本文主要是介绍Flink Flink中的合流,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、Flink中的基本合流操作
在实际应用中,我们经常会遇到来源不同的多条流,需要将它们的数据进行联合处理。所以 Flink 中合流的操作会更加普遍,对应的 API 也更加丰富。
二、联合(Union)
最简单的合流操作,就是直接将多条流合在一起,叫作流的“联合”(union)。联合操作要求必须流中的数据类型必须相同,合并之后的新流会包括所有流中的元素,数据类型不变。
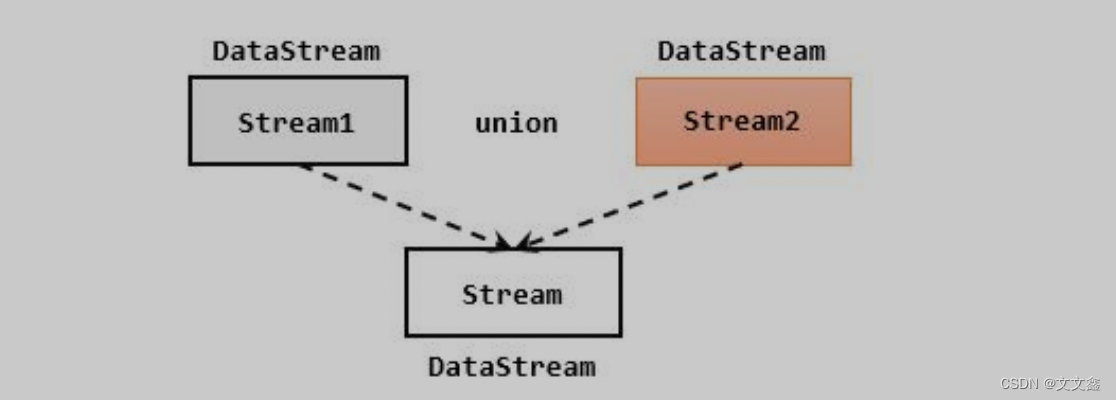
在代码中,我们只要基于 DataStream 直接调用.union()方法,传入其他 DataStream 作为参数,就可以实现流的联合了;得到的依然是一个 DataStream:
stream1.union(stream2, stream3, ...)
注意:union()的参数可以是多个 DataStream,所以联合操作可以实现多条流的合并。
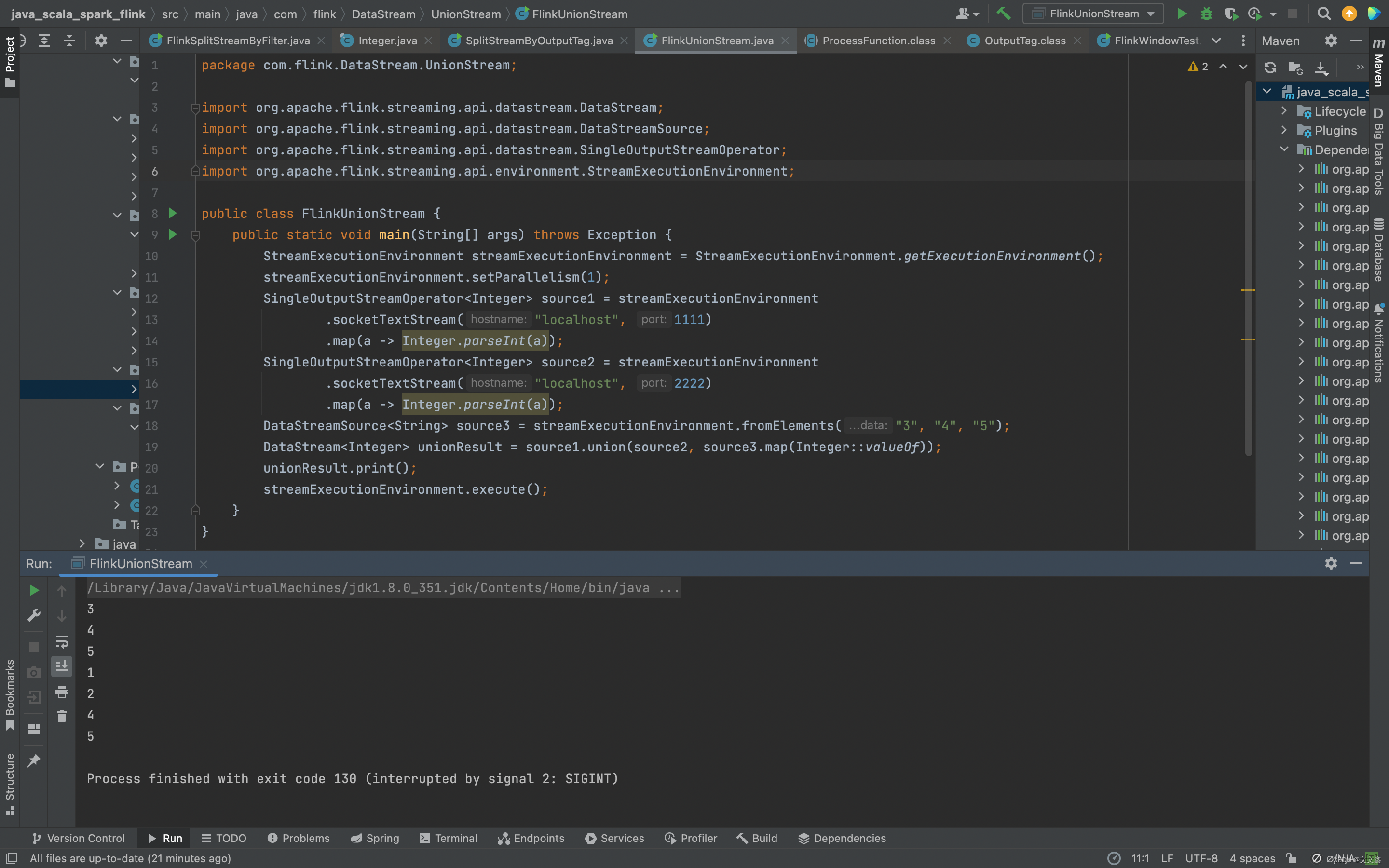
代码实现:我们可以用下面的代码做一个简单测试:
package com.flink.DataStream.UnionStream;import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;public class FlinkUnionStream {public static void main(String[] args) throws Exception {StreamExecutionEnvironment streamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();streamExecutionEnvironment.setParallelism(1);SingleOutputStreamOperator<Integer> source1 = streamExecutionEnvironment.socketTextStream("localhost", 1111).map(a -> Integer.parseInt(a));SingleOutputStreamOperator<Integer> source2 = streamExecutionEnvironment.socketTextStream("localhost", 2222).map(a -> Integer.parseInt(a));DataStreamSource<String> source3 = streamExecutionEnvironment.fromElements("3", "4", "5");DataStream<Integer> unionResult = source1.union(source2, source3.map(Integer::valueOf));unionResult.print();streamExecutionEnvironment.execute();}
