本文主要是介绍Ranger安装和使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Ranger部署
1.准备
1.1 编译
Ranger编译(已经编译过的话,直接看1.2)
1.1.1 准备到Ranger官网下载ranger的源码:http://ranger.apache.org/download.html
1.1.2 Ranger编译的过程实在非虚拟机环境下完成的,下载好ranger源码后并解压,然后进入源码解压目录执行如下命令进行编译:
cd /Users/fan/Downloads/apache-ranger-2.0.0 mvn clean compile package assembly:assembly install -Dmaven.test.skip=true mvn clean install -DskipTests -Denforcer.skip=true
1.1.3 将编译好的tar包上传到bigdb03
rsync -r share/ root@172.16.1.228:/data/fan/install/native/10.ranger/package/
1.2 数据库环境准备
1.2.1 登录mysql (之前安装hive时候装的那个mysql)
[root@bigdb01 ~]# docker exec -it mysql-hive bash root@bigdb01:/# mysql -uroot -phz310012
1.2.2 创建Ranger存储数据的数据库
mysql> create database ranger;
1.2.3 创建用户
mysql> grant all privileges on ranger.* to ranger@'%' identified by '@#QWEASD123';2.安装RangerAdmin
2.1 解压软件
[root@bigdb01 ~]# rsync root@bigdb03:/data/fan/install/native/10.ranger/package/ranger-2.0.0-admin.tar.gz /opt/software
[root@bigdb01 ~]# mkdir /opt/module/ranger
[root@bigdb01 ~]# tar -zxvf /opt/software/ranger-2.0.0-admin.tar.gz -C /opt/module/ranger/2.2 配置install.properties文件
[root@bigdb01 ~]# vim /opt/module/ranger/ranger-2.0.0-admin/install.properties修改以下内容:


2.3 在root用户下,执行安装
注意:ranger2.0需要用python2执行,RHEL9自带python3.9,所以需要自己安装python2
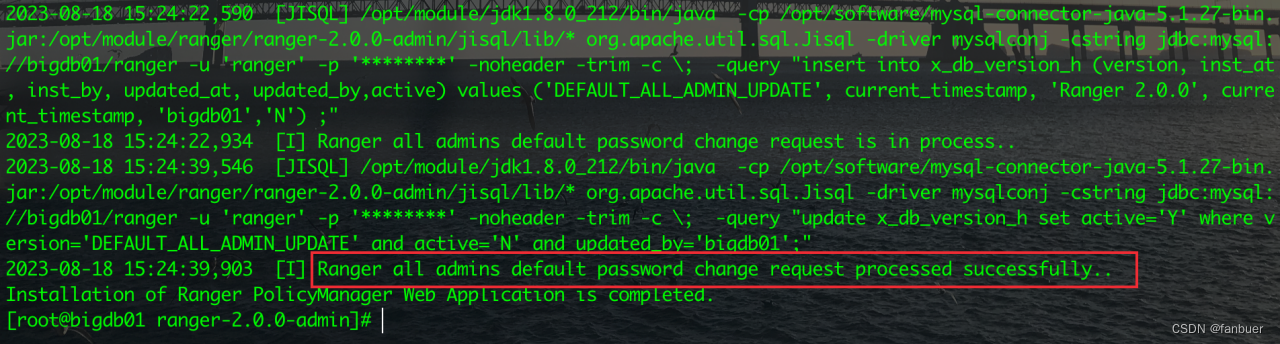
[root@bigdb01 ~]# cd /opt/module/ranger/ranger-2.0.0-admin/ [root@bigdb01 ranger-2.0.0-admin]# ./setup.sh出现以下字样,表示安装成功
2.4 创建ranger的配置文件软连接到web下
[root@bigdb01 ranger-2.0.0-admin]# ./set_globals.sh usermod: no changes [2023/08/18 15:53:49]: [I] Soft linking /etc/ranger/admin/conf to ews/webapp/WEB-INF/classes/conf
2.5 启动 RangerAdmin
2.5.1 配置RangerAdminweb应用的配置信息
