本文主要是介绍java线程学习(八):多线程高级使用之线程池的使用(非常推荐,涉及:ThreadPoolExecutor,Executors,ThreadPoolExecutor,ScheduledThreadP),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
- 前言: 通过前面几篇文章的学习,对多线程的知识了解了很多,同时也明白,其实学习不仅仅要看书,看文章,还要自己动手去敲demo,顺便写点文章收获更多。当然多线程如果仅仅是用前面几篇的知识的话,那未免也太肤浅了,毕竟,线程如果频繁开启和关闭的话,对系统资源的消耗那是相当大的。所以,从本篇文章起,我们开启对线程的更高一级的学习,那就是使用线程池去管理线程的使用。
线程池的学习,主要还是学习JDK提供的一套Executor框架,该框架的核心成员关系图为:
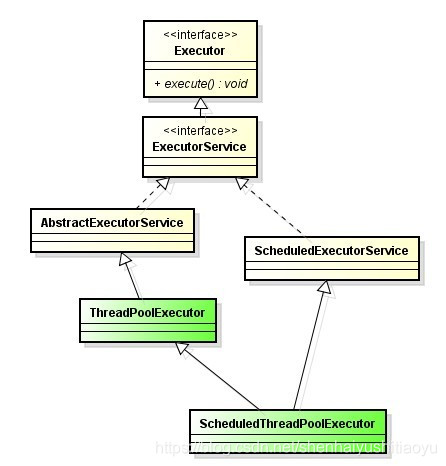
可以看到,ThreadPoolExecutor类和ScheduledThreadPoolExecutor类是最核心的两个成员,其中ThreadPoolExecutor是线程池创建与使用最关键的类,ScheduledThreadPoolExecutor是针对计划任务的时候使用是比较方便的。
1.Executors的讲解
与线程池的创建有关的,还有Executors工具类,该类扮演者线程池工厂的角色,主要用来创建各种线程池,并返回ThreadPoolExecutor对象,如:
1.1 常用方法
public static ExecutorService newFixedThreadPool(int nThread);
解释:该方法返回一个固定线程数量的线程池。该线程池中的线程数量固定不变,当有任务提交时,若线程池中有空闲的线程,那么就立即执行,如果没有,则新的任务会被暂存在一个队列中,带有线程空闲时,便会处理在这个队列中的任务。
public static ExecutorService newSingleThreadExecutor();
解释: 从single看得出,该方法就是上一个方法的特例,返回一个只有一个线程的线程池。若多余一个任务呗提交到该线程池,任务会被保存在一个队列当中,待线程空闲,按先入先出的顺序执行队列中的任务。
public static ExecutorService newCachedThreadPool();
解释:该方法会返回一个可根据实际情况调整线程数量的线程池。线程池的线程数量不确定,但若有空闲线程可以复用,则会有限使用可复用的线程,如果所有线程均在工作,又有新的任务提交,则会创建新的线程处理任务,所有的线程在当前任务完毕后,将返回线程池进行复用。(可以看得出,如果并发量高的话,这家伙会把系统资源全都吃掉的。。。)
public static ScheduledExecutorService newSingleThreadScheduledExecutor();
解释:类似地,从‘Single’ 就可以看出该方法返回一个ScheduledExecutorService对象.线程池大小为1.ScheduledExecutorService接口在ScheduledExecutorService之上扩展了在给定时间执行某任务的功能(后续给出demo就很容易理解了),如在某个固定的延迟之后执行,或者周期性执行某个任务。
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize);
解释:该方法也返回一个ScheduledExecutorService对象,但可以指定该线程池的线程数量。
1.2例子
newFixedThreadPool():
创建一个包含5个线程的线程池,然后创建10个线程放入线程池中,看效果:
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;public class Pool_demo implements Runnable{SimpleDateFormat format=new SimpleDateFormat("HH:mm:ss");@Overridepublic void run() {System.out.println("执行时间:"+format.format(new Date())+ " 线程ID: "+Thread.currentThread().getId());try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}}public static void main(String[] args) {Pool_demo demo=new Pool_demo();ExecutorService es = Executors.newFixedThreadPool(5);//创建5个线程的线程池for (int i = 0; i < 10; i++) {es.execute(demo);//执行}}
}
