本文主要是介绍Python编程题集(第三部容器操作 ),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Demo61 指定等级
题目描述
读入学生成绩,获取最高分best,然后根据下面的规则赋等级值:
(1)如果分数≥best-10,等级为A
(1)如果分数≥best-20,等级为B
(1)如果分数≥best-30,等级为C
(1)如果分数≥best-40,等级为D
(1)其他情况,等级为F
输入输出描述
输入两行,第一行输入学生人数n,第二行输入n个学生的成绩
输入n行,表示每个学生的成绩等级示例
输入:
4
40 55 70 58
输出:
学生0分数为40,等级为C
学生1分数为55,等级为B
学生2分数为70,等级为A
学生3分数为58,等级为B
代码如下:
def student_mark(Chinese_score,Math_score,English_score):dict_score = {'Chinese_score': Chinese_score, 'Math_score': Math_score, 'English_score': English_score}return dict_score
def labeled_rating(Chinese_score,Math_score,English_score,dict_score):arr_score = list(dict_score.values())best = max(arr_score)for i in dict_score.values():if i >= best - 10:return "等级为A"elif i >= best - 20:return "等级为B"elif i >= best - 30:return "等级为C"elif i >= best - 40:return "等级为D"else:return "等级为f"Chinese_score,Math_score,English_score = map(int,input("请依次输入该同学的语文数学和英语成绩(使用逗号隔开):").split(","))
# 调用函数获取成绩字典
dict_scores = student_mark(Chinese_score, Math_score, English_score)
# 根据成绩字典计算等级
grade = labeled_rating(Chinese_score, Math_score, English_score, dict_scores)
print(grade)def student_mark(Chinese_score, Math_score, English_score):# 创建一个字典,包含语文、数学和英语成绩dict_score = {'Chinese_score': Chinese_score, 'Math_score': Math_score, 'English_score': English_score}return dict_scoredef labeled_rating(Chinese_score, Math_score, English_score, dict_score):# 将字典的键转换为列表arr_score = list(dict_score.values())# 获取最高分best = max(arr_score)for i in dict_score.values():if i >= best - 10:return "等级为A"elif i >= best - 20:return "等级为B"elif i >= best - 30:return "等级为C"elif i >= best - 40:return "等级为D"else:return "等级为F"# 输入学生的语文、数学和英语成绩
Chinese_score, Math_score, English_score = map(int, input("请依次输入该同学的语文数学和英语成绩(使用逗号隔开):").split(","))
# 调用函数获取成绩字典
dict_scores = student_mark(Chinese_score, Math_score, English_score)
# 根据成绩字典计算等级
grade = labeled_rating(Chinese_score, Math_score, English_score, dict_scores)
print(grade)
Demo62 计算数字的出现次数
题目描述
读取1到100之间的整数,然后计算每个数出现的次数
输入输出描述
输入两行,第一行为整数的个数n,第二行为n个整数
输出多行,每行表示某数及其出现的次数,顺序按照数字从小到大
示例
输入:
9
2 5 6 5 4 3 23 43 2
输出:
2出现2次
3出现1次
4出现1次
5出现2次
6出现1次
23出现1次
43出现1次
代码如下:
#读取输入:
n = int(input("请输入你要输入的数字的个数:")) #整数的个数
num_list = list(map(int , input("请输入n个1-100的整数:").split(" "))) #n个整数的输入#初始化一个字典用来存储数字的出现个数:
count_dict = {}
#计算每个数字的出现个数
for i in num_list:if i in count_dict:count_dict[i] += 1else:count_dict[i] = 1
#从小到大的顺序输出:
for key in sorted(count_dict.keys()):print(f"{key}出现了{count_dict[key]}次")Demo63 打印不同的数
题目描述
读入n个数字,并显示互不相同的数(即一个数出现多次,但仅显示一次),数组包含的都是不同的数