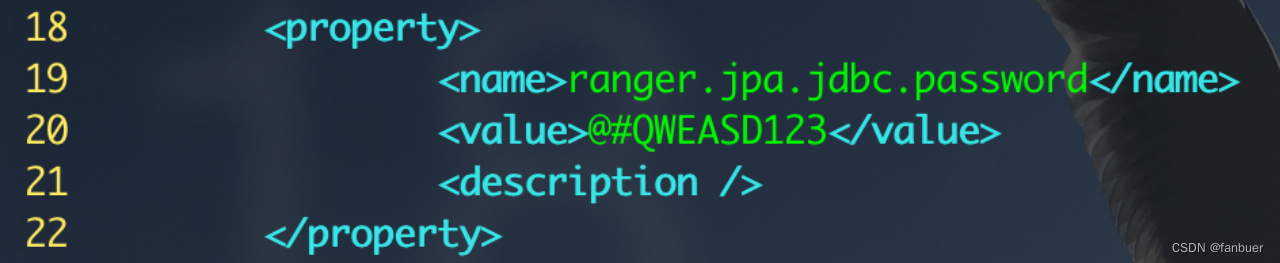
[root@bigdb01 ~]# cd /etc/ranger/admin/conf/ [root@bigdb01 conf]# vim ranger-admin-site.xml
修改内容如下

2.5.2 启动
[root@bigdb01 conf]# ranger-admin start
启动成功

2.5.3 查看启动后的进程
[root@bigdb01 conf]# jps 47556 EmbeddedServer 47621 Jps
2.5.4 停止 ranger
[root@bigdb01 conf]# ranger-admin stop
2.6 登录管理员用户
默认admin,密码@#QWEASD123
3.安装RangerUsersync
3.1 解压
[root@bigdb01 ~]# rsync root@bigdb03:/data/fan/install/native/10.ranger/package/ranger-2.0.0-usersync.tar.gz /opt/software [root@bigdb01 ~]# tar -zxvf /opt/software/ranger-2.0.0-usersync.tar.gz -C /opt/module/ranger/
3.2 配置
[root@bigdb01 software]# cd /opt/module/ranger/ranger-2.0.0-usersync/ [root@bigdb01 ranger-2.0.0-usersync]# vim install.properties
配置内容如下
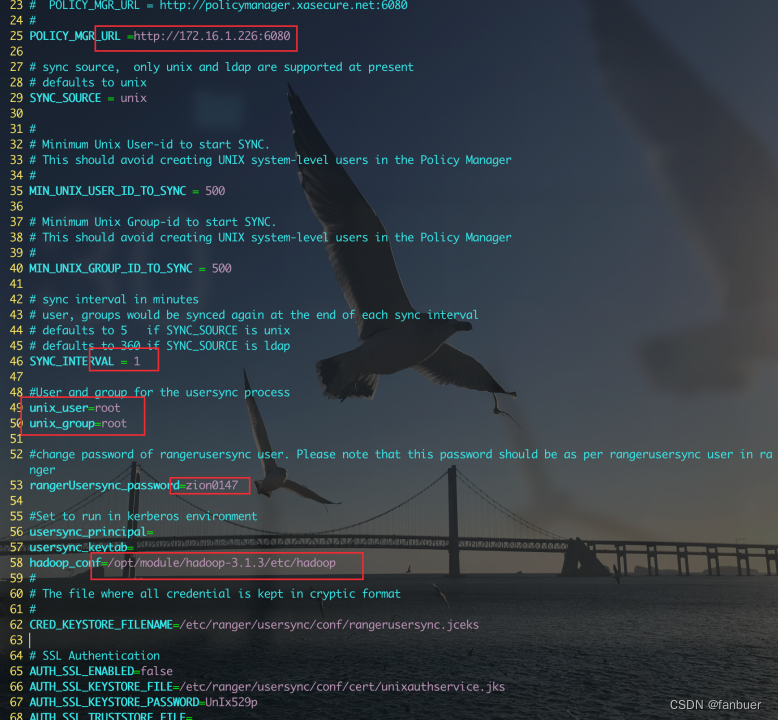
3.3 使用root用户进行安装
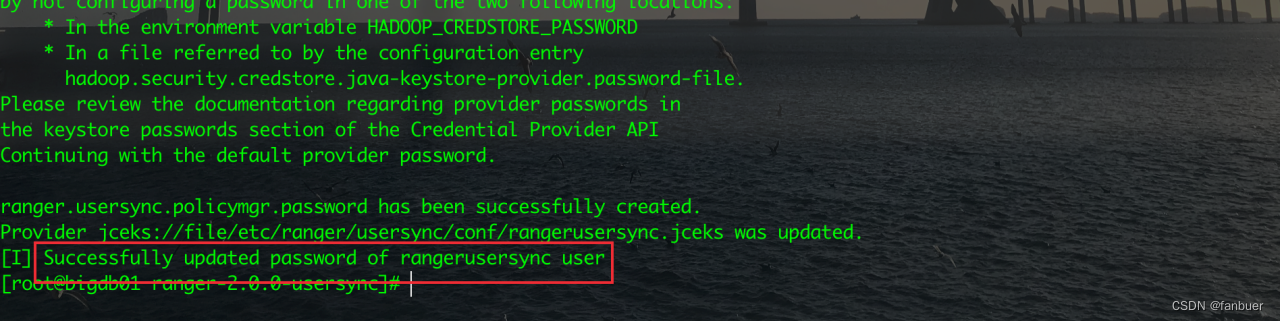
