本文主要是介绍SQL Server 索引查找Index Seek 索引扫描 Index Scan与索引存储原理详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
SQL Server索引查找 索引扫描 B-Tree与索引存储原理
索引查找的演示案例
聚集索引查找
索引查找(index seek)即查询条件内命中索引,直接接用主键匹配时触发聚集索引查找(Index Seek)
SELECT * FROM EMPLOYEES
WHERE id IN(10,100,1000,10000,100000,1000000)
SELECT * FROM EMPLOYEES WHERE id = 57864
SELECT * FROM EMPLOYEES WHERE id >10000 AND id < 1000000
以第一个查询为例,其执行计划见下:

可见用index seek时读取的行数和所有执行的实际行数都是6,命中率很高。
非聚集索引查找
命中非聚集索引的条件,再通过key lookup找到其它字段。详见“聚集索引的演示案例”里的“非聚集索引下WHERE查询”章节。
注:详见:
SQL Server 聚集索引 clustered index 非聚集索引Nonclustered Indexes键查找查找Key Lookup执行计划过程详解_数据科学汇集-CSDN博客
--在NAME字段上建立非聚集索引。
CREATE NONCLUSTERED INDEX IX_EMP_NAME ON EMPLOYEES(NAME)
-- 再次执行WHERE查询并含实际执行计划。
SELECT * FROM EMPLOYEES
WHERE NAME = 'ABC 874000'
聚集索引应用场景概述
以下示例查询条件会用到索引查找:
id = 12000
score < 89
name = ’John’
name LIKE ’John%’
索引扫描的演示案例
索引扫描
详见“聚集索引的演示案例”里的“无索引下WHERE查询”章节。
