本文主要是介绍TA-Lib学习研究笔记(三)——Volatility Indicator,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
TA-Lib学习研究笔记(三)——Volatility Indicator
波动率指标函数组
Volatility Indicators: [‘ATR’, ‘NATR’, ‘TRANGE’]
1.ATR
Average True Range
函数名:ATR
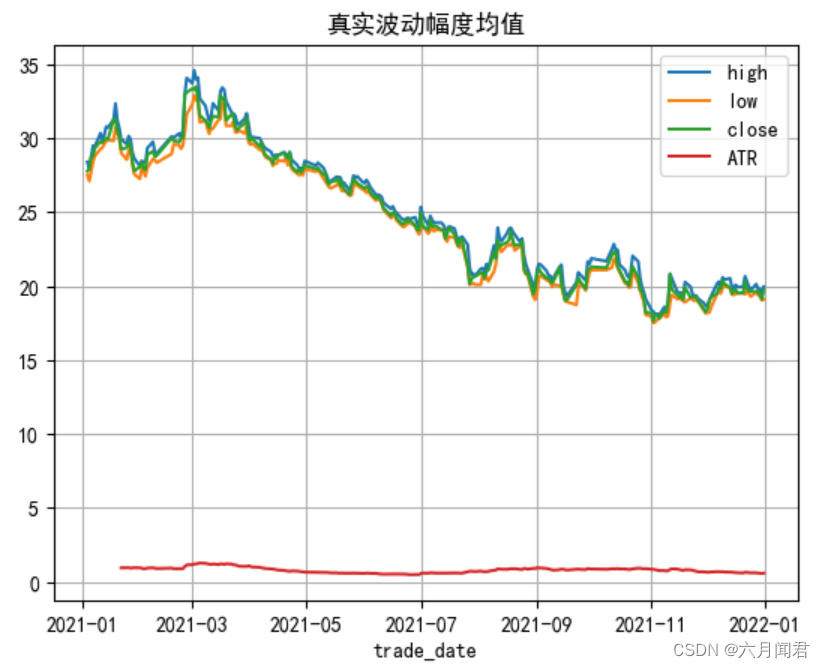
名称:真实波动幅度均值
简介:真实波动幅度均值(ATR)是
以 N 天的指数移动平均数平均後的交易波动幅度。
计算公式:一天的交易幅度只是单纯地 最大值 - 最小值。
而真实波动幅度则包含昨天的收盘价,若其在今天的幅度之外:
真实波动幅度 = max(最大值,昨日收盘价) − min(最小值,昨日收盘价) 真实波动幅度均值便是「真实波动幅度」的 N 日 指数移动平均数。
语法:
real = ATR(high, low, close, timeperiod=14)
df['ATR'] = tlb.ATR(df['high'],df['low'],df['close'], timeperiod=14)# 做图
df[['high','low','close','ATR']].plot(title='真实波动幅度均值')
plt.grid() #启用网格
plt.legend(['high','low','close','ATR']) # 设置图示
plt.show()
2.NATR
函数名:NATR Normalized Average True Range
名称:标准化平均真实范围
简介:标准化平均真实范围(NATR)是计算一个特定时间周期内的正常化平均真实范围,标准化平均真实范围(NATR)是对真实范围的平均值进行标准化处理后的结果。它通过将真实范围除以一个基于时间周期的标准化因子,来消除不同时间周期内价格波动幅度的差异。
语法:
real = NATR(high, low, close, timeperiod=14)