}
三、连接(Connect)
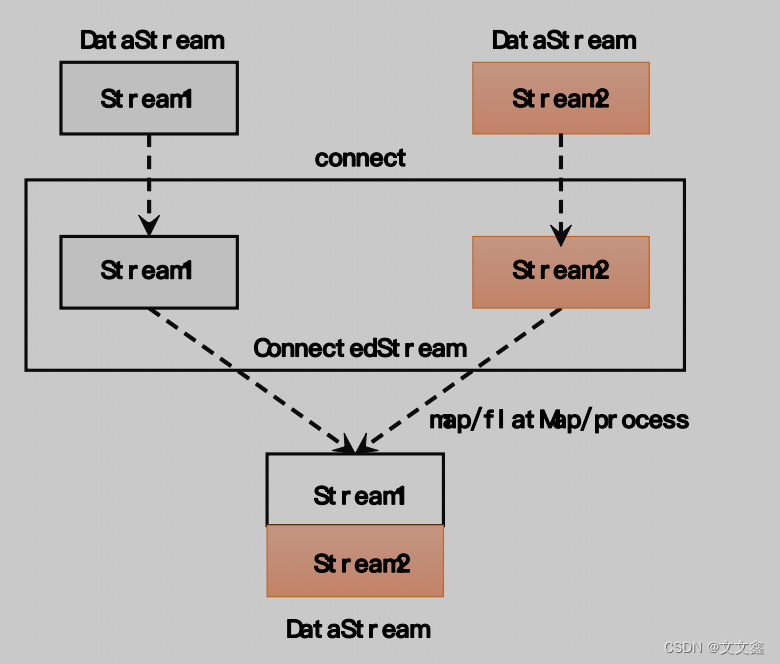
为了处理更加灵活,连接操作允许流的数据类型不同。但我们知道一个DataStream中的数据只能有唯一的类型,所以连接得到的结果并不是DataStream,而是一个“连接流”。连接流可以看成是两条流形式上的“统一”,被放在了一个同一个流中;事实上内部仍保持各自的数据形式不变,彼此之间是相互独立的。要想得到新的DataStream,还需要进一步定义一个“同处理”(co-process)转换操作,用来说明对于不同来源、不同类型的数据,怎样分别进行处理转换、得到统一的输出类型。所以整体上来,两条流的连接就像是“一国两制”,两条流可以保持各自的数据类型、处理方式也可以不同,不过最终还是会统一到同一个DataStream中。
package com.flink.DataStream.UnionStream;import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoMapFunction;public class FlinkConnectStream {public static void main(String[] args) throws Exception {StreamExecutionEnvironment streamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();streamExecutionEnvironment.setParallelism(1);//TODO 定义数字流SingleOutputStreamOperator<Integer> source1 = streamExecutionEnvironment.socketTextStream("localhost", 1111).map(a -> Integer.parseInt(a));SingleOutputStreamOperator<String> source2 = streamExecutionEnvironment.socketTextStream("localhost", 2222);/**TODO 连接两个流一次只能连接 2 条流两条流的数据类型可以不一致所以得到的结果不再是一个DataStream,而是一个"连接流"ConnectedStreams连接后可以调用 map、flatmap、process 来处理,但是各处理各的*/ConnectedStreams<Integer, String> connectedStreams = source1.connect(source2);SingleOutputStreamOperator<Object> map = connectedStreams.map(new CoMapFunction<Integer, String, Object>() {@Overridepublic Object map1(Integer integer) throws Exception {return "来源于数字流" + integer.toString();}@Overridepublic Object map2(String s) throws Exception {return "来源于字符流" + s;}});map.print();streamExecutionEnvironment.execute();}
}
上面的代码中,ConnectedStreams 有两个类型参数,分别表示内部包含的两条流各自的数据类型;由于需要“一国两制”,因此调用.map()方法时传入的不再是一个简单的MapFunction,而是一个 CoMapFunction,表示分别对两条流中的数据执行 map 操作。这个接口有三个类型参数,依次表示第一条流、第二条流,以及合并后的流中的数据类型。需要实现的方法也非常直白:.map1()就是对第一条流中数据的 map 操作,.map2()则是针对第二条流。
四、CoProcessFunction
与 CoMapFunction 类似,如果是调用.map()就需要传入一个 CoMapFunction,需要实现map1()、map2()两个方法;而调用.process()时,传入的则是一个 CoProcessFunction。它也是“处理函数”家族中的一员,用法非常相似。它需要实现的就是 processElement1()、processElement2()两个方法,在每个数据到来时,会根据来源的流调用其中的一个方法进行处理。
值得一提的是,ConnectedStreams 也可以直接调用.keyBy()进行按键分区的操作,得到的还是一个 ConnectedStreams:
connectedStreams.keyBy(keySelector1, keySelector2);这里传入两个参数 keySelector1 和 keySelector2,是两条流中各自的键选择器;当然也可以直接传入键的位置值(keyPosition),或者键的字段名(field),这与普通的 keyBy 用法完全一致。ConnectedStreams 进行keyBy 操作,其实就是把两条流中 key 相同的数据放到了一起,然后针对来源的流再做各自处理,这在一些场景下非常有用。
这篇关于Flink Flink中的合流的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






