本文主要是介绍使用paddledetection的记录,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
首先在这里使用的是是paddle--detection2.7的版本。

成功进行训练
目录:
目录
数据集准备
配置文件的修改
使用的是BML的平台工具:
!python -m pip install paddlepaddle-gpu==2.5 -i https://mirror.baidu.com/pypi/simple --user
%cd /home/aistudio/
# !wget https://codeload.github.com/PaddlePaddle/PaddleDetection/zip/refs/heads/release/2.7
#因为github需要登录,所以下载不成功,因此这里直接上传了2.7的版本
# !unzip /home/aistudio/PaddleDetection-release-2.7.zip
%cd /home/aistudio/PaddleDetection-release-2.7/
!pip install -r requirements.txt
!python setup.py install
#用来测试是否安装成功,另外补充安装一个numba
!pip install numba==0.56.4
# !python ppdet/modeling/tests/test_architectures.py要求的paddle版本必须是大于2.3.2的。注意版本问题就是了配置环境的时候,其他的大问题没什么。
下面这段代码,可以用来确认是否安装成功指定版本:
import paddle
paddle.utils.run_check()
# 确认PaddlePaddle版本
!python -c "import paddle; print(paddle.__version__)"如果成功,则会打印如下信息:
PaddlePaddle works well on 1 GPU. PaddlePaddle is installed successfully! Let's start deep learning with PaddlePaddle now. 2.5.0
然后就是准备数据集了,在这里我使用的是开源的MOT17数据集,这个数据集,只有训练集,没有测试集,下载和解压命令如下:
!wget https://bj.bcebos.com/v1/paddledet/data/mot/MOT17.zip
!unzip /home/aistudio/data/MOT17.zip -d /home/aistudio/PaddleDetection-release-2.7/dataset/mot/数据集准备:
提到数据集,在这里延伸的扩展一哈,paddledetection里面对于数据集的要求(仅限多目标跟踪)有如下几种格式:
1、自定义数据集;
2、一类纯检测框标注的数据集,仅SDE系列(ByteTrack)可以使用;
3、另一类是同时有检测和ReID标注的数据集,SDE系列(DeepSORT)和JDE系列都可以使用
因此下面的数据集准备会分成两种来讲:
****************
ReID标注是一种目标跟踪的标注方法,它基于深度学习技术进行目标跟踪。在ReID标注中,需要对视频序列中的目标进行标记和追踪,以便在多个摄像头监控的画面中实现目标跟踪。这种标注方法有助于提高目标跟踪的准确性和稳定性。
***************
其中自定义数据集参考:PaddleDetection/docs/tutorials/data/PrepareDetDataSet.md at release/2.7 · PaddlePaddle/PaddleDetection (github.com)
首先:SDE数据集是纯检测标注的数据集,可以按照自定义数据集准备成(VOC,或者是COCO数据集)
这里以这个MOT17的数据集来作为例子,进行举例:

数据集下载解压以后有三个文件夹:
第一个是annotations是
里面包含的信息有:如下内容(图片路径,注意这里的图片路径是用的是在后面我们会提到的dataset_dir的基础上添加的路径)

可以看到上面的train有两种,第一种half的意思是:在MOT17/images/half中,它可能指的是存储在图像中的目标物体的标注信息,例如边界框信息、分割信息、类别信息等,这些信息以半精度浮点数的形式进行存储和计算,可以提高模型的计算效率和准确性。
第二个是images文件夹
每个子目录下都是一段视频的抽帧图片及标注。

det
训练集中/det 文件夹中是针对检测的信息,该目录下只有一个det.txt文件,每行一个标注,代表一个检测的物体。

参数说明:每一行标注的含义如下:第一个代表第几帧,第二个代表轨迹编号(因为检测结果只看检测框质量,不看id,故为id=-1。),bb开头的4个数代表物体框的左上角坐标及长宽。conf代表置信度。
gt
训练集中/gt 文件夹中是针对追踪的信息,该目录下只有一个gt.txt文件(相当于half里面的一个gt_all.txt文件,而half里面的gt.txt只有一半的帧长),每行一个标注,代表一个检测的物体。
每一行标注的含义如下:第一个代表第几帧,第二个值为目标运动轨迹的ID号,bb开头的4个数代表物体框的左上角坐标及长宽,第7个值为目标轨迹是否进入考虑范围内的标志,0表示忽略,1表示active。第八个值为该轨迹对应的目标种类(种类见下面的表格中的label-ID对应情况),第九个值为box的visibility ratio,表示目标运动时被其他目标box包含/覆盖或者目标之间box边缘裁剪情况。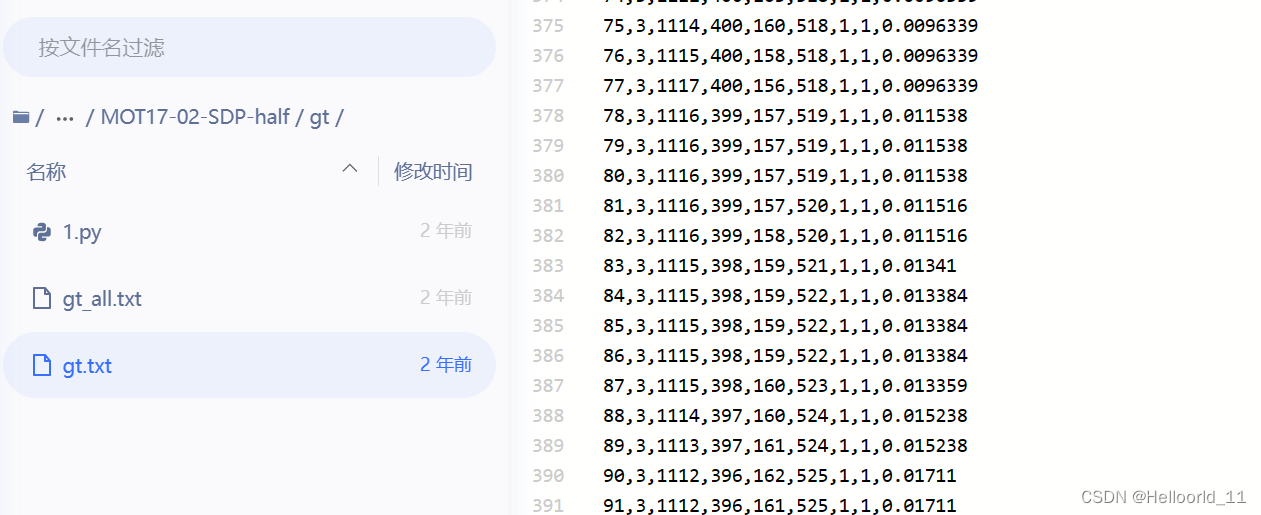
img1里面存放的就是图片了;
然后就是seqinfo.ini文件

