本文主要是介绍在oracle中的scn技术,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
SCN可以说是Oracle中一个很基础的部分,但同时它也是一个很重要的。它是系统中维持数据的一致性和顺序恢复的重要标志,是数据库非常重要的一种数据结构。
转载:深入剖析 - Oracle SCN机制详细解读 - 知乎 (zhihu.com)![]() https://zhuanlan.zhihu.com/p/31446957
https://zhuanlan.zhihu.com/p/31446957
SCN介绍
SCN即系统改变号(System Change Number),是在某个时间点定义数据库已提交版本的时间戳标记。 Oracle为每个已提交的事务分配一个唯一的SCN。 SCN的值是对数据库进行更改的逻辑时间点。 Oracle使用此编号记录对数据库所做的更改。在数据库中,SCN也可以说是无处不在,数据文件头,控制文件,数据块头,日志文件等等都标记着SCN。也正是这样,数据库的一致性维护和SCN密切相关。不管是数据的备份,恢复都是离不开SCN的。
SCN是一个6字节(48bit)的数字,其值为281,474,976,710,656(2^48),分为2个部分:
SCN_BASE是一个4字节(32bit)的数字
SCN_WRAP是一个2字节(16bit)的数字
每当SCN_BASE达到其最大值(2^32 = 4294967296)时,SCN_WRAP增加1,SCN_BASE将被重置为0,一直持续到SCN_WRAP达到其最大值,即2^16 = 65536。
SCN =(SCN_WRAP * 4294967296)+ SCN_BASE
SCN随着每个事务的完成而增加。提交不会写入数据文件,也不更新控制文件。当发生checkpoint时,控制文件更新,SCN被写入到控制文件。
当前的SCN可以通过以下查询获得:
select dbms_flashback.get_system_change_number scn from dual;
select current_scn from v$database;
四种重要的SCN
在理解这几种SCN之前,我们先看下oracle事务中的数据变化是如何写入数据文件的:
第一步:事务开始;
第二步:在buffer cache中找到需要的数据块,如果没找到,从数据文件中载入buffer cache中;
第三步:事务修改buffer cache的数据块,该数据被标识为“脏数据”,并被写入log buffer中;
第四步:事务提交,LGWR进程将log buffer中的“脏数据”的日志条目写入redo log file中;
第五步:当发生checkpoint,CKPT进程更新所有数据文件的文件头中的信息,DBWn进程则负责将Buffer Cache中的脏数据写入到数据文件中。
经过上述5个步骤,事务中的数据变化最终被写入到数据文件中。但是,一旦在上述中间环节数据库意外宕机了,在重新启动时如何知道哪些数据已经写入数据文件、哪些没有写呢?(同样,在DG、streams中也存在类似疑问:redolog中哪些是上一次同步已经复制过的数据、哪些没有)
SCN机制就能比较完善的解决上述问题。 SCN是一个数字,确切的说是一个只会增加、不会减少的数字。正是它这种只会增加的特性确保了 Oracle知道哪些应该被恢复、哪些应该被复制。
总共有4种SCN:
系统检查点(System Checkpoint)SCN
数据文件检查点(Datafile Checkpoint)SCN
结束SCN(Stop SCN)
开始SCN(Start SCN)
(1)System Checkpoint SCN
当checkpoint完成后,ORACLE将System Checkpoint SCN号存放在控制文件中。我们可以通过下面SQL语句查询:
select checkpoint_change# from v$database;
(2)Datafile Checkpoint SCN
当checkpoint完成后,Oracle将Datafile Checkpoint SCN存放在控制文件中。我们可以通过下面SQL语句查询所有数据文件的Datafile Checkpoinnt SCN。
select name,checkpoint_change# from v$datafile;
(3)Start SCN
Oracle将StartSCN存放在数据文件头中。这个SCN用于检查数据库启动过程是否需要做media recovery。我们可以通过以下SQL语句查询:
select name,checkpoint_change# from v$datafile_header;
(4)Stop SCN
ORACLE将StopSCN存放在控制文件中。这个SCN号用于检查数据库启动过程是否需要做instance recovery。我们可以通过以下SQL语句查询:
select name,last_change# from v$datafile;
在数据库正常运行的情况下,对可读写的online数据文件,该SCN号为NULL。
SCN与数据库启动:
在数据库启动过程中,当System Checkpoint SCN、Datafile Checkpoint SCN和Start SCN都相同时,数据库可以正常启动,不需要做media recovery。三者当中有一个不同时,则需要做media recovery.如果在启动的过程中,End SCN为NULL,则需要做instance recovery。Oracle在启动过程中首先检查是否需要media recovery,然后再检查是否需要instance recovery。
SCN与数据库关闭:
如果数据库的正常关闭的话,将会触发一个checkpoint,同时将数据文件的END SCN设置为相应数据文件的Start SCN。当数据库启动时,发现它们是一致的,则不需要做instance recovery。在数据库正常启动后,ORACLE会将END SCN设置为NULL.如果数据库异常关闭的话,则END SCN将为NULL。
Q&A
Q
为什么ORACLE在控制文件中记录System checkpoint SCN 号的同时,还需要为每个数据文件记录DatafileCheckpoint SCN?
