本文主要是介绍Hadoop学习笔记(HDP)-Part.07 安装MySQL,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
Part.01 关于HDP
Part.02 核心组件原理
Part.03 资源规划
Part.04 基础环境配置
Part.05 Yum源配置
Part.06 安装OracleJDK
Part.07 安装MySQL
Part.08 部署Ambari集群
Part.09 安装OpenLDAP
Part.10 创建集群
Part.11 安装Kerberos
Part.12 安装HDFS
Part.13 安装Ranger
Part.14 安装YARN+MR
Part.15 安装HIVE
Part.16 安装HBase
Part.17 安装Spark2
Part.18 安装Flink
Part.19 安装Kafka
Part.20 安装Flume
七、安装MySQL
mysql主从复制的原理:
1)master将数据改变记录到二进制日志(binary log)中,也即是配置文件log-bin指定的文件(这些记录叫做二进制日志事件,binary log events);
2)slave将master的binary log events拷贝到它的中继日志(relay log);
3)slave重做中继日志中的事件,将改变反映它自己的数据(数据重演)。
主从配置注意点:
- 主、从DB server数据库的版本一致,主DB server和从DBserver数据库数据一致 主DB
- server开启二进制日志,主DB server和从DB server的server_id都必须唯一
1.删除MariaDB
查询并删除原有的MariaDB
ansible nn -m shell -a 'rpm -qa | grep mariadb'
ansible nn -m shell -a 'rpm -e --nodeps mariadb-libs-5.5.64-1.el7.x86_64'
2.安装
创建/root/ansible/mysql.yml文件
---
- hosts: nntasks:- name: install mysqlunarchive:src: "/opt/mysql-5.7.25-linux-glibc2.12-x86_64.tar.gz"dest: "/usr/local/"- name: create groupgroup:name: mysqlstate: present- name: create useruser:name: mysqlgroup: mysqlstate: present- name: create directoryfile:path: "/data01/mysql/mariadb"state: directoryowner: mysqlgroup: mysqlrecurse: yes- name: create file of logfile:path: "/data01/mysql/mariadb/mariadb.log"state: touchowner: mysqlgroup: mysql
执行安装
ansible-playbook mysql.yml
3.配置
创建配置文件/etc/my.cnf,hdp01的server-id为100,hdp02的server-id为200
[mysqld]
user = mysql # mysqld程序在启动后将在给定UNIX/Linux账户下执行。mysqld必须从root账户启动才能在启动后切换到另一个账户下执行
basedir = /usr/local/mysql-5.7.25-linux-glibc2.12-x86_64/ # MySQL安装的绝对路径
datadir = /data01/mysql/data # MySQL数据存放的绝对路径socket = /data01/mysql/mysql.sock # socket文件路径
port = 3306 # 服务端口号
server-id=100 # MySQL服务的唯一编号,每个MySQL服务的id需唯一default_authentication_plugin = mysql_native_passwordcharacter-set-server = utf8mb4 # 数据库默认字符集, 主流字符集支持一些特殊表情符号(特殊表情符占用4个字节)
collation-server = utf8mb4_general_ci # 数据库字符集对应一些排序等规则,注意要和character-set-server对应
init_connect='SET NAMES utf8mb4' # 设置client连接mysql时的字符集,防止乱码
lower_case_table_names = 1 # 是否对 sql 语句大小写敏感,1 表示不敏感key_buffer_size = 16M # 用于指定索引缓冲区的大小
max_allowed_packet = 1024M # 设置一次消息传输的最大值,如果有BLOB对象建议修改成1G
sql_mode = TRADITIONAL # 表示SQL模式的参数,通过这个参数可以设置检验SQL语句的严格程度
pid-file = /data01/mysql/data/mysql.pid # pid-file文件路径
log-bin=/data01/mysql/mysql-bin # 二进制文件存放路径,生产环境下建议将bin-log和data分磁盘存储,避免日志打满影响数据
max_connections = 1000 # 设置最大连接数[mysqld_safe]
log-error = /data01/mysql/mariadb/mariadb.log
pid-file = /data01/mysql/mariadb/mariadb.pid[client]
port = 3306
socket = /data01/mysql/mysql.sock
4.初始化
【hdp01】【hdp02】初始化基础信息,得到数据库的初始密码,在root账号下执行
cd /usr/local/mysql-5.7.25-linux-glibc2.12-x86_64/bin/
./mysqld --initialize
5.配置系统服务
【hdp01】【hdp02】
配置mysqld系统服务文件/usr/lib/systemd/system/mysql.server.service
[Unit]
Description=Mysql
After=syslog.target network.target remote-fs.target nss-lookup.target[Service]
Type=forking
PIDFile=/data01/mysql/data/mysql.pid
ExecStart=/usr/local/mysql-5.7.25-linux-glibc2.12-x86_64/support-files/mysql.server start
ExecReload=/bin/kill -s HUP $MAINPID
ExecStop=/bin/kill -s QUIT $MAINPID
PrivateTmp=false[Install]
WantedBy=multi-user.target
重新加载
systemctl daemon-reload
通过系统服务启动mysql.server并查看服务状态
systemctl start mysql.server
systemctl status mysql.server
6.重置root密码
【hdp01】【hdp02】做软链接,方便登录
ln -s /usr/local/mysql-5.7.25-linux-glibc2.12-x86_64/bin/mysql /usr/local/sbin/mysql
使用初始化获得的root密码登录一直报错,所以需要按照如下方法免密进入。