介绍视频的帧率、分辨率等基本信息(分割片段名;图片路径;该子集的帧率,每秒30帧;表示该子集的长度600帧,以帧数为单位;图片的宽度;高度;后缀名)
最后就是labels_with_ids,是指
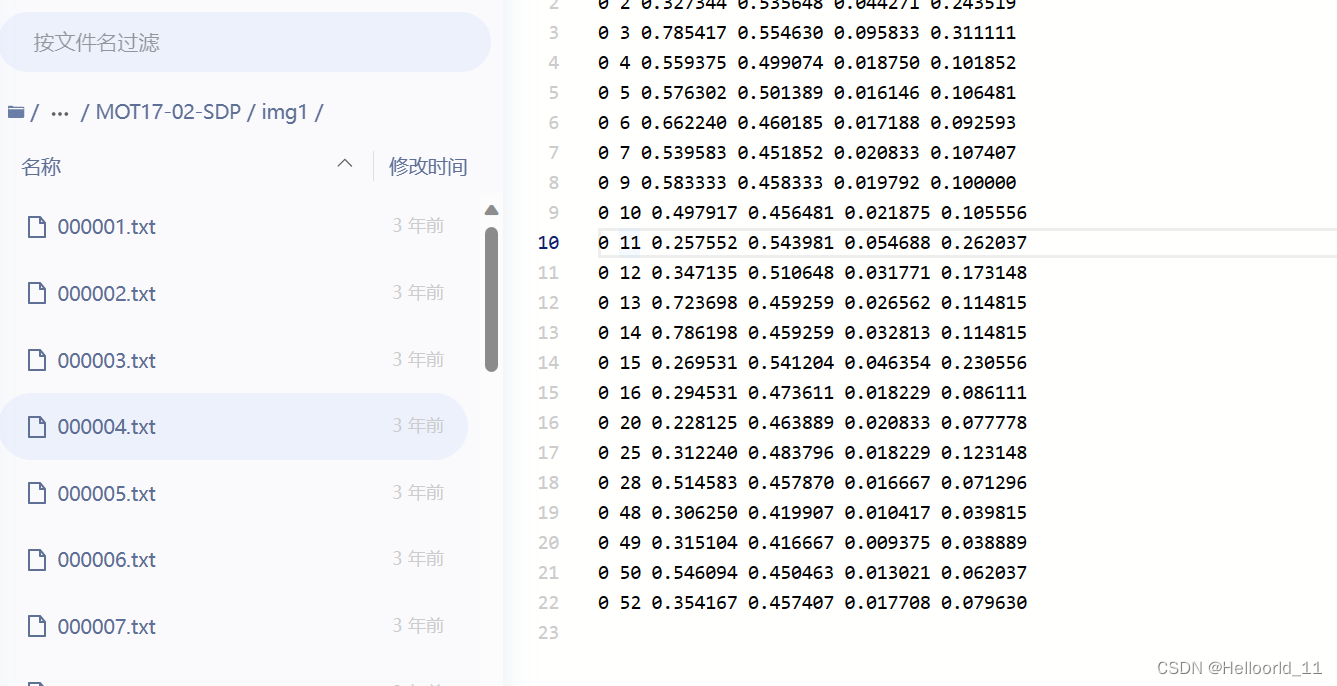
在标注文本中,每行都描述一个边界框,格式如下:
[class] [identity] [x_center] [y_center] [width] [height]
class为类别id,支持单类别和多类别,从0开始计,单类别即为0。identity是从1到num_identities的整数(num_identities是数据集中所有视频或图片序列的不同物体实例的总数),如果此框没有identity标注,则为-1。[x_center] [y_center] [width] [height]是中心点坐标和宽高,注意他们的值是由图片的宽度/高度标准化的,因此它们是从0到1的浮点数。
配置文件的修改
在2.7版本,这里用ByteTrack来训练MOT17的数据集举例:
训练的命令是:
!python -m paddle.distributed.launch --log_dir=ppyoloe --gpus 0 tools/train.py -c configs/mot/bytetrack/detector/ppyoloe_crn_l_36e_640x640_mot17half.yml --eval --amp主要的配置文件是这个:ppyoloe_crn_l_36e_640x640_mot17half.yml,在 configs/mot/bytetrack/detector/下面

修改的是mot2.yml,这是自己新建的一个文件,用来重新定义数据集的路径!
这篇关于使用paddledetection的记录的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