A
如果有表空间read only,那么该表空间的所有datafile的start SCN和stop SCN将被冻结,这个时候就跟System Checkpoint SCN不一致,但在库open的时候是不需要做media recovery的,如果没有DatafileCheckpoint SCN就无法判断这些datafile是否是最新的。
可能遇到的SCN问题
首选我们看几个跟SCN有关的概念:
Reasonable SCNLimit(RSL)
RSL = (当前时间 - 1988年1月1日)*24*3600*SCN每秒最大可能增长速率
也就是从1988年1月1日开始,假如SCN按最大速率增长,当天理论上的最大值。
最大增长速率:在11.2.0.2之前是16384,在11.2.0.2及之后版本是32768
在11.2.0.2版本之后由_max_reasonable_scn_rate参数控制

该参数不建议修改。
SCN Headroom
Headroom(天) = (Reasonable SCN Limit -CurrentSCN)/ SCN每秒最大可能增长速率/3600/24
也就是如果SCN按最大速率增长,达到当前理论最大值需要的天数。这个值可以用来判断SCN增长速率是否过快。
那么,SCN Headroom如果获取呢?
参考MOS: Bug 13498243 -"scnhealthcheck.sql" script (文档 ID 13498243.8),打上该BUG的patch之后,将在$ORACLE_HOME/rdbms/admin中增加scnhealthcheck.sql文件,该文件就是用来检查SCN是否正常。
另外还有一篇MOS文档,专门对该脚本的输出做了解释。即Installing, Executing and Interpreting output from the"scnhealthcheck.sql" script (文档 ID 1393363.1)。
执行该脚本,结果如下:
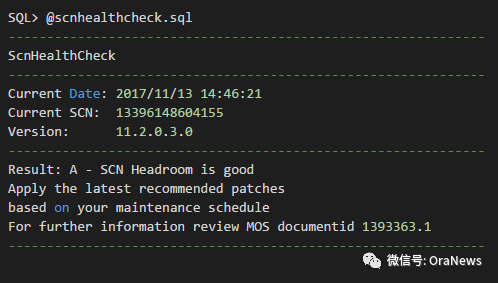
这个结果我们仍然无法得到该数据库的具体SCN Headroom,下面这个SQL是从scnhealthcheck.sql中找到的,可以直接查到SCN Headroom的值(indicator字段)。

Q&A
Q
针对上面的查询结果,是不是意味着过1647天之后,SCN就将达到最大值?
A
不会,因为1647天之后,Current SCN会变大,Reasonable SCN Limit同样也会变大,正常情况下,SCNHeadroon只会变大不会变小。
SCN headroom过小的问题
如果SCN正常增长,达到最大值大约可以用500年,SCN headroom的值也会随着时间的推移慢慢变大,但是可能由于BUG、用特殊手段人为调整、dblink传播导致SCN增长出现异常。但如果出现SCN headroom过小,alert log会出现警告:Warning: The SCN headroom for this database is only NN days!
原因定位:
1. 通过下面这篇文档里提供的脚本,该脚本类似于创建AWR,可以按snap_id对dba_hist_sysstat里的某个stat_name做统计,我们这里的Stat_name选择calls to kcmgas。
How to Extract the Historical Values of aStatistic from the AWR Repository (文档 ID 948272.1)
2. 通过查询V$ARCHIVED_LOG单位时间内scn变化
3. 通过上面两个方式得出的结果分析,如果是非持续突发增长,认为很可能是通过dblink引起;
4. 同时比较awr报告中“callsto kcmgas” 和“user commits”,如果user commits也是高速增长,很可能是自身引起;
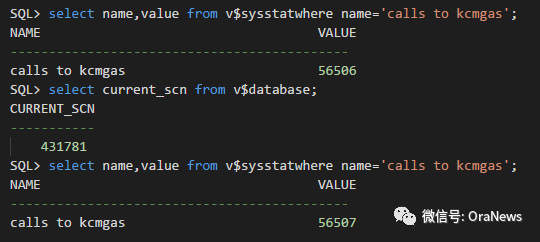
kcmgas是Oracle分配scn的函数,在一个空库上做测试,可以看出每分配一次scn,calls to kcmgas的统计增加1,所以calls to kcmgas的量可以作为scn的增长量来分析。
ORA-19706: Invalid SCN错误
[1376995.1]里的介绍,在2012年1月CPU或PSU里增加_external_scn_rejection_threshold_hours参数,11.2.0.2及以后的版本,默认为1天即24小时,其他版本默认为31天即744小时,相当于把拒绝外部SCN连接的阈值调大了,因而更加容易引发ORA-19706错误。该参数对数据库自身产生的SCN递增没有影响。Bug 13554409 - Fix for bug13554409 [ID 13554409.8]的里对该问题也有介绍。
ORA-19706错误:最常见的就是拒绝dblink连接的时候,如A库跟B库通过dblink连接,A的SCN有通过人为调整增大许多,连接B库的时候,Oracle会判断该SCN传播过来之后,如果会导致SCN headroom小于_external_scn_rejection_threshold_hours设置的阈值,则拒绝连接
相关参考:SCN、ORA-19706错误和_external_scn_rejection_threshold_hours参数
如果打完2012年1月CPU或PSU后遇到ORA-19706错误,对于以下这些版本的数据库:
Oracle 10.2.0.5
Oracle 11.1.0.7
Oracle 11.2.0.2
Oracle 11.2.0.3
oracle建议给数据库安装2012年4月发布的PSU,并在安装该PSU的基础上,安装补丁13916709。如果是集群架构,同时给集群软件最新安装PSU。参数_external_scn_rejection_threshold_hours在2012年4月(包含2012年4月)以后发布的PSU/CPU中,11.2.0.2及以后的版本,是1天即24小时,其他版本是31天即744小时。其他版本:先升级到高版本,再按照上面的方法处理。
总结
如果发现SCN有异常,需要及时通过上述方法来打上最新的PSU,同时尽量少用DBLINK,从系统设计角度来讲也是不推荐这种系统间强耦合的设计。
这篇关于在oracle中的scn技术的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





