本文主要是介绍亚马逊云科技赋能敦煌网集团上云,云上新架构带来价值,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
敦煌网成立于2004年,是领先的B2B跨境电子商务交易平台,敦煌网在品牌优势、技术优势、运营优势、用户优势四大维度上,已建立起竞争优势。随着跨境电商的日趋成熟,经营范围持续扩大、品类和渠道的增加,以及AIGC等行业新技术在运营提效场景下的广泛应用,对沉淀近20年的大数据进行深度挖掘、洞察和使用,给亚马逊云科技带来成本、算力、效率、安全的新挑战。
之前传统IDC大数据集群,维护成本高、无法实现弹性伸缩、计算存储耦合、算力瓶颈扩容周期长等问题越发严重,无法响应业务快速发展。
预期上云实现目标
● 智能湖仓架构
建设智能湖仓架构,将数据的采集、传输、存储、分析、应用全流程各环节无缝衔接,实现数据的集中存储和管理,提高数据的流转效率、数据质量、可靠性和安全性。对数据进行深度挖掘、智能分层和热力分析,提高数据的价值和利用率。
● 精细化运营成本管控
建立云资源的精细化运营和成本管控制度,提高资源利用率并降低成本。实现资源随业务灵活扩缩,提高业务的灵活性和响应速度。利用云原生的智能分层、自动化管理和运维能力,提高运维效率和质量。
● 一站式数据平台底座
打造集数据集成、数据开发、数据资产管理、数据服务等一站式大数据平台,实现“快、准、全、稳”的数仓体系,达到数据驱动决策,算法增长业务的目标。平台提供数据可视化和报表分析工具,帮助业务人员更好地理解和利用数据,提高业务决策的准确性和效率。
数据架构及技术方案
敦煌大数据的技术组件及架构(IDC)
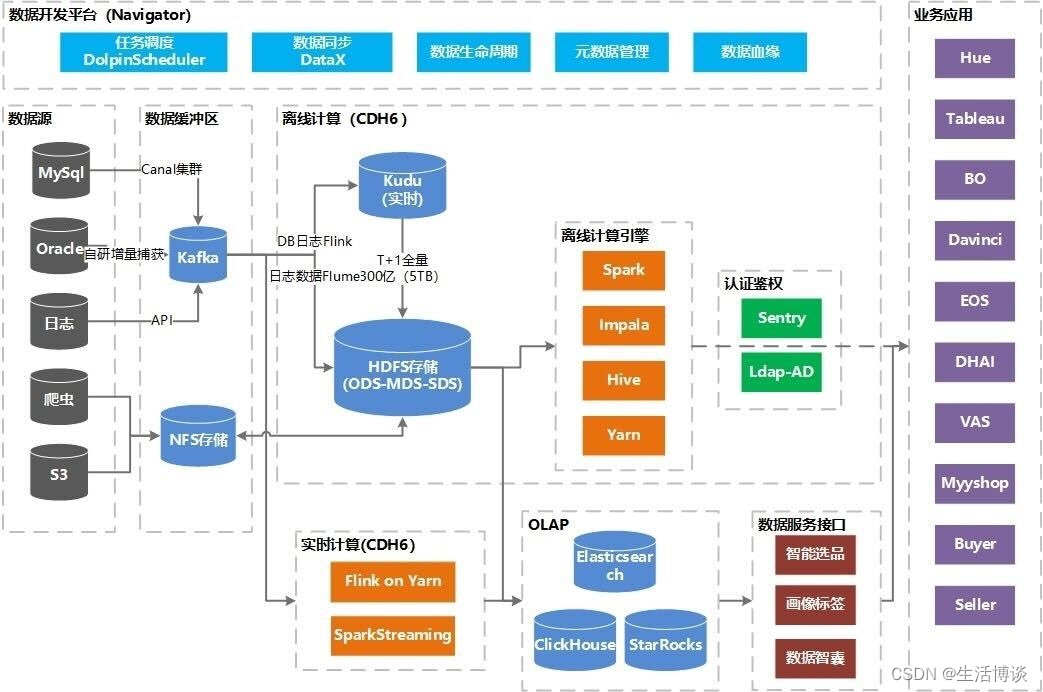
IDC大数据环境基于CDH、大数据开源生态组件、商业及自研工具构建。
数据源:包含上百个MySQL、Oracle以及NoSQL数据库实例,数万张源表(分库分表),数十TB数据。
数据缓冲区:每天数十亿条数据库增量数据,用户行为日志数据实时发送到Kafka集群,保证了数据高可用的同时,满足了离线和实时大规模数据分析处理的需求。
离线计算和实时计算集群:使用CDH6.x搭建大数据集群,借助于Cloudera Manager可方便地管理和部署Hadoop集群,并进行可视化监控和故障诊断。提供稳定可靠的离线、实时的计算引擎服务。
OLAP引擎:按不同应用场景需求配置了ElasticSearch、ClickHouse、StarRocks查询引擎提供买卖家、业务运营的在线查询服务。
业务应用:常用的报表及可视化工具:Hue、Tableau、BO,自研的EOS系统和对接服务化接口等业务应用。