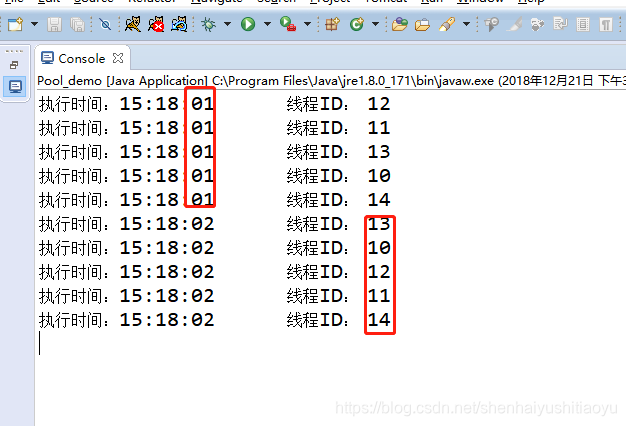
运行后输出:
可以看到,线程池会分每组5个同时(从时间上看)去处理,当然如果只有三个线程,线程池也会去处理的,而且,通过线程id可以看得出,5个线程处理完后,剩下的5个线程是复用的,不是另外创建的,这也就说明,使用线程池实际上是可以减少系统资源的消耗的。
扩展: 可以使用这个来弄个高并发请求测试。。。比如前段时间学的rabbitMQ,可以同时发送上百个请求去测MQ的队列,看下是否能撑得住。
newScheduledThreadPool() 测试:
上面说过,该方法会返回ScheduledExecutorService对象,而ScheduledExecutorService接口主要包含这些方法:
ScheduledFuture<?> schedule(Runnable var1, long var2, TimeUnit var4);
ScheduledFuture<?> scheduleAtFixedRate(Runnable var1, long var2, long var4, TimeUnit var6);
ScheduledFuture<?> scheduleWithFixedDelay(Runnable var1, long var2, long var4, TimeUnit var6);
//var2:表示该线程收到"任务"后多久执行,var4表示一个周期。
scheduleAtFixedRate()与scheduleWithFixedDelay()方法都是由对任务进行周期性的调度,但两者还是有区别的,前者是以上一个任务开始时间为起点,调度下一个任务。而后者是在上一个任务结束后,在经过一个周期执行下一个任务。
写个例子就明白了:
public static void main(String[] args) {ScheduledExecutorService scheduledPool = Executors.newScheduledThreadPool(10);scheduledPool.scheduleAtFixedRate(()->{try {Thread.sleep(1000);System.out.println("执行时间:"+new SimpleDateFormat("HH:mm:ss").format(new Date()));} catch (InterruptedException e) {e.printStackTrace();}}, 0, 2, TimeUnit.SECONDS);}
输出:
| 执行时间:16:52:09 执行时间:16:52:11 执行时间:16:52:13 执行时间:16:52:15 |
可以看到是每两秒执行一次。如果代码块中的Thread.sleep(1000);改成Thread.sleep(5000); 5秒一次,大于周期2秒,看下结果:
| 执行时间:17:14:57 执行时间:17:15:02 执行时间:17:15:07 执行时间:17:15:12 |
而对于scheduleWithFixedDelay:
public class Pool_schedule_demo {public static void main(String[] args) {ScheduledExecutorService scheduledPool = Executors.newScheduledThreadPool(10);scheduledPool.scheduleWithFixedDelay(()->{try {Thread.sleep(1000);System.out.println("执行时间:"+new SimpleDateFormat("HH:mm:ss").format(new Date()));} catch (InterruptedException e) {e.printStackTrace();}}, 0, 2, TimeUnit.SECONDS);}
}
输出:
| 执行时间:17:17:07 执行时间:17:17:10 执行时间:17:17:13 执行时间:17:17:16 执行时间:17:17:19 执行时间:17:17:22 |
| 执行时间:17:18:52 执行时间:17:18:59 执行时间:17:19:06 执行时间:17:19:13 执行时间:17:19:20 执行时间:17:19:27 执行时间:17:19:34 执行时间:17:19:41 |
值得注意的是: 以上的任务调度,如果运行时出现异常,会中断后续所有的线程执行的,也就是停止调度了,因此,必须保证该异常能被及时处理,为调度线程提供稳定运行的条件。
2.核心线程池ThreadPoolExecutor的使用
2.1核心方法:
前面提到的不管是newCachedThreadPool();还是newFixedThreadPool(int nThread)等创建线程池的方法,通过源码的分析,其实际上都是对ThreadPoolExecutor类中该构造方法:
public ThreadPoolExecutor(int var1, int var2, long var3, TimeUnit var5, BlockingQueue<Runnable> var6,ThreadFactory var7, RejectedExecutionHandler var8) {this.ctl = new AtomicInteger(ctlOf(-536870912, 0));this.mainLock = new ReentrantLock();this.workers = new HashSet();this.termination = this.mainLock.newCondition();if (var1 >= 0 && var2 > 0 && var2 >= var1 && var3 >= 0L) {if (var6 != null && var7 != null && var8 != null) {this.acc = System.getSecurityManager() == null ? null : AccessController.getContext();this.corePoolSize = var1;this.maximumPoolSize = var2;this.workQueue = var6;this.keepAliveTime = var5.toNanos(var3);this.threadFactory = var7;this.handler = var8;} else {throw new NullPointerException();}} else {throw new IllegalArgumentException();}}
的封装。
该方法是创建线程池的核心方法,通过该构造函数,可以创建各种各样的线程池,其核心参数的解释:
- corePoolSize: 核心池的大小,这个参数跟后面讲述的线程池的实现原理有非常大的关系。在创建了线程池后,默认情况下,线程池中并没有任何线程,而是等待有任务到来才创建线程去执行任务,除非调用了prestartAllCoreThreads()或者prestartCoreThread()方法,从这2个方法的名字就可以看出,是预创建线程的意思,即在没有任务到来之前就创建corePoolSize个线程或者一个线程。默认情况下,在创建了线程池后,线程池中的线程数为0,当有任务来之后,就会创建一个线程去执行任务,当线程池中的线程数目达到corePoolSize后,就会把到达的任务放到缓存队列当中;
- maximumPoolSize:线程池最大线程数,这个参数也是一个非常重要的参数,它表示在线程池中最多能创建多少个线程;
- keepAliveTime:表示线程没有任务执行时最多保持多久时间会终止。默认情况下,只有当线程池中的线程数大于corePoolSize时,keepAliveTime才会起作用,直到线程池中的线程数不大于corePoolSize,即当线程池中的线程数大于corePoolSize时,如果一个线程空闲的时间达到keepAliveTime,则会终止,直到线程池中的线程数不超过corePoolSize。但是如果调用了allowCoreThreadTimeOut(boolean)方法,在线程池中的线程数不大于corePoolSize时,keepAliveTime参数也会起作用,直到线程池中的线程数为0;
- unit: 参数keepAliveTime的时间单位,有7种取值,在TimeUnit类中有7种静态属性:
| TimeUnit.DAYS; //天 TimeUnit.HOURS; //小时 TimeUnit.MINUTES; //分钟 TimeUnit.SECONDS; //秒 TimeUnit.MILLISECONDS; //毫秒 TimeUnit.MICROSECONDS; //微妙 TimeUnit.NANOSECONDS; //纳秒 |
这个时间单元可以参考我这篇文章:java并发包中的TimeUnit的使用
- workQueue: 一个阻塞队列(何为阻塞队列,后续会用一篇文章进行讲解),用来存储等待执行的任务,这个参数的选择也很重要,会对线程池的运行过程产生重大影响,一般来说,这里的阻塞队列有以下几种选择:
| SynchronousQueue:直接提交队列,该队列没有缓存,任务来了直接提交上去。该队列容易执行拒绝策略。 ArrayBlockingQueue: 有界队列,当有新任务执行时,若有空闲线程,则优先执行任务,若线程池已满,则任务加入到队列中,等待线程池有空闲线程。 LinkedBlockingQueue:无界队列,除非系统资源耗尽,否则不会出现任务入队失败的情况。缺点就是当处理速度跟不上任务创建的速度的时候,很容易出现系统内存耗尽的情况 PriorityBlockingQueue:优先任务队列,这是个特殊的队列,该队列可以根据任务自身的优先级顺序先后执行,确保系统性能的同时,还能有很好的质量保证(其他队列是先进先出处理任务的,该队列可以由优先级处理任务) |
2.2例子
下面直接创建一个线程池,模拟支付操作:
