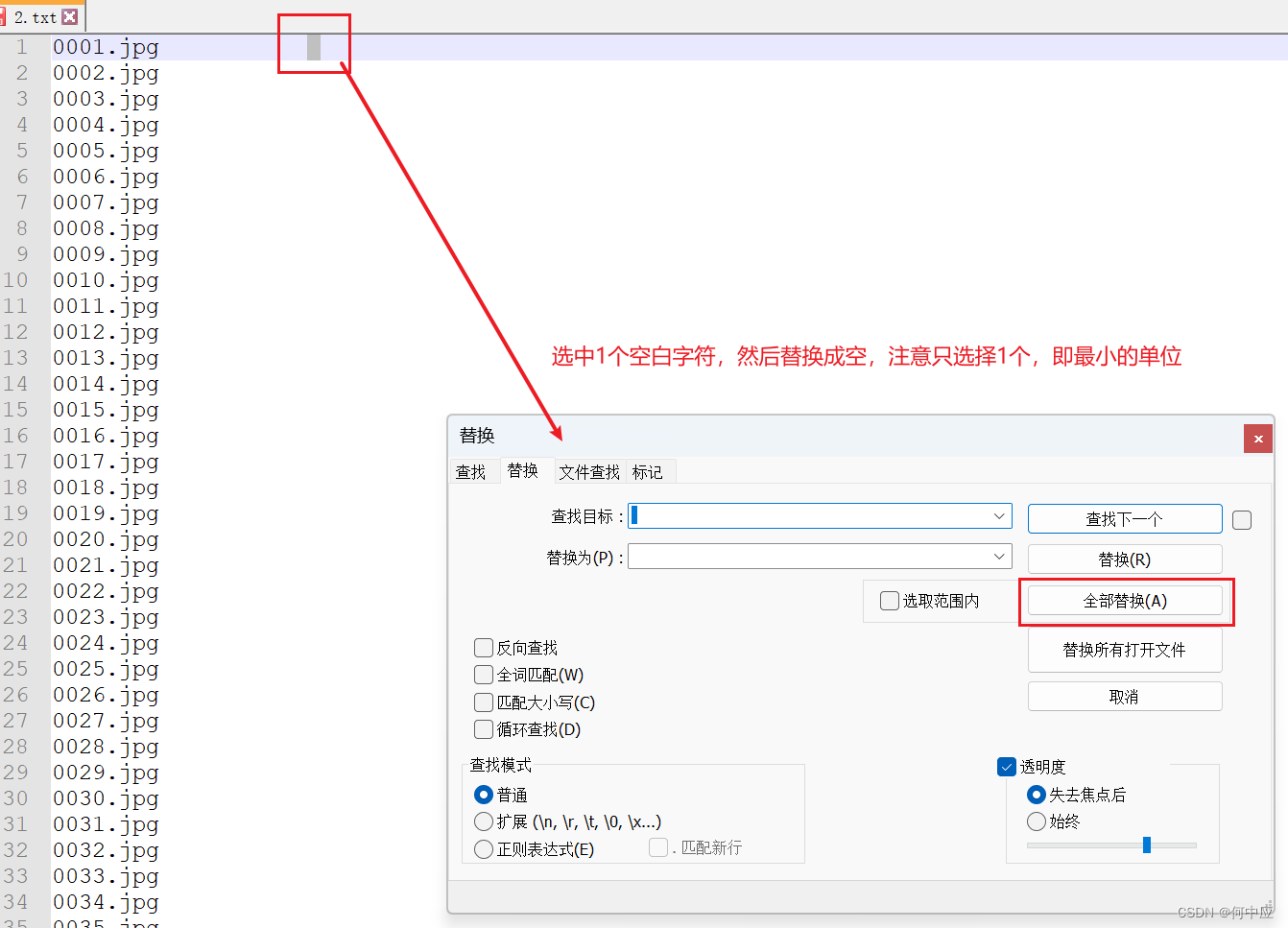
注意:文件内可能有一些空白字符,需要选中空白字符,然后将空白字符替换成空;
最后,再按列在文件前面添加一个英文单引号(‘),文件末尾添加一个英文单引号+英文逗号(’,),去掉末尾的英文逗号。
建议使用shfit + alt的方式来按列选中,比较方便。
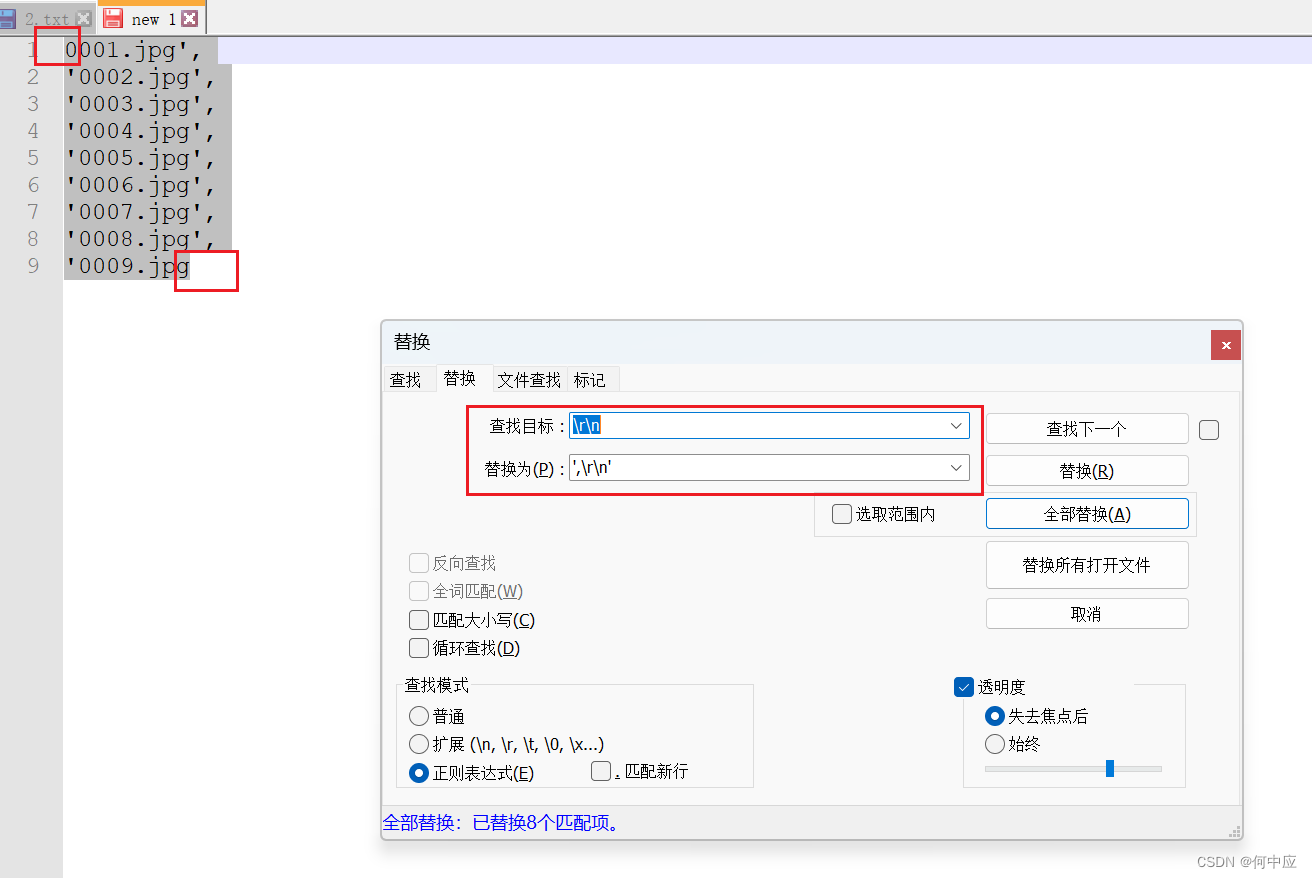
另外,如果文件名长度不一,可以使用正则表达式的查找模式。首先分析,我们需要在每行的末尾,换行前加上英文单引号 + 英文逗号(‘,),换行后在行首加上英文单引号(’),可以按照下面这样替换。这种方式需要ctrl + a,全选之后再替换。