df['NATR'] = tlb.NATR(df['high'],df['low'],df['close'], timeperiod=14)# 做图
df[['high','low','close','NATR']].plot(title='标准化平均真实范围')
plt.grid() #启用网格
plt.legend(['high','low','close','NATR']) # 设置图示
plt.show()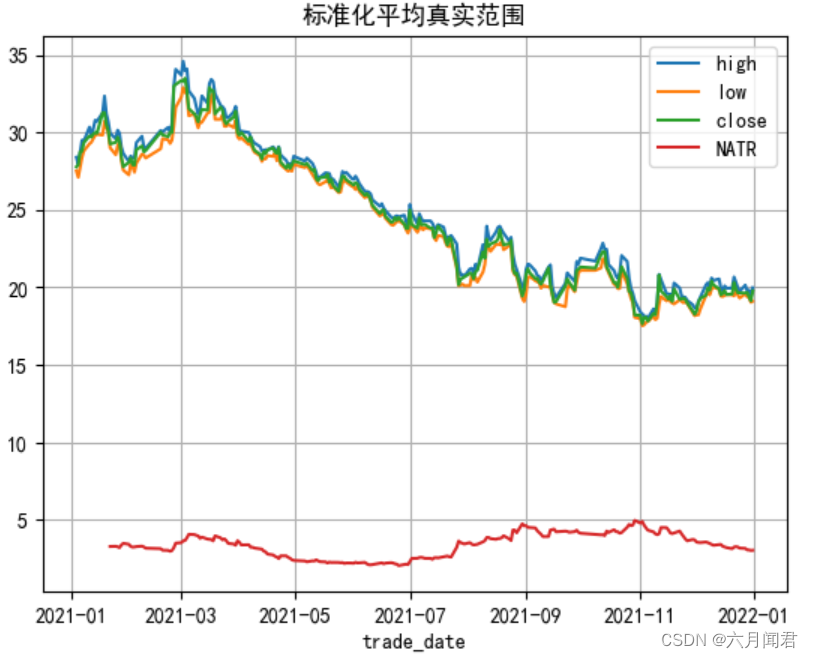
3.TRANGE
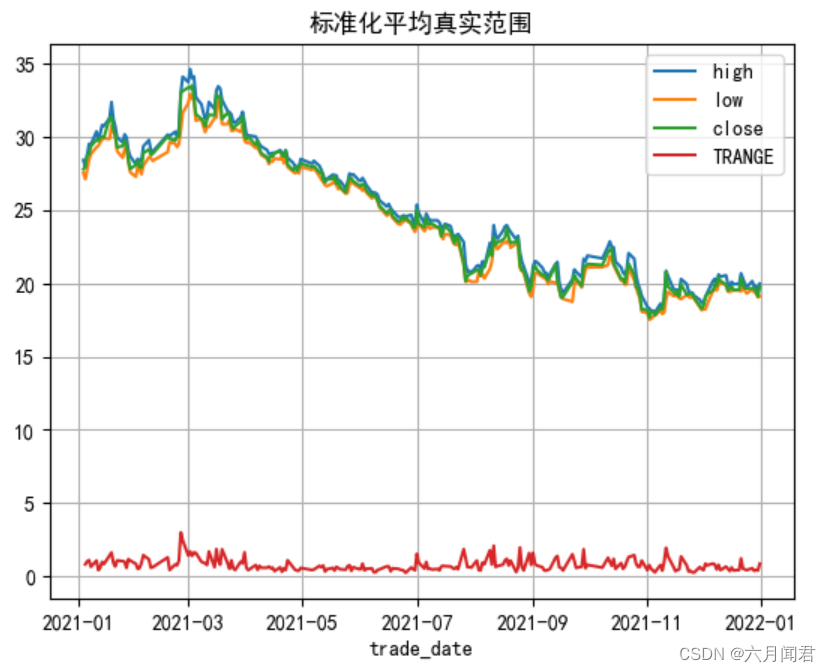
函数名:TRANGE
名称:真正的范围 ,True Range 是用于测量价格波动幅度的指标,它考虑了最高价、最低价和当前收盘价之间的关系。
True Range 的定义如下:
- 如果当前周期的收盘价高于前一周期的最高价,则 True Range 为当前周期的最高价与前一周期的最高价之间的差值。
- 如果当前周期的收盘价低于前一周期的最低价,则 True Range 为当前周期的最低价与前一周期的最低价之间的差值。
- 如果当前周期的收盘价介于前一周期的最高价和最低价之间,则 True Range 为当前周期的最高价与最低价之间的差值。
语法:
real = TRANGE(high, low, close)
df['TRANGE'] = tlb.TRANGE(df['high'],df['low'],df['close'])# 做图
df[['high','low','close','TRANGE']].plot(title='标准化平均真实范围')
plt.grid() #启用网格
plt.legend(['high','low','close','TRANGE']) # 设置图示
plt.show()
这篇关于TA-Lib学习研究笔记(三)——Volatility Indicator的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