[root@bigdb01 ranger-2.0.0-usersync]# ./setup.sh
出现如下信息,说明安装成功
3.4 RangerUsersync 启动
3.4.1 启动前
3.4.2 使用root启动
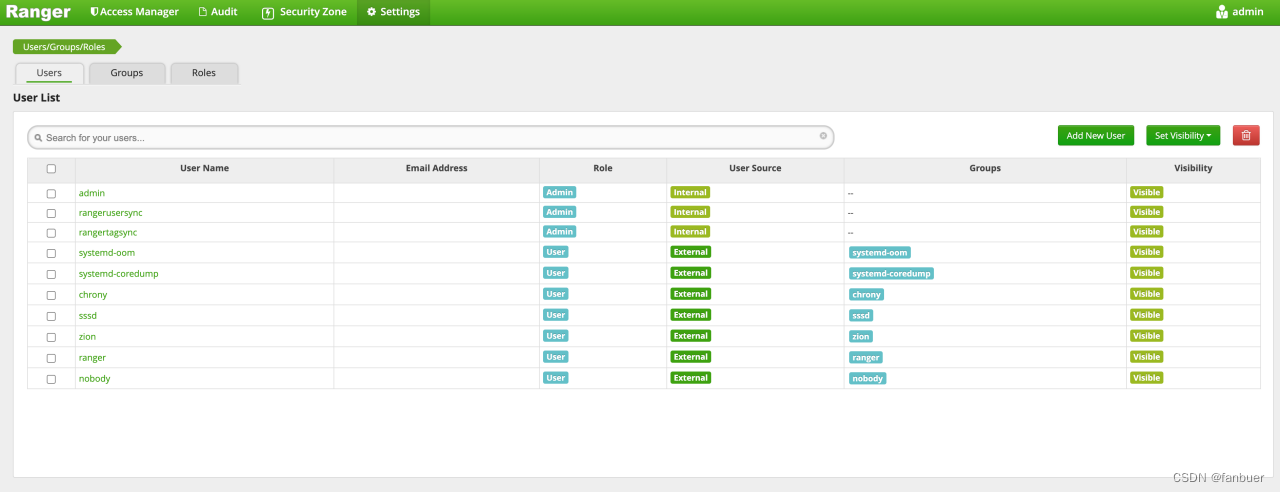
[root@bigdb01 ranger-2.0.0-usersync]# ./ranger-usersync-services.sh start

启动后再次查看用户信息
4.Ranger Hive-plugin
4.1 安装
4.1.1 解压软件
[root@bigdb01 ~]# rsync root@bigdb03:/data/fan/install/native/10.ranger/package/ranger-2.0.0-hive-plugin.tar.gz /opt/software
[root@bigdb01 ~]# tar -zxvf /opt/software/ranger-2.0.0-hive-plugin.tar.gz -C /opt/module/ranger/4.1.2 配置软件
[root@bigdb01 ~]# vim /opt/module/ranger/ranger-2.0.0-hive-plugin/install.properties
配置内容如下
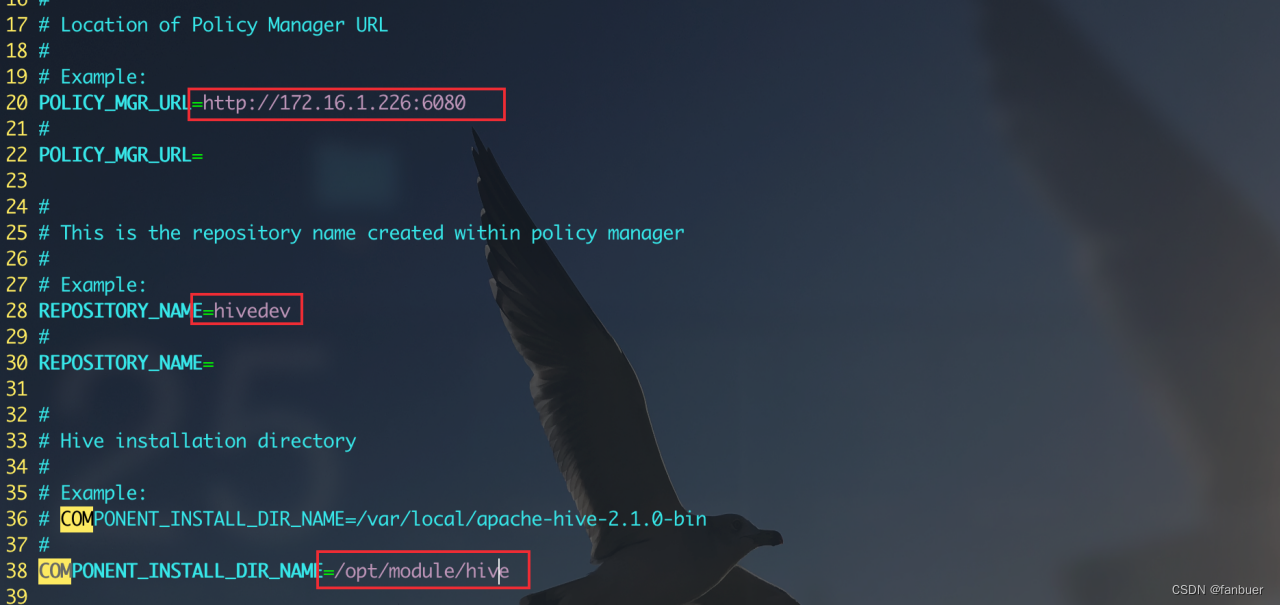

4.1.3 引用hive配置文件
将hive的配置文件作为软连接安装到 Ranger Hive-plugin 目录下
[root@bigdb01 ranger-2.0.0-hive-plugin]# ln -s /opt/module/hive/conf/ conf
4.1.4 启动
使用root用户启动Ranger Hive-plugin
[root@bigdb01 ranger-2.0.0-hive-plugin]# ./enable-hive-plugin.sh
