本文主要是介绍机器学习的前世今生:一段波澜壮阔的历史,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
机器学习的前世今生:一段波澜壮阔的历史

Machine Learning
一部气势恢宏的人工智能发展史
AlphaGo的胜利,无人驾驶的成功,模式识别的突破性进展,人工智能的的飞速发展一次又一次地挑动着我们的神经。作为人工智能的核心,机器学习也在人工智能的大步发展中备受瞩目,光辉无限。
如今,机器学习的应用已遍及人工智能的各个分支,如专家系统、自动推理、自然语言理解、模式识别、计算机视觉、智能机器人等领域。
但也许我们不曾想到的事机器学习乃至人工智能的起源,是对人本身的意识、自我、心灵等哲学问题的探索。而在发展的过程中,更是融合了统计学、神经科学、信息论、控制论、计算复杂性理论等学科的知识。

总的来说,机器学习的发展是整个人工智能发展史上颇为重要的一个分支。其中故事一波三折,令人惊讶叹服,颇为荡气回肠。
其中穿插了无数牛人的故事,在下面的介绍中,你将会看到以下神级人物的均有出场,我们顺着ML的进展时间轴娓娓道来

基础奠定的热烈时期
20世纪50年代初到60年代中叶
Hebb于1949年基于神经心理学的学习机制开启机器学习的第一步。此后被称为Hebb学习规则。Hebb学习规则是一个无监督学习规则,这种学习的结果是使网络能够提取训练集的统计特性,从而把输入信息按照它们的相似性程度划分为若干类。这一点与人类观察和认识世界的过程非常吻合,人类观察和认识世界在相当程度上就是在根据事物的统计特征进行分类。
从上面的公式可以看出,权值调整量与输入输出的乘积成正比,显然经常出现的模式将对权向量有较大的影响。在这种情况下,Hebb学习规则需预先定置权饱和值,以防止输入和输出正负始终一致时出现权值无约束增长。
Hebb学习规则与“条件反射”机理一致,并且已经得到了神经细胞学说的证实。比如巴甫洛夫的条件反射实验:每次给狗喂食前都先响铃,时间一长,狗就会将铃声和食物联系起来。以后如果响铃但是不给食物,狗也会流口水。
1950年,阿兰·图灵创造了图灵测试来判定计算机是否智能。图灵测试认为,如果一台机器能够与人类展开对话(通过电传设备)而不能被辨别出其机器身份,那么称这台机器具有智能。这一简化使得图灵能够令人信服地说明“思考的机器”是可能的。

2014年6月8日,一台计算机(计算机尤金·古斯特曼是一个聊天机器人,一个电脑程序)成功让人类相信它是一个13岁的男孩,成为有史以来首台通过图灵测试的计算机。这被认为是人工智能发展的一个里程碑事件。
1952,IBM科学家亚瑟·塞缪尔开发了一个跳棋程序。该程序能够通过观察当前位置,并学习一个隐含的模型,从而为后续动作提供更好的指导。塞缪尔发现,伴随着该游戏程序运行时间的增加,其可以实现越来越好的后续指导。
通过这个程序,塞缪尔驳倒了普罗维登斯提出的机器无法超越人类,像人类一样写代码和学习的模式。他创造了“机器学习”,并将它定义为“可以提供计算机能力而无需显式编程的研究领域”。
1957年,罗森·布拉特基于神经感知科学背景提出了第二模型,非常的类似于今天的机器学习模型。这在当时是一个非常令人兴奋的发现,它比Hebb的想法更适用。基于这个模型罗森·布拉特设计出了第一个计算机神经网络——感知机(the perceptron),它模拟了人脑的运作方式。
3年后,维德罗首次使用Delta学习规则用于感知器的训练步骤。这种方法后来被称为最小二乘方法。这两者的结合创造了一个良好的线性分类器。