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;/*** 线程池模拟支付过程* @author fei**/
public class Pool_demo2 {private static ThreadPoolExecutor poolExecutor=getPoolExecutor();/*** * @param payMon:支付金额* @param key:秘钥等* @param companyName:支付公司*/public void pay(Double payMon,String key,String companyName) {poolExecutor.execute(()->{System.out.println(companyName+ "开始支付,支付金额为:"+payMon+"元,支付时间: "+new SimpleDateFormat("HH:mm:ss").format(new Date()));try {Thread.sleep(1000);//模拟业务时间} catch (InterruptedException e) {e.printStackTrace();}System.out.println("支付成功。。。成功时间: "+new SimpleDateFormat("HH:mm:ss").format(new Date()));});
//lambda表达式,java7及以下可以写成:
// new Runnable() {
//
// @Override
// public void run() {
//
//
// }
// };}/*** 创建这样一个线程池:* 核心线程为20,最大100;* 多于核心线程时,线程存货时间为1分* 缓存队列是有界阻塞队列,最大的缓存数为30* * @return*/private static ThreadPoolExecutor getPoolExecutor(){if (poolExecutor!=null) return poolExecutor;return new ThreadPoolExecutor(20, 100, 1, TimeUnit.MINUTES, new ArrayBlockingQueue<>(30));}public static void main(String[] args) {String name="wz";Pool_demo2 demo2=new Pool_demo2();for (int i = 0; i < 16; i++) {demo2.pay(5.00,null, name);}}
}这次使用了有界队列举例,其实和之前用Executors生成一定数量的线程池是差不多的。
3.拒绝策略
3.1含义/解释
在第二节的时候,给出的创建线程池的核心构造方法时,有这样的一个参数:
RejectedExecutionHandler var8 这个RejectedExecutionHandler到底是什么呢,有什么用呢,下面我们来进行讲解下:
首先:我们从一二章可以看出,无论是有界队列还是无界队列,实际上,如果创建任务的队列比处理任务的速度快很多,系统资源还是很容易被消耗完的,假如没有相关措施,那么很多时候,该系统就是不完善的,那如何解决呢,其实,这个问题就是本章要学的:拒绝策略。
其次: RejectedExecutionHandler从名字上就可以看出,翻译过来就是拒绝提交执行者,也就是,拒绝策略用到的,就是RejectedExecutionHandler这个接口的实现类,目前内置的拒绝策略(实现RejectedExecutionHandler接口)如下:
- AbortPolicy
该策略直接抛异常,阻止系统正常的工作 - CallerRunsPolicy
只要线程池未关闭,该策略直接在调用者线程中,运行当前被丢弃的任务。显然这样做不会真的丢弃任务,但任务提交线程的性能极有可能会急剧下降。 - DiscardOldestPolicy
该策略将丢弃最老的一个请求,也就是即将被执行的一个任务,并尝试再次提交当前任务。 - DiscardPolicy
该策略默默地丢弃无法处理的任务,不予任何处理,如果允许任务丢失,我觉得这可能是最好的一种方案吧。
当然,如果以上均无法满足我们的请求,我们可以自己实现RejectedExecutionHandler接口的。
3.2 例子
我们以第二节的例子稍微修改下,把线程池和队列的容量减少,然后增大任务的创建量,延长业务处理时间,让线程池和队列都满了,执行后续的拒绝策略:
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;/*** 线程池模拟支付过程* @author fei**/