SELECT * FROM EMPLOYEES
WHERE NAME = 'ABC 874000'
这里因为没有索引,只能通过扫描聚集索引以索引扫描的方式获得数据。

索引扫描应用场景概述
以下示例查询条件会用到索引扫描:
ABS(id) = 12000
score+10< 89
name LIKE ’%john’
UPPER(name) = ’JOHN’
覆盖索引的演示案例
建立索引时指定以include方式。
CREATE NONCLUSTERED INDEX IX_EMP_NAME2 ON EMPLOYEES(NAME) INCLUDE(email,dept)
SELECT * FROM EMPLOYEES
WHERE NAME = 'ABC 874000'
数据存储介绍
物理存储方式
SQL Server里的数据在逻辑上以行列方式存储,在物理上以数据页的形式存储。一个数据页是SQL Server存储数据的基本单位,它有8k大小。当我们往表里插入时,数据会被存放在一系列的8k的数据页里。
数据实际存储示意
一系列的数据页以树的形式组织起来,具体见下图示意。这个树叫做B-Tree,索引B-Tree或者聚集索引结构。
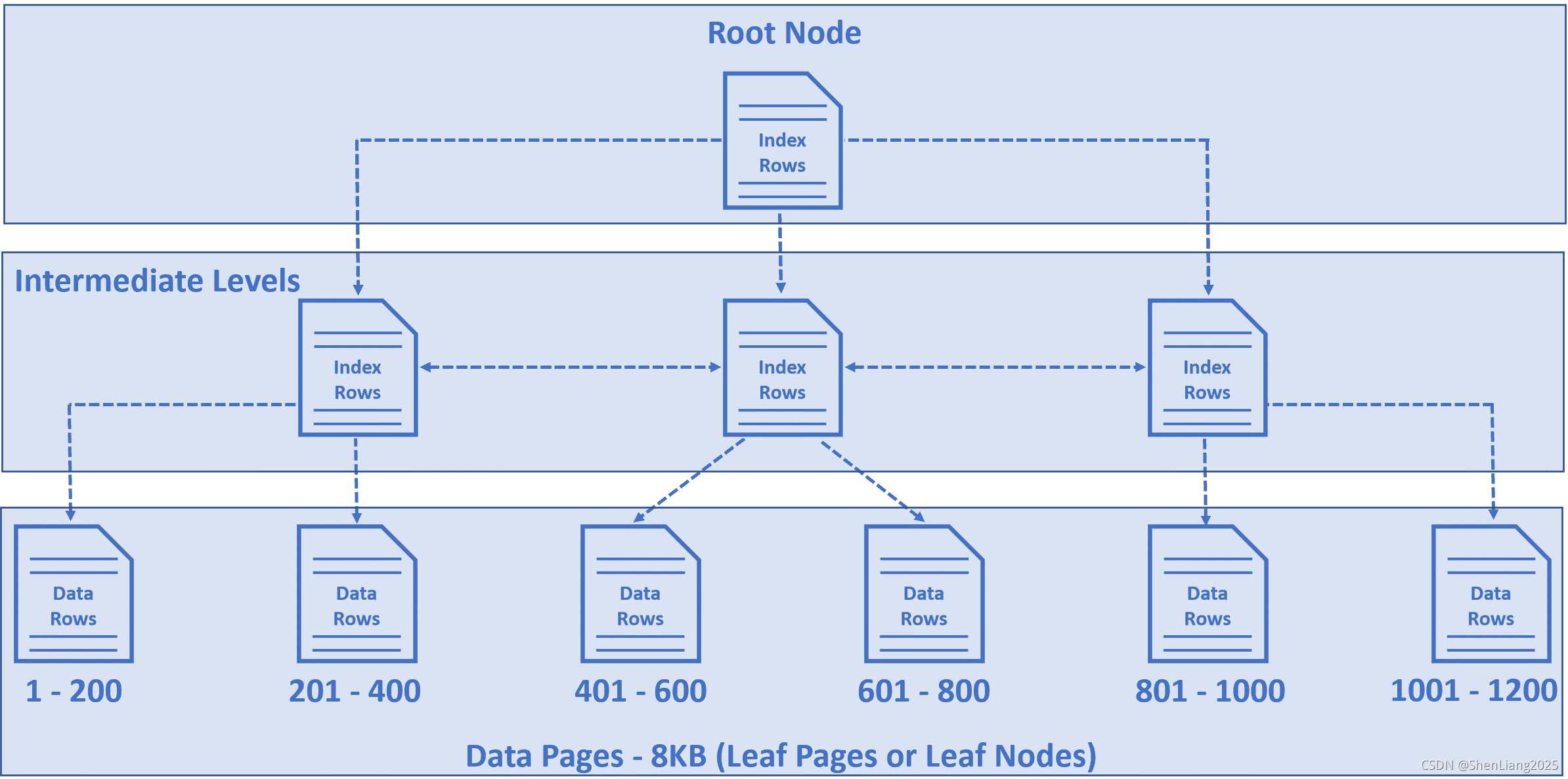
上图B-tree里最底端的节点叫做数据页或者树的叶子节点,这些叶子节点里存放了表的数据。
数据页默认大小是8k,也即是说数据页能存放表的几行数据依赖于行数据的大小。
从示意图里可以看到第一个数据页存放1-200行数据,而第二页存放201-400依次类推。
B-tree的顶上的节点叫做根节点。
跟节点和叶子节点直接的叫做中间节点,根节点和中间节点存放索引行。
在每个索引行里都包含一个主键(如这里的Employeeid)、一个指向中间节点和叶子节点的指针。
B-Tree遍历示意
以通过员工号查询员工信息为例,我看下B-tree是怎么工作的。语句见下:
select * from Employees where EmployeeId = 1189