第二步:编写程序
有了各自文件夹的文件清单,写一个Python脚本,对这两部分文件清单进行遍历判断,输出对应的文件名即可;
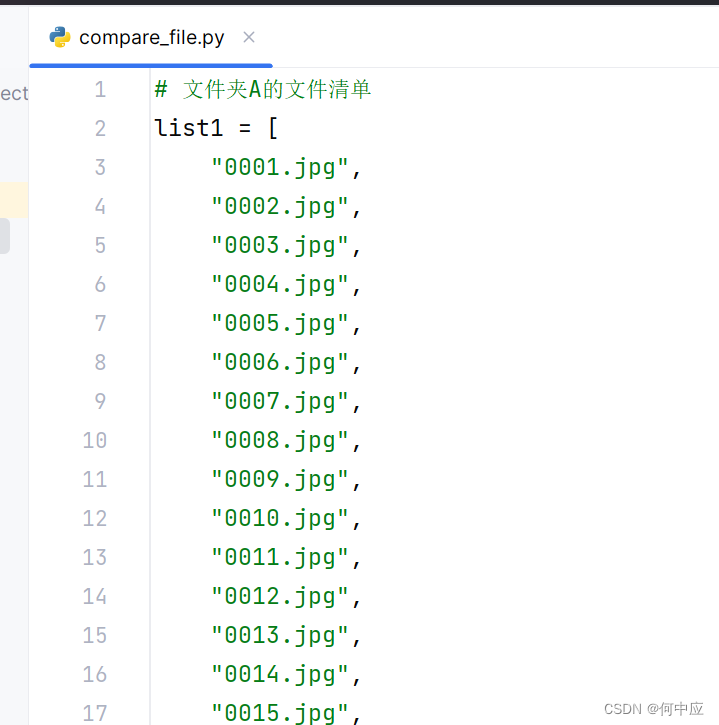
# 文件夹A的文件清单
list1 = []# 文件夹B的文件清单
list2 = []print("文件夹A中,但不在文件夹B中的文件:")
for i in list1:if i not in list2:print('【' + i + '】')print("==============================================")print("文件夹B中,但不在文件夹A中的文件:")