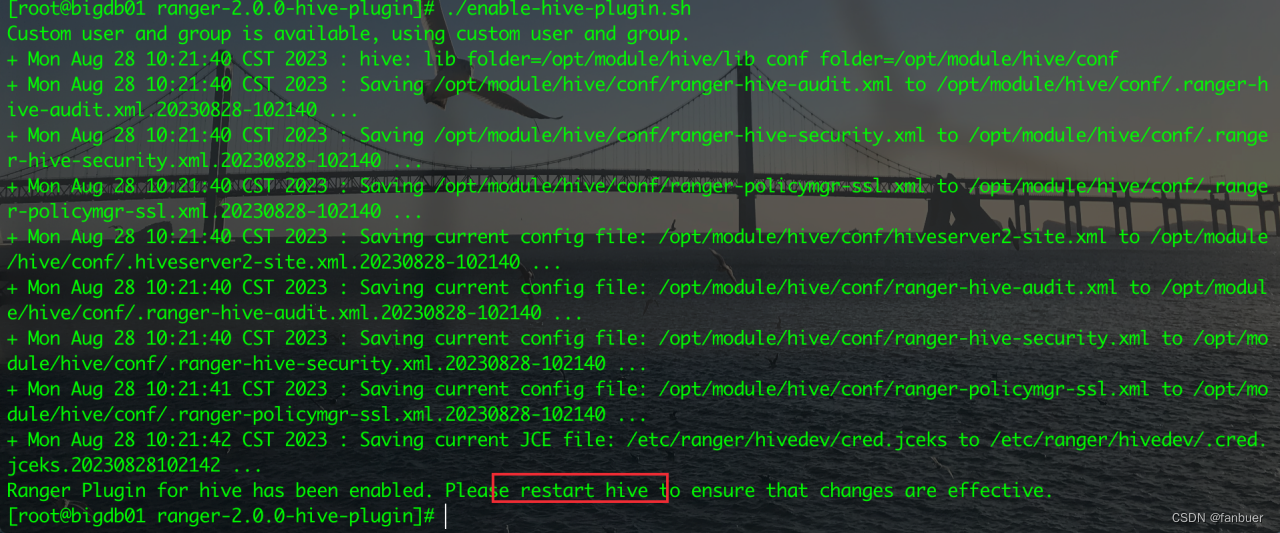
4.1.5 重启hive
[root@bigdb01 ranger-2.0.0-hive-plugin]# hiveservice.sh restart
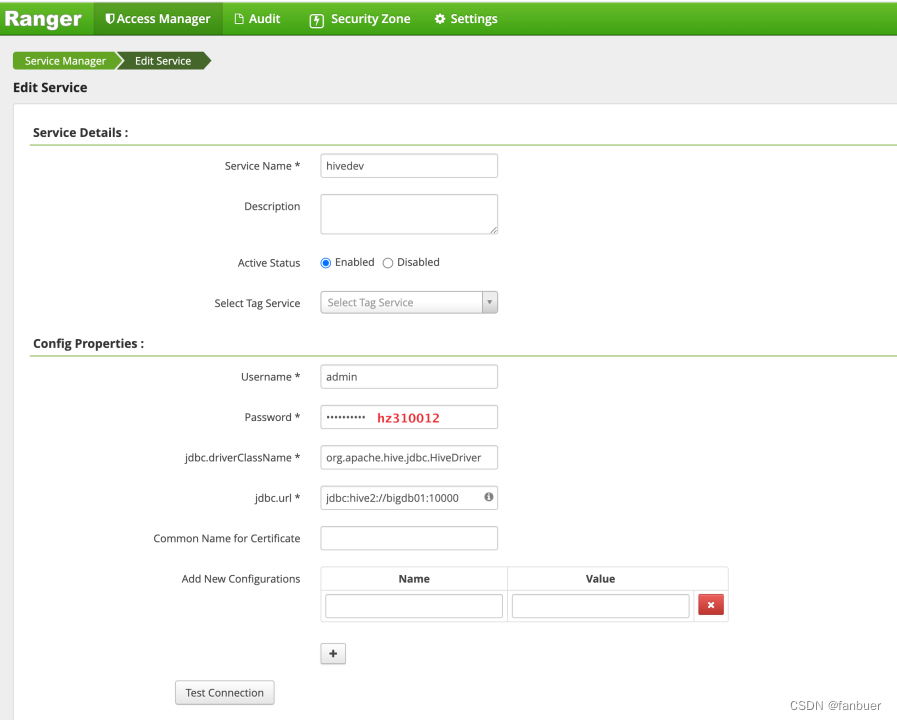
4.2 权限管理
[root@bigdb01 ~]# beeline
beeline> !connect jdbc:hive2://bigdb01:10000
Connecting to jdbc:hive2://bigdb01:10000
Enter username for jdbc:hive2://bigdb01:10000: admin
Enter password for jdbc:hive2://bigdb01:10000: hz310012
Connected to: Apache Hive (version 3.1.2) Driver: Hive JDBC (version 3.1.2) Transaction isolation: TRANSACTION_REPEATABLE_READ 0:
jdbc:hive2://bigdb01:10000>如果报以下错误,要修改/tmp权限
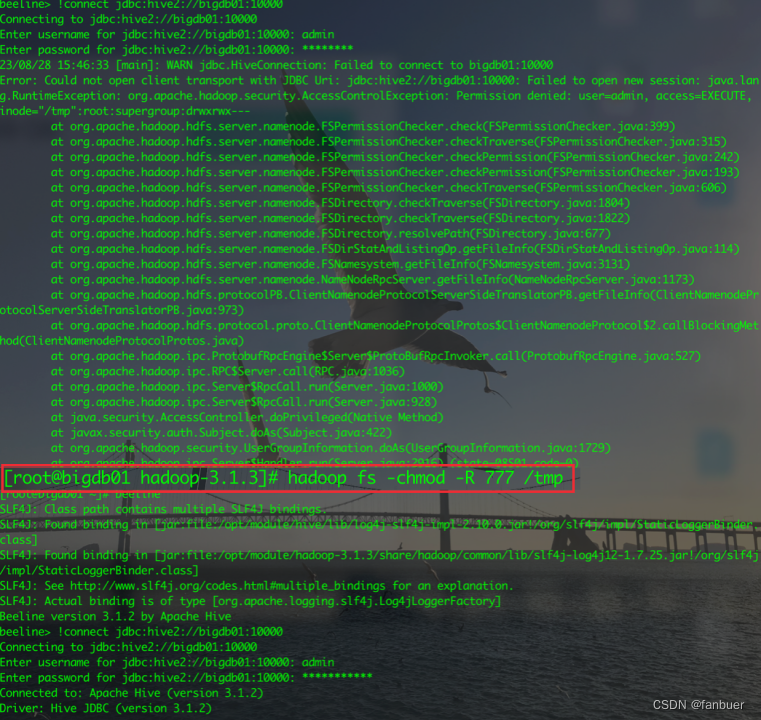
4.2.1 读写权限
为zion用户配置dd库student表的读的权限。
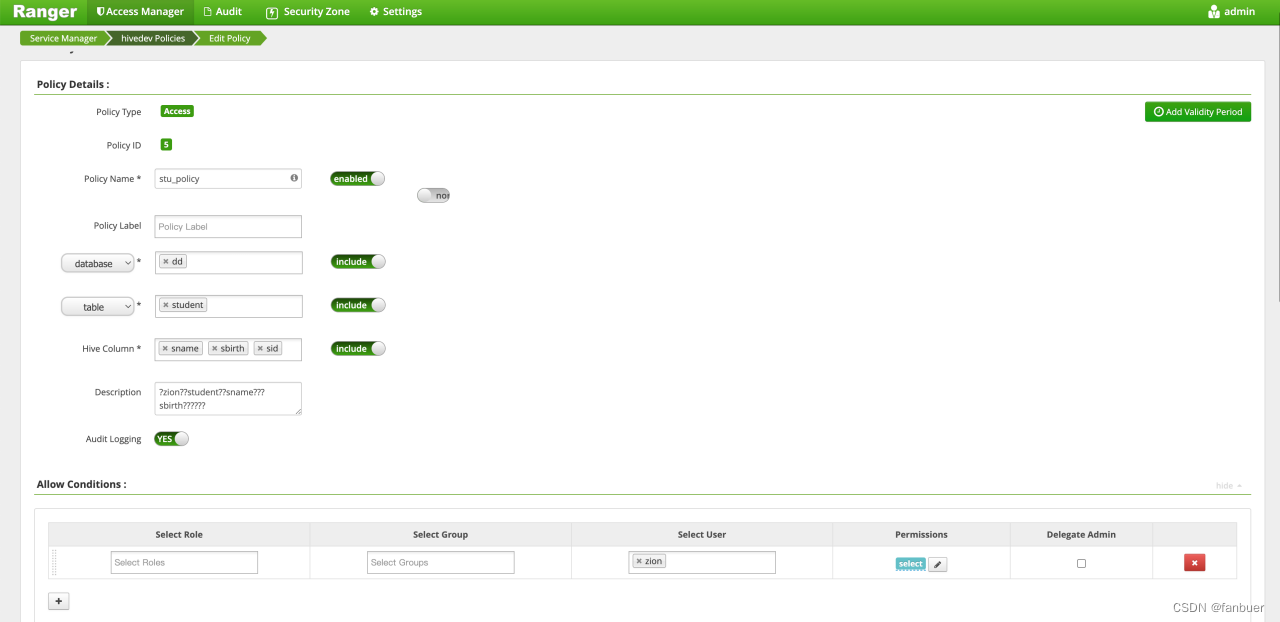
[root@bigdb01 ~]# beeline
beeline> !connect jdbc:hive2://bigdb01:10000
Enter username for jdbc:hive2://bigdb01:10000: zion
Enter password for jdbc:hive2://bigdb01:10000: ****