1967年,最近邻算法(The nearest neighbor algorithm)出现,由此计算机可以进行简单的模式识别。kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。

kNN的优点在于易于理解和实现,无需估计参数,无需训练,适合对稀有事件进行分类,特别适合于多分类问题(multi-modal,对象具有多个类别标签), 甚至比SVM的表现要好。
Han等人于2002年尝试利用贪心法,针对文件分类实做可调整权重的k最近邻居法WAkNN (weighted adjusted k nearest neighbor),以促进分类效果;而Li等人于2004年提出由于不同分类的文件本身有数量上有差异,因此也应该依照训练集合中各种分类的文件数量,选取不同数目的最近邻居,来参与分类。
1969年马文·明斯基将感知器兴奋推到最高顶峰。他提出了著名的XOR问题和感知器数据线性不可分的情形。
明斯基还把人工智能技术和机器人技术结合起来,开发出了世界上最早的能够模拟人活动的机器人Robot C,使机器人技术跃上了一个新台阶。明斯基的另一个大举措是创建了著名的“思维机公司”(Thinking Machines,Inc.),开发具有智能的计算机。
此后,神经网络的研究将处于休眠状态,直到上世纪80年代。尽管BP神经的想法由林纳因马在1970年提出,并将其称为“自动分化反向模式”,但是并未引起足够的关注。
停滞不前的冷静时期
20世纪60年代中叶到70年代末
从60年代中到70年代末,机器学习的发展步伐几乎处于停滞状态。虽然这个时期温斯顿(Winston)的结构学习系统和海斯·罗思(Hayes Roth)等的基于逻辑的归纳学习系统取得较大的进展,但只能学习单一概念,而且未能投入实际应用。此外,神经网络学习机因理论缺陷未能达到预期效果而转入低潮。
这个时期的研究目标是模拟人类的概念学习过程,并采用逻辑结构或图结构 作为机器内部描述。机器能够采用符号来描述概念(符号概念获取),并提出关于学习概念的各种假设。
事实上,这个时期整个AI领域都遭遇了瓶颈。当时的计算机有限的内存和处理速度不足以解决任何实际的AI问题。要求程序对这个世界具有儿童水平的认识,研究者们很快发现这个要求太高了:1970年没人能够做出如此巨大的数据库,也没人知道一个程序怎样才能学到如此丰富的信息。
重拾希望的复兴时期
20世纪70年代末到80年代中叶
从70年代末开始,人们从学习单个概念扩展到学习多个概念,探索不同的学习 策略和各种学习方法。这个时期,机器学习在大量的时间应用中回到人们的视线,又慢慢复苏。
1980年,在美国的卡内基梅隆大学(CMU)召开了第一届机器学习国际研讨会,标志着机器学习研究已在全世界兴起。此后,机器归纳学习进入应用。
经过一些挫折后,多层感知器(MLP)由伟博斯在1981年的神经网络反向传播(BP)算法中具体提出。当然BP仍然是今天神经网络架构的关键因素。有了这些新思想,神经网络的研究又加快了。
1985 -1986神经网络研究人员(鲁梅尔哈特,辛顿,威廉姆斯-赫,尼尔森)先后提出了MLP与BP训练相结合的理念。
一个非常著名的ML算法由昆兰在1986年提出,我们称之为决策树算法,更准确的说是ID3算法。这是另一个主流机器学习的火花点。此外,与黑盒神经网络模型截然不同的是,决策树ID3算法也被作为一个软件,通过使用简单的规则和清晰的参考可以找到更多的现实生活中的使用情况。
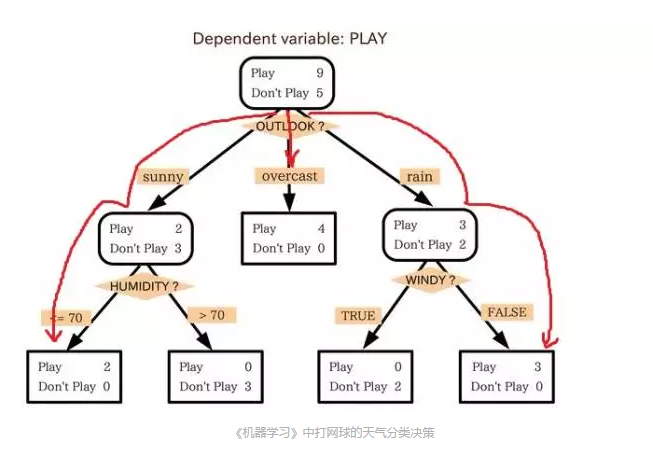
决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。树中每个节点表示某个对象,而每个分叉路径则代表的某个可能的属性值,而每个叶结点则对应从根节点到该叶节点所经历的路径所表示的对象的值。决策树仅有单一输出,若欲有复数输出,可以建立独立的决策树以处理不同输出。数据挖掘中决策树是一种经常要用到的技术,可以用于分析数据,同样也可以用来作预测。
现代机器学习的成型时期
20世纪90年初到21世纪初
1990年,Schapire最先构造出一种多项式级的算法 ,对该问题做了肯定的证明 ,这就是最初的Boosting算法。一年后 ,Freund提出了一种效率更高的Boosting算法。但是,这两种算法存在共同的实践上的缺陷 ,那就是都要求事先知道弱学习算法学习正确的下限。