数据安全:集成了Kerberos+Sentry+Ldap提供统一用户认证与鉴权,保障了数据安全。其中,Kerberos提供了身份验证协议的基础,Sentry提供了细粒度的授权控制,LDAP则提供了用户和组信息的管理功能。这些技术的结合极大提高大数据集群的安全性和管理效率。
数据开发平台:亚马逊云科技的数据开发平台采用了开源和自研技术相结合的方案。其中,任务调度部分采用DolphinScheduler实现,数据集成部分在DataX基础上进行二次开发,实现了可视化配置。此外,亚马逊云科技还注重数据血缘、元数据以及生命周期管理等方面,专门进行了针对性的研发。
云上新架构能够带来的价值
● 弹性伸缩:基于亚马逊云科技的EMR存算分离架构,在计算层可以根据数据分析任务去灵活调度不同的算力,支持分钟级别的计算实例弹缩,解决了IDC资源从采购到部署上线需要的漫长时间和提前预制算力可能产生的资源浪费。
● 性能提升:Amazon EMR上Spark Runtime性能相比开源Spark提升1.7~2倍左右,相同的资源使用下,可以更快的完成作业的执行。Presto也做了Runtime的优化,性能相比OSS快2.7倍左右,接入OLAP的引擎做交互式查询分析,也会从中受益。
● 成本节省:Amazon EMR可以根据计算需求变化灵活扩缩集群调整集群,在工作负载高峰时增加实例,在工作负载高峰过后移除实例。Amazon EMR还提供了运行多个实例组的选项,可以在一个组中使用按需实例来保障处理能力,同时在另一个组中使用竞价型实例来加快任务完成速度并降低成本,可以利用混合多种实例类型以充分利用某种竞价型实例类型的定价优势。应用S3的智能分层去自动化管理数据生命周期,在不影响数据读写性能的同时相比IDC大幅降低存储成本。
● 开发效率:Amazon EMR是全托管的云端数据平台,支持常驻、瞬态集群模式去分别适配每天的常规离线任务、临时数据分析和Ad-Hoc的任务,支持通过控制台界面或者API快速构建集群的能力,可以很方便和现有的大数据平台做集成,避免了传统自建集群日常维护的工作量,让大数据团队可以把更多的时间投入到技术探索中。
● 平台化数据底座:应用亚马逊云科技的智能湖仓架构,提供一个统一的、可共享的数据底座,避免传统的数据湖、数据仓库之间的数据移动,将原始数据、加工清洗数据、模型化数据,共同存储于一体化的“湖仓”中,既能面向业务实现高并发、精准化、高性能的历史数据、实时数据的查询服务,又能承载分析报表、批处理、数据挖掘等分析型业务。
这篇关于亚马逊云科技赋能敦煌网集团上云,云上新架构带来价值的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