0: jdbc:hive2://bigdb01:10000> use dd;
0: jdbc:hive2://bigdb01:10000> select * from student;
0: jdbc:hive2://bigdb01:10000> select sname,sbirth from student;看下效果
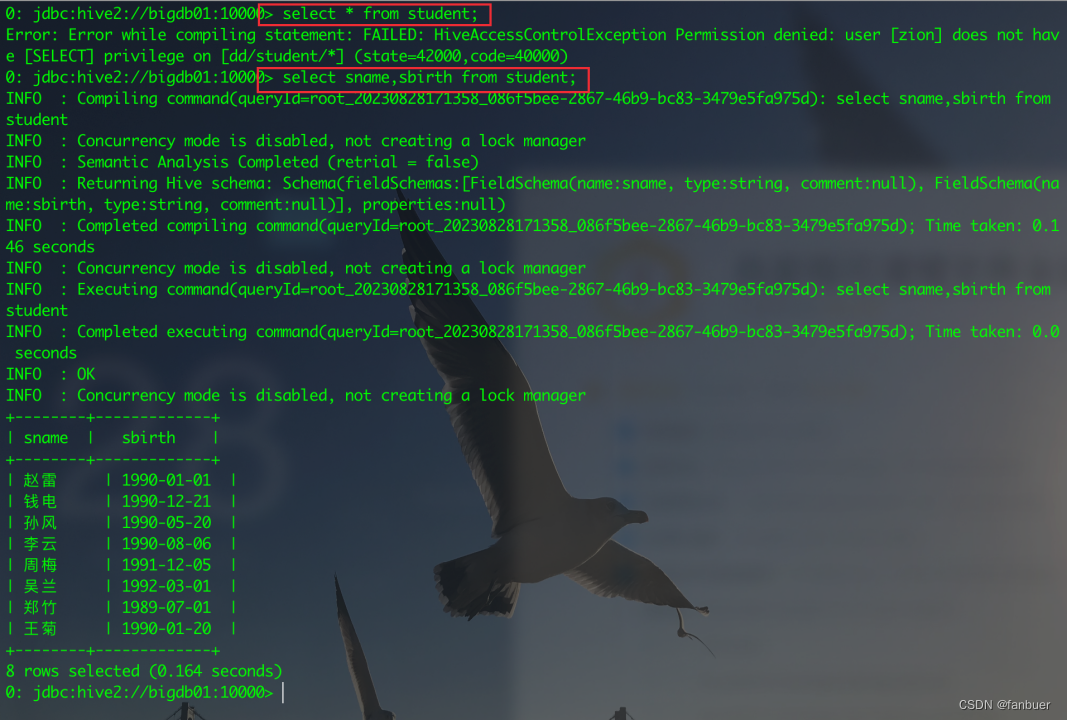
4.2.2 脱敏操作
注意要配合的用户或者用户组必须已具备查看权限
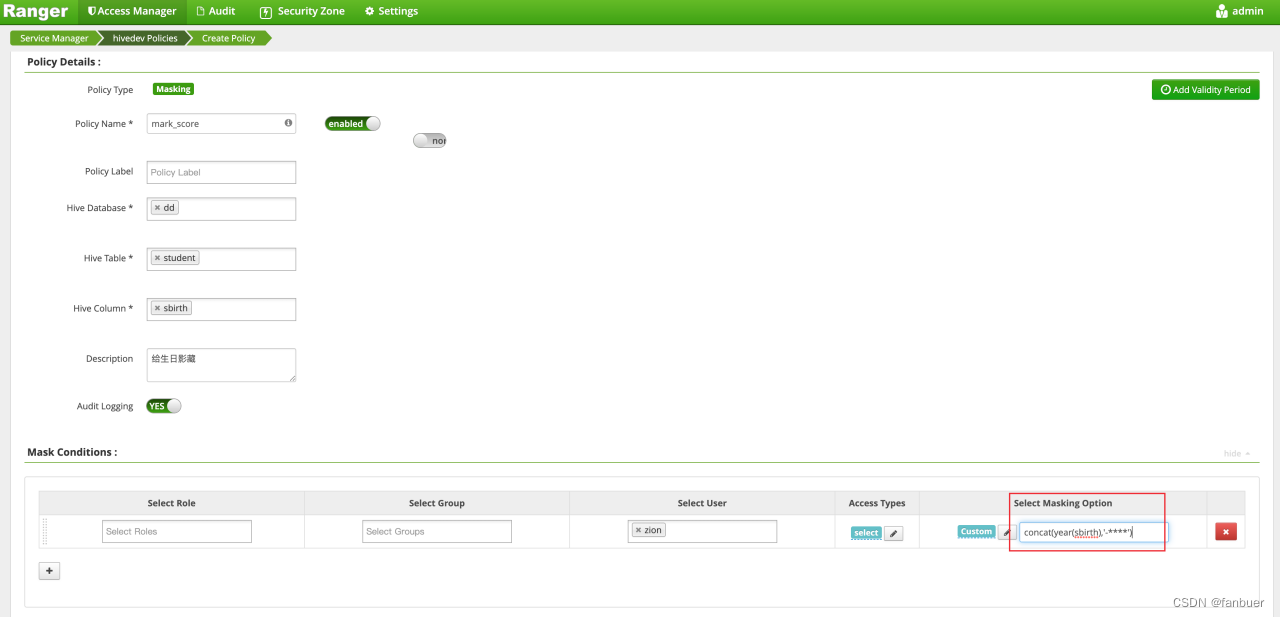
看下效果

4.2.3 行级别过滤
注意 过滤条件中的字段必须是当前用户有权限查看的。
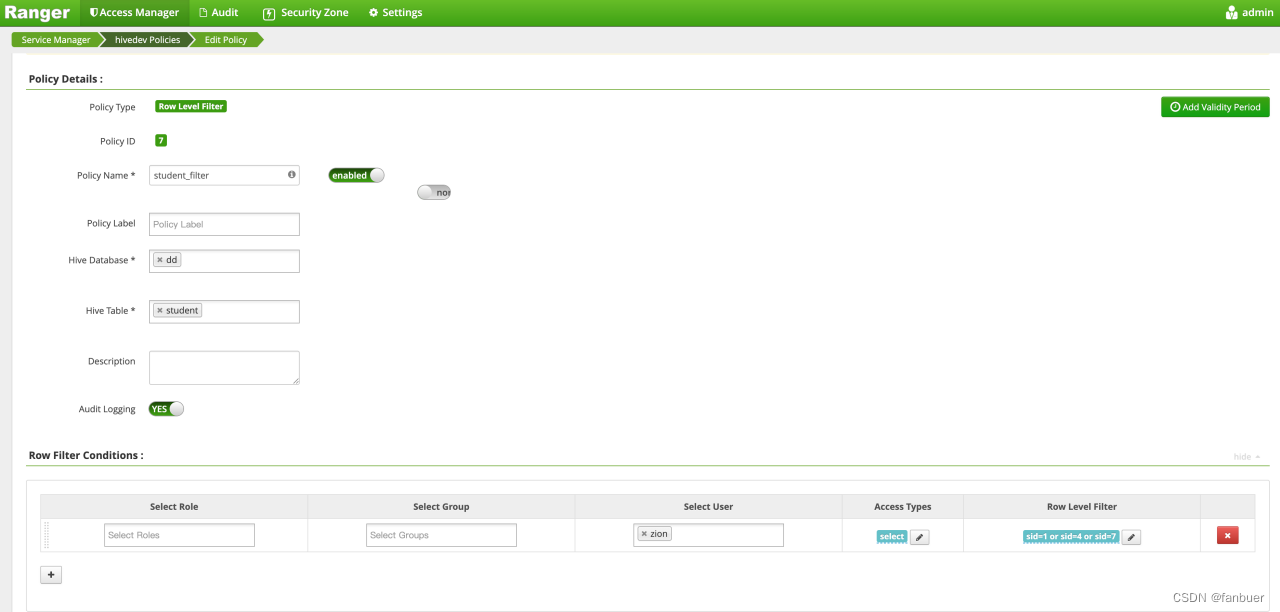
看下效果

5.Ranger yarn-plugin
5.1安装
5.1.1 解压软件
[root@bigdb01 ~]# rsync root@bigdb03:/data/fan/install/native/10.ranger/package/ranger-2.0.0-yarn-plugin.tar.gz /opt/software
[root@bigdb01 ~]# tar -zxvf /opt/software/ranger-2.0.0-yarn-plugin.tar.gz -C /opt/module/ranger/5.1.2 修改配置文件
[root@bigdb01 ~]# cd /opt/module/ranger/ranger-2.0.0-yarn-plugin/
[root@bigdb01 ranger-2.0.0-yarn-plugin]# vim install.properties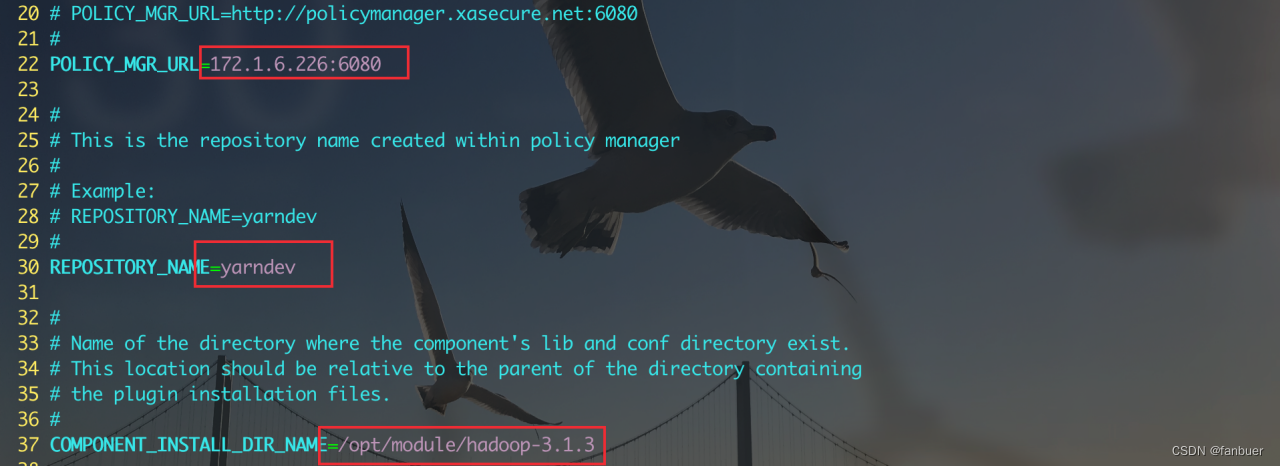

5.1.3 使yarn-plugin生效