输入输出描述
输入两行,第一行为数字的个数n,第二行为n个数字
输出数组,包含的都是不同的数
示例
输入:
10
1 2 3 2 1 6 3 4 5 2
输出:
1 2 3 6 4 5
代码如下:
#读取输入:
n = int(input("请输入你要输入的数字的个数:")) #整数的个数
num_list = list(map(int , input("请输入n个的整数:").split(" "))) #n个整数的输入
# 将列表转换成集合,是的元素不能重合
num_set = set(num_list)
# print(num_set)
for i in num_set:print(i, end = " ")Demo64 最大公约数II
题目描述
输入n个数字,求该n个数字的最大公约数
输入输出描述
输入两行,第一行为数字个数n,第二行为n个整数
输出最大公约数
示例
输入:
9 12 18 21 15
输出:
3
代码如下:
# 读入数字的数量
n = int(input("请输入你要输入的数字的个数:")) #整数的个数# 读入n个数字
num_list = list(map(int , input("请输入n个的整数:").split(" "))) #n个整数的输入# 使用欧几里得算法求最大公约数
def gcd(a, b):while b != 0:a, b = b, a % breturn agcd_value = gcd(num_list[0], num_list[1])
for i in range(2, n):gcd_value = gcd(gcd_value, num_list[i])print(gcd_value)Demo65 打乱数组
题目描述
编程程序,对给定的数组进行随机打乱,并输出打乱后的结果
代码如下:
import numpy as np
import randomarr_list = np.random.randint(100,size = 5)
print("未排序前的列表为:", arr_list)
random.shuffle(arr_list)
print("打乱后的列表:",arr_list)Demo66 是否有序
题目描述
编写程序,对给定的数组进行判断,判断其数组元素是否非单调递减
输入输出描述
第一行输入测试数据组数T,接下来有2T行,每第一行表示数组长度n,每第二行有n个元素
输出T行,表示该数组是否有序
示例
输入:
3
5
1 2 3 4 5
4
3 1 2 4
5
1 2 2 3 4
输出:
YES
NO
YES
代码如下:
# 使用 Python 编写程序
def is_non_decreasing(arr):return all(arr[i] <= arr[i + 1] for i in range(len(arr) - 1))# 输入测试数据组数
T = int(input("输入测试数据组数:"))# 处理每组测试数据
for _ in range(T):# 输入数组长度n = int(input("输入数组长度:"))# 输入数组元素arr = list(map(int, input("输入数组元素:").split()))# 判断数组是否非单调递减并输出结果if is_non_decreasing(arr):print("YES")else:print("NO")
Demo67 相似词
题目描述
输入两个英文单词,判断其是否为相似词,所谓相似词是指两个单词包含相同的字母
输入输出描述
输入两行,分别表示两个单词
输出结果,为相似词输出YES,否则输出NO
示例
输入:
listen
silent
输出:
YES
代码如下:
# 使用 Python 编写程序
def are_similar_words(word1, word2):# 利用集合去重,并比较两个集合是否相同return set(word1) == set(word2)# 输入两个单词
word1 = input("请输入第一个单词:")
word2 = input("请输入第二个单词:")# 判断是否为相似词并输出结果
if are_similar_words(word1, word2):print("YES")
else:print("NO")
Demo68 豆机器
题目描述
豆机器,也称为梅花或高尔顿盒子,它是一个统计实验的设备,它是由一个三角形直立板和均匀分布的钉子构成,如下图所示:
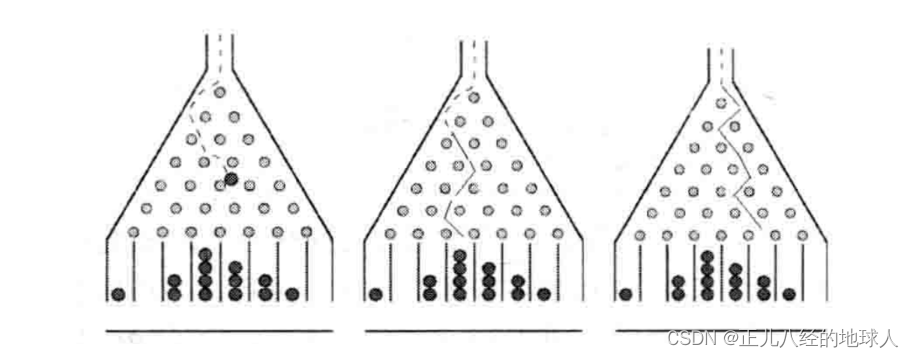
小球从板子的开口处落下,每次小球碰到钉子,它就是50%的可能掉到左边或者右边,最终小球就堆积在板子底部的槽内
编程程序模拟豆机器,提示用户输入小球的个数以及机器的槽数,打印每个球的路径模拟它的下落,然后打印每个槽子中小球的个数
输入输出描述
输入两个数据,分别表示小球个数和槽子的个数
输出每个小球经过的路径,和最终每个槽子里小球的个数(因为牵扯随机数,程序结果不唯一,示例仅用于表明题意)
示例
输入:
5 8
输出:
LRLRLRR
RRLLLRR
LLRLLRR
RRLLLLL
LRLRRLR
0 0 1 1 3 0 0 0
代码如下:
import randomdef simulated_bean_machine(num_balls,num_slots):# 初始化槽子列表,全部置零slot_counts = [0] * num_slots# 对每一个小球进行模拟for ball in range(num_balls):path = " "position = 0 #小球的初始位置在机器的顶部# 模拟小球的路径for _ in range(num_slots - 1):direction = random.choice(["L", "R"]) #左边或是右边path += direction# 根据选择的方向更新小球的位置if direction == "L":position += 1else:position -= 1# 根据小球最终位置更新槽子计数slot_counts[position] += 1# 打印小球的路径print(path)# 打印最终的槽子计数print(" ".join(map(str, slot_counts)))num_balls , num_slots = map(int , input("依次输入小球的个数和槽子得到数量(使用空格隔开):").split(" "))