先停掉原有的系统服务mysql.server,手工携带参数–skip-grant-tables启动MySQL程序,用以免密进入MySQL修改密码(系统服务已经写好了启动参数,因此手工携带参数单次启动)
systemctl stop mysql.server
cd /usr/local/mysql-5.7.25-linux-glibc2.12-x86_64/support-files/
./mysql.server start --skip-grant-tables
先清空root密码及修改为远程登录
mysql -uroot -p
use mysql;
update user set authentication_string=‘’,host=‘%’ where user=‘root’;
flush privileges;
手工停掉免密登录的MySQL进程,以服务形式启动MySQL
./mysql.server stop
systemctl start mysql.server
再次登陆的时候是空密码登陆,然后修改密码
mysql -uroot -p
alter user ‘root’@‘%’ identified by ‘lnyd@LNsy115’;
flush privileges;
7.主从配置
【hdp01】在mysql中,查看主节点信息
show master status;

创建用于slave同步日志的账号master
create user 'master'@'192.168.111.202' identified with mysql_native_password by 'Aa@123456';
grant replication slave on *.* TO 'master'@'192.168.111.202';
flush privileges;
【hdp02】在mysql中,配置为slave模式
stop slave;
reset slave;
change master to master_host="192.168.111.201", master_user="master",master_password="Aa@123456", master_log_file="mysql-bin.000014",master_log_pos=605;
CHANGE MASTER TO MASTER_HOST:主服务器的IP地址
MASTER_USER:主服务器上用于同步账号
MASTER_PASSWORD:同步账号的密码
MASTER_LOG_FILE:bin日志的文件名,取自主节点SHOW MASTER STATUS结果
MASTER_LOG_POS:bin Eposition值,取自主节点SHOW MASTER STATUS结果
启用从节点
start slave;

查看从节点状态
show slave status\G;
观察Slave_IO_Running和Slave_SQL_Running如果为YES,说明运行正常
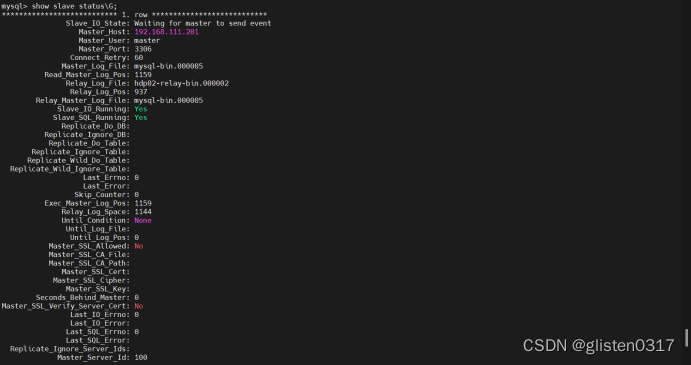
如果出现NO,可能是slave机器重起后,事务回滚造成的,在从节点上执行如下:
stop slave;
set GLOBAL SQL_SLAVE_SKIP_COUNTER=1;
start slave;
8.测试
在主节点上创建测试账号及测试库,查看从节点是否同步
【hdp01】创建测试账号及测试数据库、测试表
create user 'test_user_0212'@'localhost';
flush privileges;
create database test_db_0212;
create table test_db_0212.test_table_0212 (id integer);
【hdp02】查看是否存在测试账号、测试数据库及测试表
select user,host from mysql.user where user='test_user_0212';

show databases;

describe test_db_0212.test_table_0212;

这篇关于Hadoop学习笔记(HDP)-Part.07 安装MySQL的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