[root@bigdb01 ranger-2.0.0-yarn-plugin]# ./enable-yarn-plugin.sh
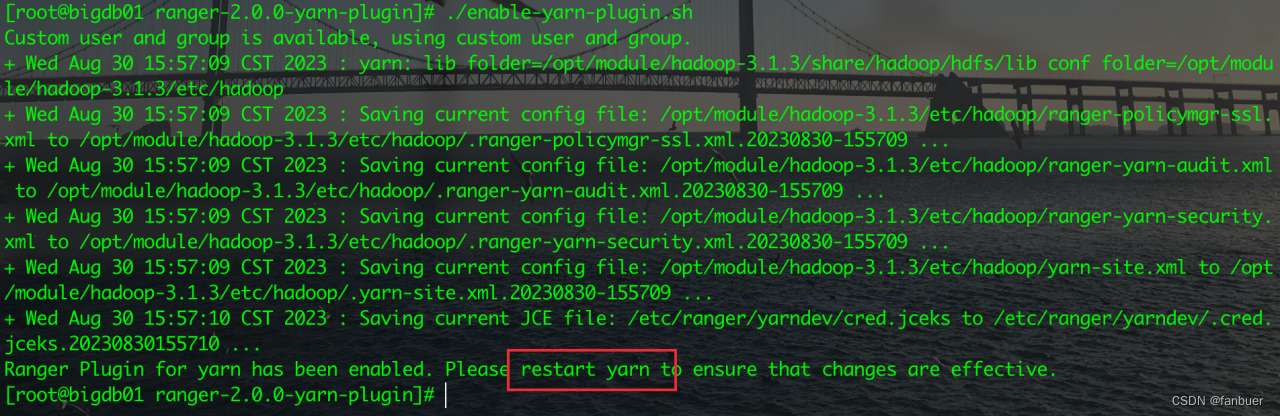
5.1.4 重启yarn
[root@bigdb01 ~]# hdp.sh stop [root@bigdb01 ~]# hdp.sh start
5.1.5 页面配置
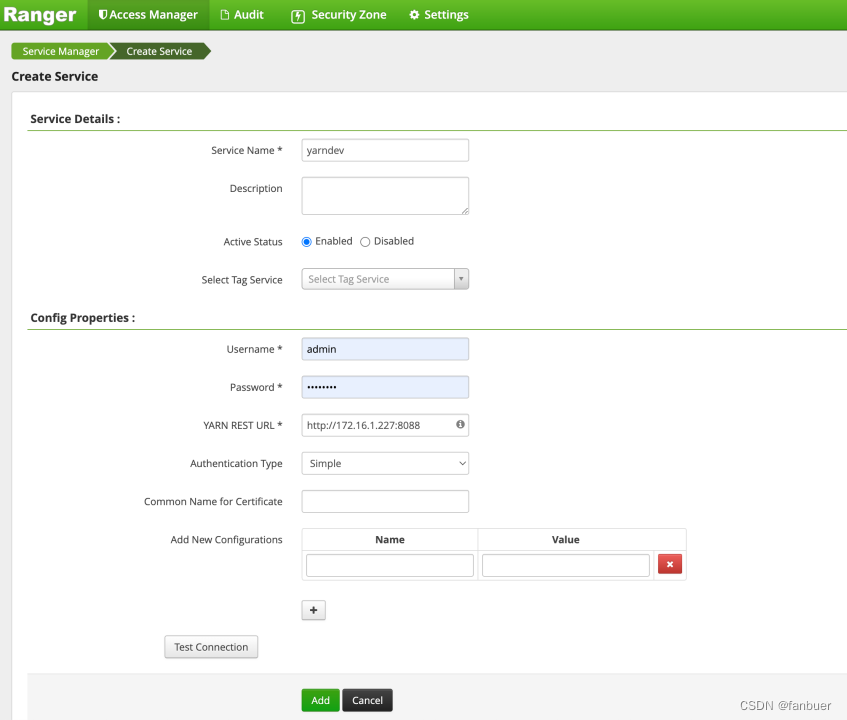
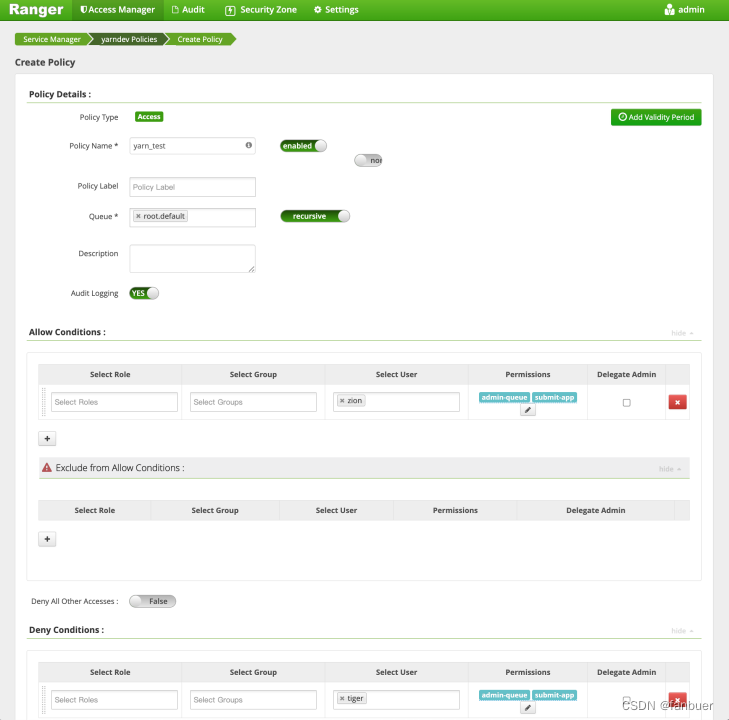
4.Ranger hdfs-plugin
4.1安装
4.1.1 解压
[root@bigdb01 ~]# rsync root@bigdb03:/data/fan/install/native/10.ranger/package/ranger-2.0.0-hdfs-plugin.tar.gz /opt/software
[root@bigdb01 ~]# tar -zxvf /opt/software/ranger-2.0.0-hdfs-plugin.tar.gz -C /opt/module/ranger/4.1.2 配置
[root@bigdb01 ~]# vim /opt/module/ranger/ranger-2.0.0-hdfs-plugin/install.properties
修改一下内容
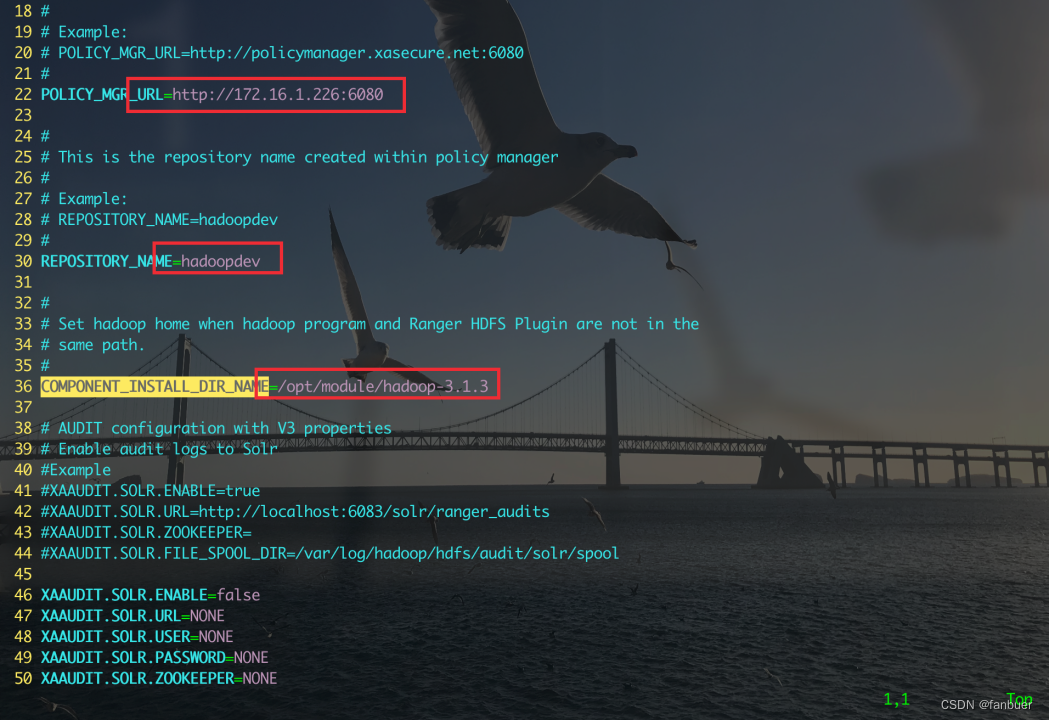

4.1.3 使hdfs-plugin生效
[root@bigdb01 ranger-2.0.0-hdfs-plugin]# ./enable-hdfs-plugin.sh
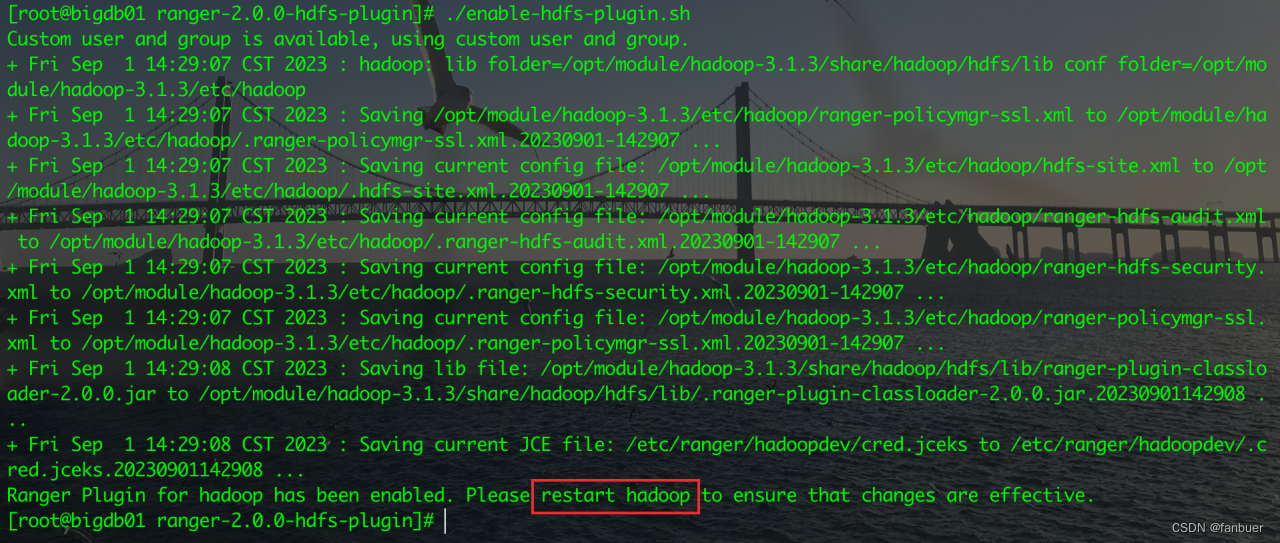
重启hadoop
[root@bigdb01 ~]# hdp.sh stop [root@bigdb01 ~]# hdp.sh start
