本文主要是介绍arm linux spin_lock 原理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
aarch32 linux4.9
spin lock的目的是为了让cpu在等待资源的时候自旋在那里而不是去睡眠进行上下文切换,所以spin_lock中做的事情不能太多要不然反而会降低系统性能,事情的耗时数量级应该是数个tick,spi_lock相关的常用的api如下:
static __always_inline void spin_lock(spinlock_t *lock)static __always_inline void spin_lock_bh(spinlock_t *lock)static __always_inline void spin_lock_irq(spinlock_t *lock)spin_lock_irqsave(lock, flags)static __always_inline void spin_unlock(spinlock_t *lock);static __always_inline void spin_unlock_bh(spinlock_t *lock)static __always_inline void spin_unlock_irq(spinlock_t *lock)static __always_inline void spin_unlock_irqrestore(spinlock_t *lock, unsigned long flags)
spin_lock spin_unlock //关抢占
spin_lock_bh spin_unlock_bh //bh意指中断bottom half
spin_lock_irq spin_unlock_irq //中断上下文中的spin_lock,先关抢占然后会把当前cpu的中断disable unlock的时候打开
spin_lock_irqsave spin_unlock_irqrestore //中断上下文中使用,先关抢占然后会把当前cpu的cpsr的中断状态保存下来然后restore的时候恢复
以一个复杂的smp下的竞态为例说明下使用方式
每个cpu的多个task与irq都需要访问某个资源的时候,形成的核内和核间的竞争,spin_lock的使用方式如下图
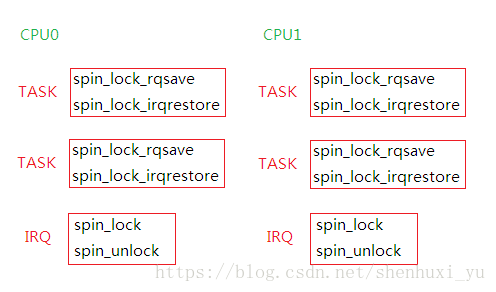
以spin_lock_irqsave为例说明下spin_lock是怎样实现自旋的,自旋到底是个什么状态
#define spin_lock_irqsave(lock, flags) \
do { \raw_spin_lock_irqsave(spinlock_check(lock), flags); \
} while (0)#define raw_spin_lock_irqsave(lock, flags) \do { \typecheck(unsigned long, flags); \flags = _raw_spin_lock_irqsave(lock); \} while (0)unsigned long __lockfunc _raw_spin_lock_irqsave(raw_spinlock_t *lock)
{return __raw_spin_lock_irqsave(lock);
}static inline unsigned long __raw_spin_lock_irqsave(raw_spinlock_t *lock)
{unsigned long flags;local_irq_save(flags);preempt_disable();spin_acquire(&lock->dep_map, 0, 0, _RET_IP_);/** On lockdep we dont want the hand-coded irq-enable of* do_raw_spin_lock_flags() code, because lockdep assumes* that interrupts are not re-enabled during lock-acquire:*/
#ifdef CONFIG_LOCKDEPLOCK_CONTENDED(lock, do_raw_spin_trylock, do_raw_spin_lock);
#elsedo_raw_spin_lock_flags(lock, &flags);
#endifreturn flags;
}static inline void
do_raw_spin_lock_flags(raw_spinlock_t *lock, unsigned long *flags) __acquires(lock)
{__acquire(lock);arch_spin_lock_flags(&lock->raw_lock, *flags);
}#define arch_spin_lock_flags(lock, flags) arch_spin_lock(lock)static inline void arch_spin_lock(arch_spinlock_t *lock)
{unsigned long tmp;u32 newval;arch_spinlock_t lockval;prefetchw(&lock->slock);__asm__ __volatile__(
"1: ldrex %0, [%3]\n"
" add %1, %0, %4\n"
" strex %2, %1, [%3]\n"
" teq %2, #0\n"
" bne 1b": "=&r" (lockval), "=&r" (newval), "=&r" (tmp): "r" (&lock->slock), "I" (1 << TICKET_SHIFT): "cc");while (lockval.tickets.next != lockval.tickets.owner) {wfe();lockval.tickets.owner = ACCESS_ONCE(lock->tickets.owner);}smp_mb();//清流水线 memory barrir
}最终调用到的arch_spi_lock函数,ldrex和strex是arm 支持的原子操作指令,关于这两条命令参考博客https://blog.csdn.net/roland_sun/article/details/47670099
#define TICKET_SHIFT 16
typedef struct {
union {
u32 slock;
struct __raw_tickets { u16 owner; u16 next; } tickets;
};
} arch_spinlock_t;
ldrex 取lock的成员的值暂存到lock_val
add new_val= lock_val + 0x10000 lock的next++
strex new_val 到lock成员,操作返回值tmp
如果返回值是0 跳到1b继续循环执行
因为ldrex声明了这段区域后只有核内,核间的其他最先更新strex 更新该内存的task才会继续执行下去,这组原子操作的目的是保证当前只有一个cpu 能获取,在cpu和内存之间搭了个独木桥。 spin_unlock的时候会把 owner++; 所以会while到next 与owner相等,spin_lock初始化的时候owner和next都是0,表示unlocked。当第一个个thread调用spin_lock来申请lock的时候,owner和next相等,表示unlocked,这时候该thread持有该spin lock,并且执行next++,也就是将next设定为1。没有其他thread来竞争就调用spin_unlock执行owner++,也就是将owner设定为1。next++之后等于2,后面的task想要持有锁的话分配当然也会执行next++,接着next值不断的增加,如果没有unlock则owner的值不动,直到调用spin_unlock owner++之后等于2满足条件才会截接着spin_lock继续执行下去
这篇关于arm linux spin_lock 原理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