simulated_bean_machine(num_balls, num_slots)
Demo69 更衣室难题
题目描述
一个学校有100个更衣室和100个学生。所有的更衣室在开学第一天都是锁着的。随着学生进入,第一个学生表示为S1,打开每个更衣室;然后第二个学生S2,从第二个更衣室开始,用L2表示,关闭所有其他更衣室;学生S3从第三个更衣室L3开始,改变每三个更衣室(如果打开则关闭,如果关闭则打开);学生S4从更衣室L4开始,改变每四个更衣室;学生S5开始从更衣室L5开始,改变每五个更衣室。依次类推,直到学生S100改变L100。
在所有学生都经过了操作后,哪些更衣室是打开的?编程找出答案。
代码如下:
closets = [False] * 100# 遍历每个学生
for student in range(1, 101):# 遍历每个更衣室for closet_index in range(student - 1, 100, student):# 改变更衣室状态(打开变为关闭,关闭变为打开)closets[closet_index] = not closets[closet_index]# 打印最终结果
for i in range(100):# 只有奇数编号的更衣室是打开的if closets[i]:print(f"更衣室 {i + 1} 是打开的")Demo70 合并两个有序数组
题目描述
给定两个有序递增的数组A和数组B,将其进行合并成一个新的数组C,且保持有序递增,并输出数组C
输入输出描述
第一行输入数组A的长度n,第二行输入n个元素,第三行输入数组B的长度m,第四行输入m个元素
输出数组C的n+m个元素
示例
输入:
5
1 5 16 61 111
4
2 4 5 6
输出:
1 2 4 5 5 6 16 61 111
代码如下:
def collating_sequence(arr_listA, arr_listB):'''合并后两个有序数组arr_listA:传入有序数组Aarr_listB:传入有序数组B返回值:返回合并后的有序数组arr_new'''arr_new = []while len(arr_listA) > 0 and len(arr_listB):if arr_listA[0] < arr_listB[0]:arr_new.append(arr_listA[0])del arr_listA[0]else:arr_new.append(arr_listB[0])del arr_listB[0]while len(arr_listA) > 0:arr_new.append(arr_listA[0])del arr_listA[0]while len(arr_listB) > 0:arr_new.append(arr_listB[0])del arr_listB[0]return arr_newif __name__ == '__main__':n = int(input("输入数组A的长度:"))arr_listA = list(map(int, input("请输入n个元素(使用空格隔开):").split(" ")))m = int(input("输入数组B的长度:"))arr_listB = list(map(int, input("请输入m个元素(使用空格隔开):").split(" ")))new_list = collating_sequence(arr_listA, arr_listB)print(new_list)
Demo71 数组划分
题目描述
给定一个数组A,将第一个元素$A_0$作为枢纽,并把数组划分成三个区间,第一个区间所有元素$<A_0$,第二个区间所有元素$==A_0$,第三个区间所有元素$>A_0$
例如数组[5,2,9,3,6,8],划分后的结果为[3,2,5,9,6,8],第一个区间[3,2],第二个区间[5],第三个区间[9,6,8]
结果不唯一,只要保证划分后三个区间的元素特性即可,[2,3,5,9,8,6]、[3,2,5,6,8,9]都可作为上述划分的结果
输入输出描述
第一行输入数组的长度n,第二行输入n个元素
输出划分后的结果
示例
输入:
10
5 1 9 2 5 7 4 5 3 6
输出:
1 2 4 3 5 5 5 9 7 6
代码如下:
n = int(input("请输入数组的长度:"))
arr = list(map(int, input("输入n个数组:").split()))# 将第一个元素作为枢纽
pivot = arr[0]# 划分数组
less_than_pivot = [num for num in arr if num < pivot]
equal_to_pivot = [num for num in arr if num == pivot]
greater_than_pivot = [num for num in arr if num > pivot]# 输出划分后的结果
result = less_than_pivot + equal_to_pivot + greater_than_pivot
print(' '.join(map(str, result)))
这篇关于Python编程题集(第三部容器操作 )的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