public class Pool_demo2 {private static ThreadPoolExecutor poolExecutor=getPoolExecutor();/*** * @param payMon:支付金额* @param key:秘钥等* @param companyName:支付公司*/public void pay(Double payMon,String key,String companyName) {poolExecutor.execute(()->{System.out.println(companyName+ "开始支付,支付金额为:"+payMon+"元,支付时间: "+new SimpleDateFormat("HH:mm:ss").format(new Date()));try {Thread.sleep(20000);//模拟业务时间--延长业务时间} catch (InterruptedException e) {e.printStackTrace();}System.out.println("支付成功。。。成功时间: "+new SimpleDateFormat("HH:mm:ss").format(new Date()));});} /*** 创建这样一个线程池:* 核心线程为3,最大10;* 多于核心线程时,线程存货时间为1分* 缓存队列是有界阻塞队列,最大的缓存数为10* * @return*/private static ThreadPoolExecutor getPoolExecutor(){if (poolExecutor!=null) return poolExecutor;return new ThreadPoolExecutor(3, 10, 1, TimeUnit.MINUTES, new ArrayBlockingQueue<>(10),(task,pool)->{System.out.println("系统繁忙,请稍后再试(实际上是线程池已满,处理不了这么多,我就是不告诉你,哈哈)....");//以上是拒绝策略});}public static void main(String[] args) {String name="wz";Pool_demo2 demo2=new Pool_demo2();for (int i = 0; i < 23; i++) {demo2.pay(5.00,null, name);}}
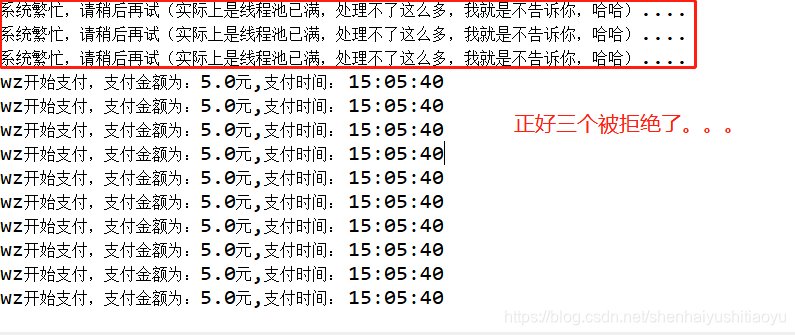
}运行后输出:
我们从输出可以看,当任务创建量大于线程池容量时,就会执行拒绝策略,同时我们还看到,实际上系统所容纳的线程量,是线程池+队列的容量,而不单单是线程池的容量。本例中可以看出,线程池是10个容量,队列是10个,一下子创建23个线程后,相减就可以得到三个线程是来不及处理就被拒绝了的。
这到底是怎么个处理方式呢,这回,我们再回到线程池提交任务时的源码看一下:
public void execute(Runnable var1) {if (var1 == null) {throw new NullPointerException();} else {int var2 = this.ctl.get();if (workerCountOf(var2) < this.corePoolSize) {if (this.addWorker(var1, true)) { // a行return;}var2 = this.ctl.get();}if (isRunning(var2) && this.workQueue.offer(var1)) { // b行 int var3 = this.ctl.get();if (!isRunning(var3) && this.remove(var1)) {this.reject(var1);} else if (workerCountOf(var3) == 0) {this.addWorker((Runnable) null, false);}} else if (!this.addWorker(var1, false)) {// c行 this.reject(var1);}}}
a行:如果当前线程数少于corePoolSize(可能是由于addWorker()操作已经包含对线程池状态的判断,如此处没加,而入workQueue前加了)
b行:如果线程池RUNNING状态,且入队列成功,那么就执行该任务
c行:如果线程池满了,而且无法加入到队列当中,那么就执行拒绝策略!
这次,终于明白了吧,总体的容量就是线程池+队列的容量,同时,线程池还没满时,并没有马上执行,是等待是否还有任务提交,有的话加入到线程池,然后等到满了,就一次性去执行了。这就是我们第一节测出的线程池是分批执行的原因啦~~~
总结
以前我看不懂我们总监写的线程池代码,现在一看,其实非常简单,只要掌握了原理,多看书,多练习,就会有一天,你也能写出让同事看得一脸懵逼只喊666的代码!!!
这篇关于java线程学习(八):多线程高级使用之线程池的使用(非常推荐,涉及:ThreadPoolExecutor,Executors,ThreadPoolExecutor,ScheduledThreadP)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