1995年 , Freund和schapire改进了Boosting算法 ,提出了 AdaBoost (Adap tive Boosting)算法,该算法效率和 Freund于 1991年提出的 Boosting算法几乎相同 ,但不需要任何关于弱学习器的先验知识 ,因而更容易应用到实际问题当中。
Boosting方法是一种用来提高弱分类算法准确度的方法,这种方法通过构造一个预测函数系列,然后以一定的方式将他们组合成一个预测函数。他是一种框架算法,主要是通过对样本集的操作获得样本子集,然后用弱分类算法在样本子集上训练生成一系列的基分类器。
同年,机器学习领域中一个最重要的突破,支持向量(support vector machines, SVM ),由瓦普尼克和科尔特斯在大量理论和实证的条件下年提出。从此将机器学习社区分为神经网络社区和支持向量机社区。
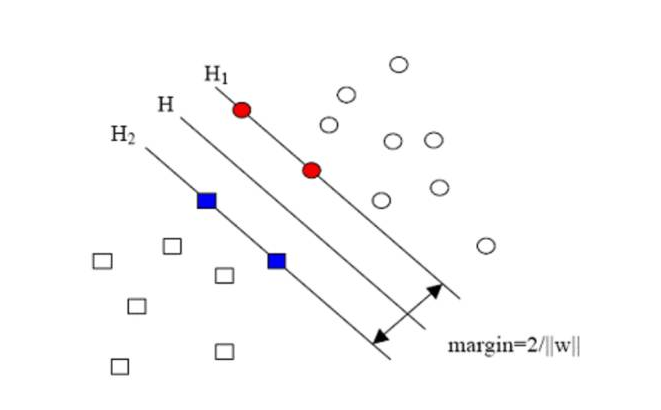
然而两个社区之间的竞争并不那么容易,神经网络要落后SVM核化后的版本将近2000s 。支持向量机在以前许多神经网络模型不能解决的任务中取得了良好的效果。此外,支持向量机能够利用所有的先验知识做凸优化选择,产生准确的理论和核模型。因此,它可以对不同的学科产生大的推动,产生非常高效的理论和实践改善。
支撑向量机 , Boosting,最大熵方法(比如logistic regression, LR)等。这些模型的结构基本上可以看成带有一层隐层节点(如SVM, Boosting),或没有隐层节点(如LR)。这些模型在无论是理论分析还是应用都获得了巨大的成功。
另一个集成决策树模型由布雷曼博士在2001年提出,它是由一个随机子集的实例组成,并且每个节点都是从一系列随机子集中选择。由于它的这个性质,被称为随机森林(RF),随机森林也在理论和经验上证明了对过拟合的抵抗性。
甚至连AdaBoost算法在数据过拟合和离群实例中都表现出了弱点,而随机森林是针对这些警告更稳健的模型。随机森林在许多不同的任务,像DataCastle、Kaggle等比赛等都表现出了成功的一面。