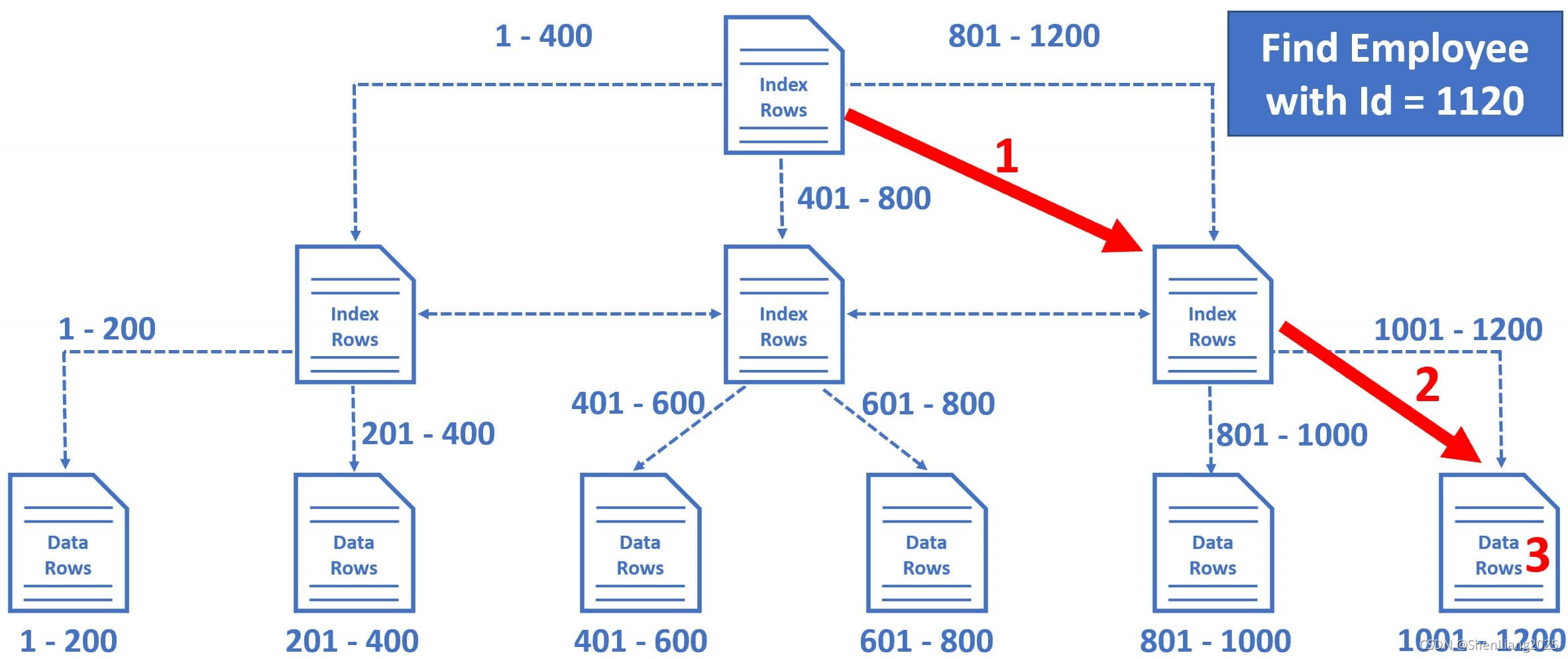
1 数据库引擎首先从数据的根节点开始遍历,因为我们的查询条件是Employeeid=1189,它属于索引行801-1200所在的范畴。
2 然后再从1里的子节点锁定Employeeid走右边的分支即属1001-1200的范畴。
3 最后从叶子节点对应的1001-1200的数据页里找到数据。
索引维护介绍
索引碎片
当索引中页面的逻辑顺序与数据文件中的物理顺序不匹配时,就会发生碎片。因为索引碎片会影响查询的性能,所以有时需要做索引重建。
1 索引碎片仅影响索引扫描和范围扫描的效率,对索引查找没有任何影响。
2 查询优化器不受碎片,不论是高碎片还是低碎片生成的计划都是相同的。
3 可以通过sys.dm_db_index_physical_stats 动态函数查看索引碎片情况。
SELECT a.object_id, a.index_id, name, avg_fragmentation_in_percent, fragment_count,
avg_fragment_size_in_pages
FROM sys.dm_db_index_physical_stats (DB_ID('ShenLiang2025'),
OBJECT_ID('EMPLOYEES'), NULL, NULL, NULL) AS a
JOIN sys.indexes AS b ON a.object_id = b.object_id AND a.index_id = b.index_id

索引重建
索引重建见如下语句:
--1重建指定索引
ALTER INDEX IX_EMP_NAME ON EMPLOYEES REBUILD;--2 重建表里所有索引
ALTER INDEX ALL ON dbo.EMPLOYEES REBUILD
这篇关于SQL Server 索引查找Index Seek 索引扫描 Index Scan与索引存储原理详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






