本文主要是介绍前端下载二进制pdf文件页面空白以及解决从content-disposition获取文件名中文乱码问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、下载文件页面内容空白
问题描述:通过封装下载文件的接口把文件下载下来之后发现页面内容是空白的 但是页数是对的
解决:网上搜索各种方案 发现有人建议使用原生的axios,不做封装处理
附原文链接:前端axios请求二进制数据流转换生成PDF文件空白问题(终极解决方案)大家可参考这个方案(另外:我不明白为什么封装了就不可以)
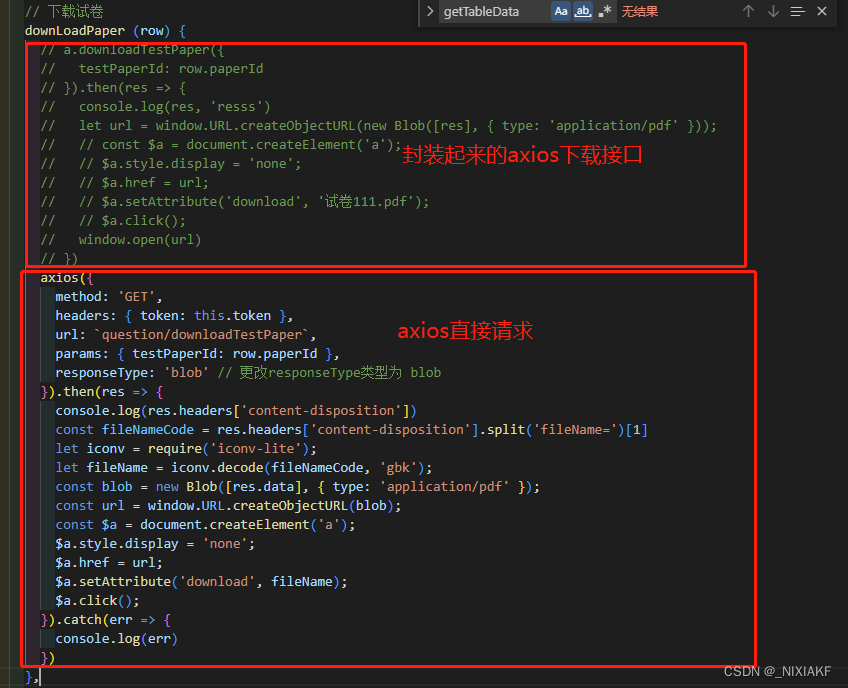
不封装的请求完整代码:
import axios from 'axios'
// 下载试卷downLoadPaper (row) {axios({method: 'GET',headers: { token: this.token },url: `question/downloadTestPaper`,params: { testPaperId: row.paperId },responseType: 'blob' // responseType类型为 blob (二进制流)}).then(res => {console.log(res.headers['content-disposition'])const fileNameCode = res.headers['content-disposition'].split('fileName=')[1]//对文件名乱码转义--【Node.js】使用iconv-lite解决中文乱码let iconv = require('iconv-lite');let fileName = iconv.decode(fileNameCode, 'gbk');const blob = new Blob([res.data], { type: 'application/pdf' });const url = window.URL.createObjectURL(blob);// 拿到返回数据后,将二进制数据生成一个文件url,用URL.createObjectURL生成url时需要传入Blob类型的参数。const $a = document.createElement('a');$a.style.display = 'none';$a.href = url;$a.setAttribute('download', fileName);$a.click();}).catch(err => {console.log(err)})},二、content-disposition里fileName如果是中文会产生乱码问题
如下

解决方案在下载试卷的方法代码里贴上了
另外附 如果出现找不到headers中的’content-disposition’的话
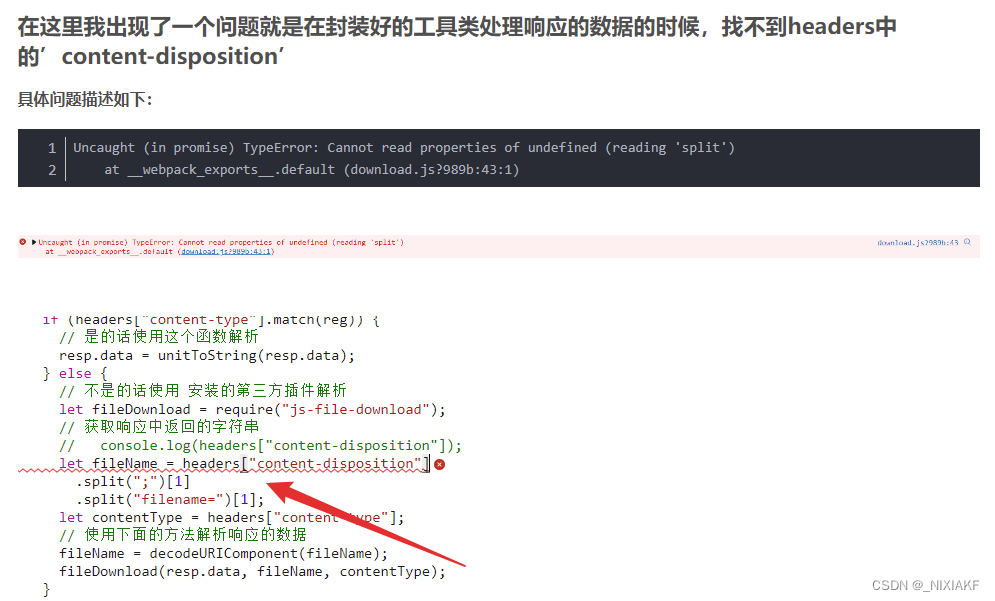
问题描述
显示的是这里出错了,我仔细看了看以后自己的后端没有传递这个参数
但是回去检查了一遍,确实传递了呀
然后我又发现,在浏览器调试器 network中居然有这个属性,但是在响应拦截器中居然没有打印出来,邪门滴很呐!!
产生问题原因
跨域(CORS)请求中,被axios封装好的XMLHttpRequest对象中的方法getResponseHeader()默认只能获取6个基本的字段:Cache-Control、Content-Language、Content-Type、Expires、Last-Modified、Pragma。因此,需要获取其他的属性,需要后端在响应的时候去在Access-Control-Expose-Headers中指定content-disposition属性。
所以这是一个后端的锅,是他没有配置,这个问题去找后端,让他在response中配置放行。
后端解决方案
在controller层中的二进制流文件下载方法下配置放行属性:
response.setHeader("Access-Control-Expose-Headers", "content-disposition");这篇关于前端下载二进制pdf文件页面空白以及解决从content-disposition获取文件名中文乱码问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