大放光芒的蓬勃发展时期
21世纪初至今
在机器学习发展分为两个部分,浅层学习(Shallow Learning)和深度学习(Deep Learning)。浅层学习起源上世纪20年代人工神经网络的反向传播算法(Back-propagation)的发明,使得基于统计的机器学习算法大行其道,虽然这时候的人工神经网络算法也被称为多层感知机(Multiple layer Perception),但由于多层网络训练困难,通常都是只有一层隐含层的浅层模型。
神经网络研究领域领军者Hinton在2006年提出了神经网络Deep Learning算法,使神经网络的能力大大提高,向支持向量机发出挑战。 2006年,机器学习领域的泰斗Hinton和他的学生Salakhutdinov在顶尖学术刊物《Scince》上发表了一篇文章,开启了深度学习在学术界和工业界的浪潮。
这篇文章有两个主要的讯息:1)很多隐层的人工神经网络具有优异的特征学习能力,学习得到的特征对数据有更本质的刻划,从而有利于可视化或分类;2)深度神经网络在训练上的难度,可以通过“逐层初始化”( layer-wise pre-training)来有效克服,在这篇文章中,逐层初始化是通过无监督学习实现的。
Hinton的学生Yann LeCun的LeNets深度学习网络可以被广泛应用在全球的ATM机和银行之中。同时,Yann LeCun和吴恩达等认为卷积神经网络允许人工神经网络能够快速训练,因为其所占用的内存非常小,无须在图像上的每一个位置上都单独存储滤镜,因此非常适合构建可扩展的深度网络,卷积神经网络因此非常适合识别模型。
2015年,为纪念人工智能概念提出60周年,LeCun、Bengio和Hinton推出了深度学习的联合综述。
深度学习可以让那些拥有多个处理层的计算模型来学习具有多层次抽象的数据的表示。这些方法在许多方面都带来了显著的改善,包括最先进的语音识别、视觉对象识别、对象检测和许多其它领域,例如药物发现和基因组学等。深度学习能够发现大数据中的复杂结构。它是利用BP算法来完成这个发现过程的。BP算法能够指导机器如何从前一层获取误差而改变本层的内部参数,这些内部参数可以用于计算表示。深度卷积网络在处理图像、视频、语音和音频方面带来了突破,而递归网络在处理序列数据,比如文本和语音方面表现出了闪亮的一面。
当前统计学习领域最热门方法主要有deep learning和SVM(supportvector machine),它们是统计学习的代表方法。可以认为神经网络与支持向量机都源自于感知机。
神经网络与支持向量机一直处于“竞争”关系。SVM应用核函数的展开定理,无需知道非线性映射的显式表达式;由于是在高维特征空间中建立线性学习机,所以与线性模型相比,不但几乎不增加计算的复杂性,而且在某种程度上避免了“维数灾难”。而早先的神经网络算法比较容易过训练,大量的经验参数需要设置;训练速度比较慢,在层次比较少(小于等于3)的情况下效果并不比其它方法更优。
神经网络模型貌似能够实现更加艰难的任务,如目标识别、语音识别、自然语言处理等。但是,应该注意的是,这绝对不意味着其他机器学习方法的终结。尽管深度学习的成功案例迅速增长,但是对这些模型的训练成本是相当高的,调整外部参数也是很麻烦。同时,SVM的简单性促使其仍然最为广泛使用的机器学习方式。

人工智能机器学习是诞生于20世纪中叶的一门年轻的学科,它对人类的生产、生活方式产生了重大的影响,也引发了激烈的哲学争论。但总的来说,机器学习的发展与其他一般事物的发展并无太大区别,同样可以用哲学的发展的眼光来看待。
机器学习的发展并不是一帆风顺的,也经历了螺旋式上升的过程,成就与坎坷并存。其中大量的研究学者的成果才有了今天人工智能的空前繁荣,是量变到质变的过程,也是内因和外因的共同结果。
回望过去,我们都会被这一段波澜壮阔的历史所折服吧。
这篇关于机器学习的前世今生:一段波澜壮阔的历史的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









