本文主要是介绍StyleGAN 使用指南:生成更逼真的图片,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
StyleGAN 使用指南:生成更逼真的图片
- 提出背景:特征纠缠
- StyleGAN-v1 网络结构
- 映射网络 Mapping network f
- 生成网络 Synthesis network g
- 训练技巧
- 样式混合 mixing regularization
- 截断 Truncation Trick
- 评估指标
- 路径长度 Perceptual path length
- 解耦:让映射空间实现线性可分性
- StyleGAN-v2
- StyleGAN-v3
- StyleGAN-XL
- StyleGAN-T
- 项目代码
提出背景:特征纠缠
传统的生成网络中,有一个问题存在,就是特征纠缠。
比如你想要给人脸模型增加一头卷发,但当你调整与发型相关的参数时,你可能会发现模型生成的人脸同时也改变了肤色、眼睛间距或者表情。这是因为卷发的特征与其他特征在潜在空间中是纠缠的。
StyleGAN-v1 网络结构
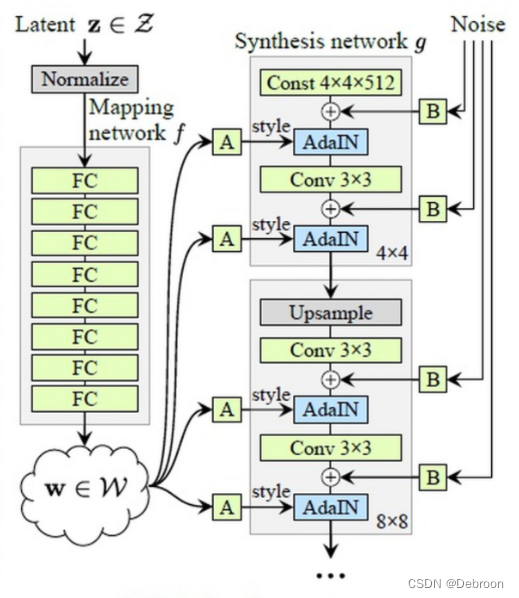
分为俩部分:映射网络 Mapping network f、生成网络 Synthesis network g
映射网络 Mapping network f
-
映射网络 Mapping network f:把 原始数据 z 转成 向量w,解决特征纠缠。
如上图,输入z(512维),经过 8 个全连接层,得到w(512维)。
原始数据(z向量)就像是一个复杂的信号,它包含了所有可能的图像生成因素混合在一起,这些因素包括形状、纹理、颜色和其他视觉细节。
这个向量空间通常高度纠缠,使得直接操作单个因素变得困难,因为改变一个维度可能会影响到多个属性。
映射网络的任务就是像解码器一样工作,它将这个复杂的、高度纠缠的信号转换成一个新的、更加有序的中间潜在空间,即风格空间,其中的每个维度尽可能地表示独立的图像特征。
在风格空间中,向量被重新编排和优化,以便单个维度更有可能对应于图像中的单一生成因素。这允许模型生成器在生成图像时对特定的视觉属性进行精细的控制和调整,而不是一次性调整所有特征。
如上图,向量 w 经过仿射变换 A,得到风格向量 S(style)
生成网络 Synthesis network g
-
生成网络 Synthesis network g : 用于生成图像
把风格向量S输入AdaIN层。
在此前的风格迁移方法中,每个网络只能对应一个特定的风格,而且速度较慢。但是基于AdaIN,我们可以通过“自我调节”生成器的方式快速实现任意图像风格的转换。
特征图的均值和方差包含了图像的风格信息。在AdaIN层中,通过将特征图减去自身的均值再除以方差,实现去除原有风格的效果。然后乘以新风格的方差再加上均值,实现风格转换的目的。
A d a I N ( x i , y ) = σ ( y ) ∗ ( x i − μ ( x i ) σ ( x i ) + μ ( y ) AdaIN(x_{i}, y) = σ(y) * \frac{(x_{i} - μ(x_{i})}{ σ(x_{i}) } + μ(y) AdaIN(xi,y)=σ(y)∗σ(xi)(xi−μ(xi)+μ(y),y 是风格, x i x_{i} xi 是第 i 层
仿射变换过程: 1 ∗ 512 1*512 1∗512维向量W -> 学习仿射变换A -> 风格向量Style 2 ∗ n 2*n 2∗n维向量, y s , i , y b , i y_{s,i},~y_{b,i} ys,i, yb,i