4.2 测试
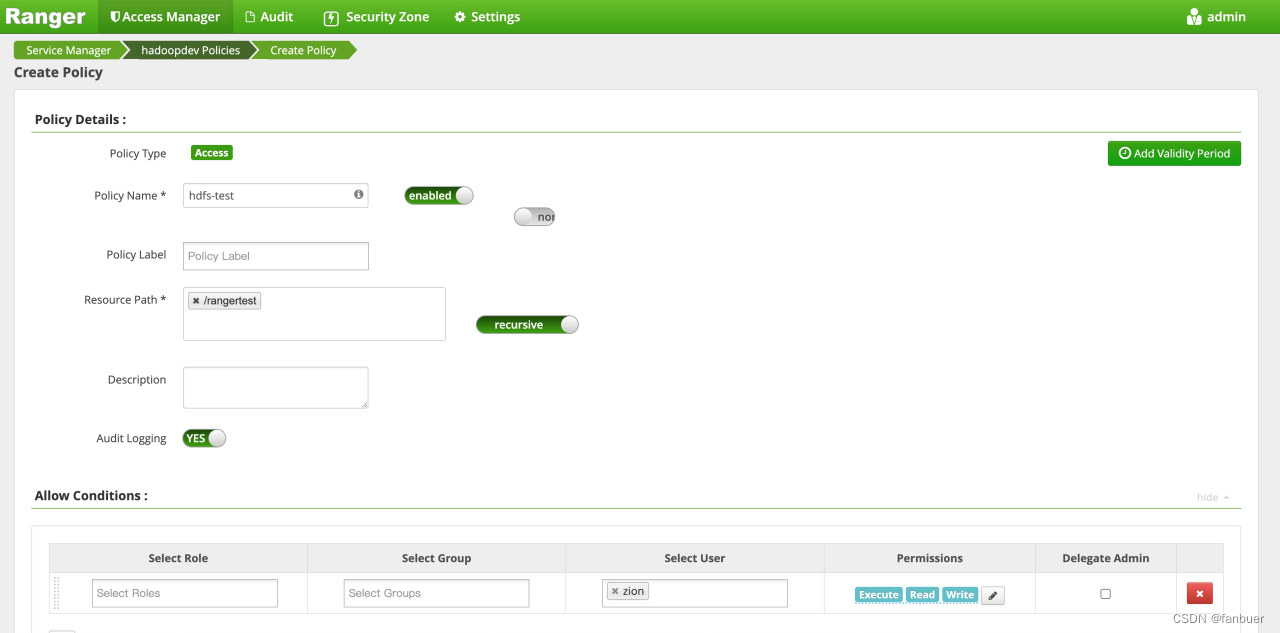
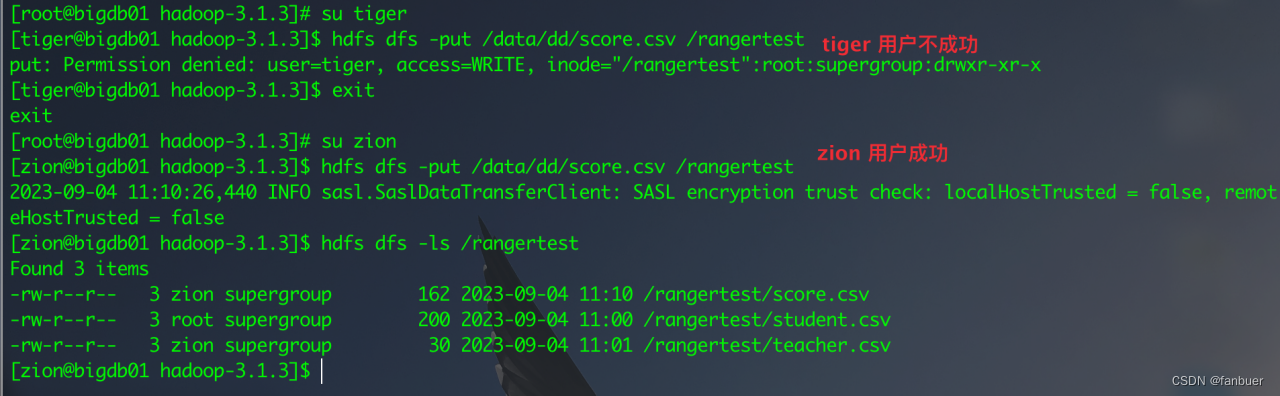
使用root在hdfs上创建一个文件夹rangertest,并且用root用户上传一个文件到该文件夹下,切换为zion用户去查看数据,可以查看,上传文件到改文件夹下,失败!
4.2.1 上传文件
创建目录 /rangertest
[root@bigdb01 ~]# hdfs dfs -mkdir /rangertest [root@bigdb01 ~]# hadoop fs -ls /
上传文件student.csv
[root@bigdb01 ~]# hdfs dfs -put /data/dd/student.csv /rangertest
[root@bigdb01 ~]# hadoop fs -ls /rangertest
4.2.2 用zion用户操作
切换zion用户,并查看文件内容
[root@bigdb01 ~]# su zion [root@bigdb01 ~]# hdfs dfs -cat /rangertest/student.csv
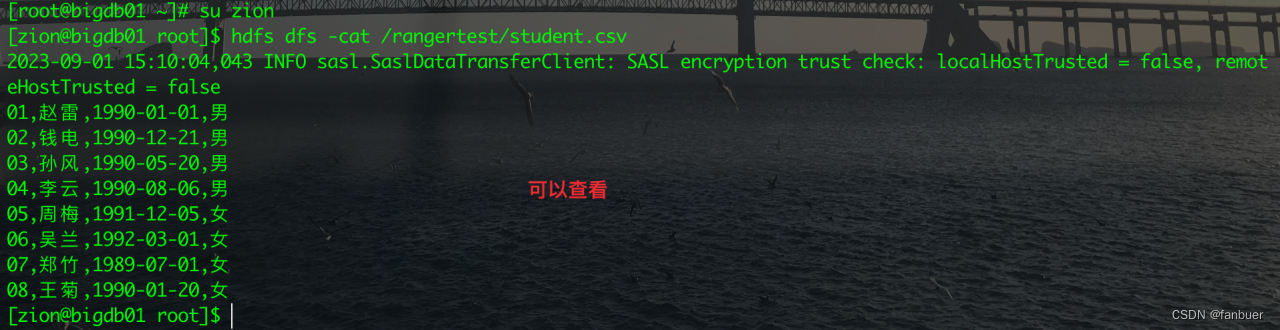
通过用户zion上传文件到 /rangertest目录下
[root@bigdb01 ~]# su zion
[zion@bigdb01 root]$ hdfs dfs -put /data/dd/teacher.csv /rangertest
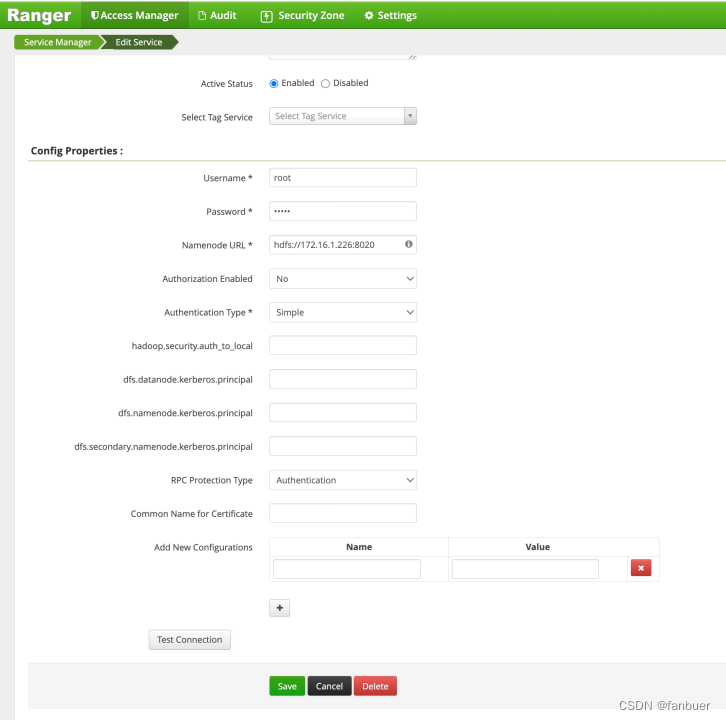
4.2.3 页面配置hdfs-plugin参数
这篇关于Ranger安装和使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





