本文主要是介绍为什么说特征是机器学习系统的原材料?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
特征是机器学习系统的原材料,对最终模型的影响是毋庸置疑的。如果数据被很好的表达成了特征,通常线性模型就能达到满意的精度。那对于特征,我们需要考虑什么呢?
首先要考虑的是,学习算法在一个什么粒度上的特征表示,才有能发挥作用?
特征表示的粒度
就一个图片来说,像素级的特征根本没有价值。
例如下面的摩托车,从像素级别,根本得不到任何信息,其无法进行摩托车和非摩托车的区分。

而如果特征是一个具有结构性(或者说有含义)的时候,比如是否具有车把手(handle),是否具有车轮(wheel),就很容易把摩托车和非摩托车区分,学习算法才能发挥作用。
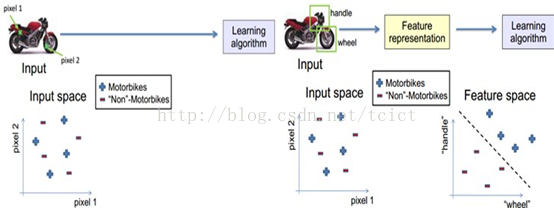
既然像素级的特征表示方法没有作用,那怎样的表示才有用呢?
1995 年前后,Bruno Olshausen和 David Field 两位学者任职 Cornell University,他们试图同时用生理学和计算机的手段,双管齐下,研究视觉问题。
他们收集了很多黑白风景照片,从这些照片中,提取出400个小碎片,每个照片碎片的尺寸均为 16x16 像素,不妨把这400个碎片标记为 S[i], i = 0,.. 399。
接下来从这些黑白风景照片中,随机提取另一个碎片,尺寸也是 16x16 像素,不妨把这个碎片标记为 T。

他们提出的问题是,如何从这400个碎片中,选取一组碎片,S[k], 通过叠加的办法,合成出一个新的碎片,而这个新的碎片,应当与随机选择的目标碎片 T,尽可能相似,同时,S[k] 的数量尽可能少。用数学的语言来描述,就是:
Sum_k (a[k] * S[k]) --> T, 其中 a[k] 是在叠加碎片 S[k] 时的权重系数。
Sift处理数据
为解决这个问题,Bruno Olshausen和 David Field 发明了一个算法,稀疏编码(Sparse Coding)。
稀疏编码是一个重复迭代的过程,每次迭代分两步:
1)选择一组 S[k],然后调整 a[k],使得Sum_k (a[k] * S[k]) 最接近 T。
2)固定住 a[k],在 400 个碎片中,选择其它更合适的碎片S’[k],替代原先的 S[k],使得Sum_k (a[k] * S’[k]) 最接近 T。
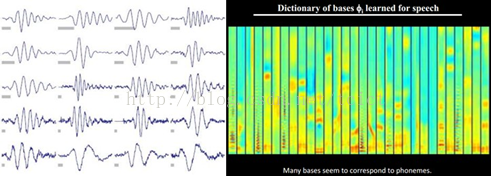
经过几次迭代后,最佳的 S[k] 组合,被遴选出来了。令人惊奇的是,被选中的 S[k],基本上都是照片上不同物体的边缘线,这些线段形状相似,区别在于方向。
Bruno Olshausen和 David Field 的算法结果,与 David Hubel 和Torsten Wiesel 的生理发现,不谋而合!
也就是说,复杂图形,往往由一些基本结构组成。比如下图:一个图可以通过用64种正交的edges(可以理解成正交的基本结构)来线性表示。比如样例的x可以用1-64个edges中的三个按照0.8,0.3,0.5的权重调和而成。而其他基本edge没有贡献,因此均为0 。

需要有多少个特征?
我们知道需要层次的特征构建,由浅入深,但每一层该有多少个特征呢?
任何一种方法,特征越多,给出的参考信息就越多,准确性会得到提升。但特征多意味着计算复杂,探索的空间大,可以用来训练的数据在每个特征上就会稀疏,都会带来各种问题,并不一定特征越多越好。

为什么会有Deep learning(让机器自动学习良好的特征,而免去人工选取过程。还有参考人的分层视觉处理系统),我们得到一个结论就是Deep learning需要多层来获得更抽象的特征表达。
这篇关于为什么说特征是机器学习系统的原材料?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