for i in list2:if i not in list1:print('【' + i + '】')
然后将文件清单复制到各自的list中即可,如下:
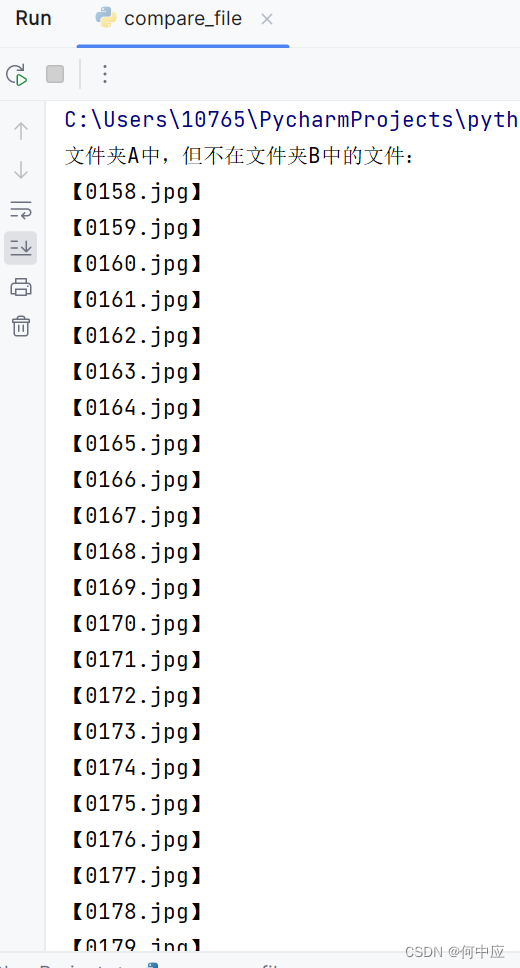
执行结果如下:
总结
这只是一种简单的应用,像其他的,如给一个文件清单,把某文件夹中在这个清单内的文件复制/拷贝出来,没有的打印出来,也是可以实现的。重要的是要有一种思维,重复的事情交给程序做。
这篇关于如何使用Python核对文件夹内的文件的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