A d a I N ( x i , y ) = y s , i ∗ ( x i − μ ( x i ) σ ( x i ) + y b , i AdaIN(x_{i}, y) = y_{s,i} * \frac{(x_{i} - μ(x_{i})}{ σ(x_{i}) } + y_{b,i} AdaIN(xi,y)=ys,i∗σ(xi)(xi−μ(xi)+yb,i
因为AdaIN层是归一化操作(缩放 + 偏移),通道是独立的(每个通道的特征图,其归一化系数是独立计算的,不受其他通道的影响),所以每个AdaIN层都需要俩个系数,分别对应缩放、偏移。
在AdaIN模块之前向每个通道添加一个缩放过的噪声(Noise),增加生成图像的多样性, B 表示可学习的权重系数
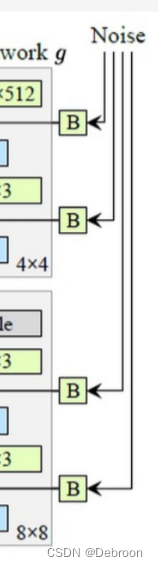
9 级分辨率:生成器从较低分辨率开始,通过一系列的上采样和卷积操作逐渐增加图像的分辨率。每次上采样操作将图像的分辨率乘以2。例如,从4x4到8x8,再到16x16,依此类推。
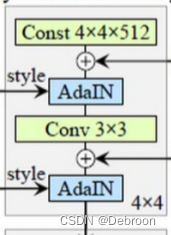
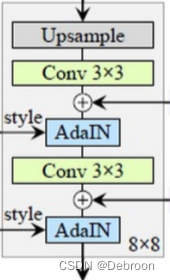
9级分辨率表示经过9次上采样后,影响的特征从宏观到微观。
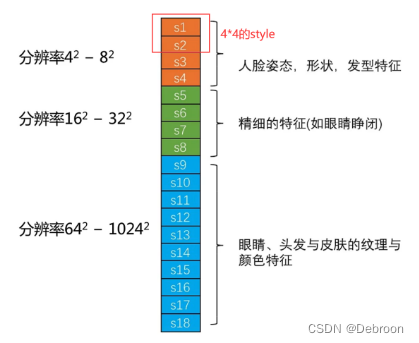
如人脸:
- 4 2 − 8 2 4^{2} - 8^{2} 42−82 是宏观特征(人脸姿态、形状、发型特征)
- 1 6 2 − 3 2 2 16^{2}-32^{2} 162−322 是精细特征(眼睛睁闭)
- 6 4 2 − 102 4 2 64^{2}-1024^{2} 642−10242 是微观特征(眼睛、头发、皮肤的纹理、颜色特征)
修改不同分辨率的风格向量,就能修改到人脸的属性的特征。
训练技巧
样式混合 mixing regularization
样式混合:随机交换量 w 向量的部分内容,进行拼接,防止相邻特征耦合。
比如小明的脸型,配小红的头发、小明的宏观特征,配小宏的精细特征。
如果一个人的眼睛位于人脸的上部,那么鼻子很可能位于眼睛的下方。这种相关性是由于人脸的结构和几何关系所决定的。
当我们使用特征向量来表示人脸时,这种相关性可能会导致特征之间的耦合。
例如,如果我们使用一个特征向量来表示眼睛的形状和位置,另一个特征向量来表示鼻子的形状和位置,那么这两个特征向量中的部分内容可能会相互影响。
在这种情况下,如果我们想要对眼睛和鼻子进行独立的分析和处理,相邻特征之间的耦合可能会干扰我们的结果。
拼接的特征向量的每个位置的特征来自于不同的人的人脸。这样的混合可以确保在新的特征向量中,每个位置的特征来自于不同的人的人脸,从而避免了相邻特征之间的耦合。
截断 Truncation Trick
截断 Truncation Trick:解决低密度区域的生成质量问题。
低密度区域是,某些属性总体分布比例低,如长发及腰的男性。
- 找到数据的平均点
- 计算其他所有点,到平均点的距离
- 对每个距离按照统一标准进行压缩
这样就能将数据点都聚拢了,但是又不会改变点与点之间的距离关系。
举个例子,有10个男性和10个女性的数据点。
只有1个男性是长发及腰的。
我们计算每个数据点到平均点的距离,并选择一个阈值为2。
根据距离,我们发现长发及腰的男性距离平均点的距离较远,超过了阈值。
们将低密度区域中的数据点(即只有1个长发及腰的男性)聚拢在一起,并移动到与平均点距离最近的位置,同时保持其他数据点之间的距离关系不变。
评估指标
路径长度 Perceptual path length
潜在向量Latent:生成器是否选择的路线,如果是最近,那就是好的潜在向量。
如下图紫线上随机采样一个点,还是狗子的图片,就是选择了最近的路线;而绿线采样是床,就绕远了。
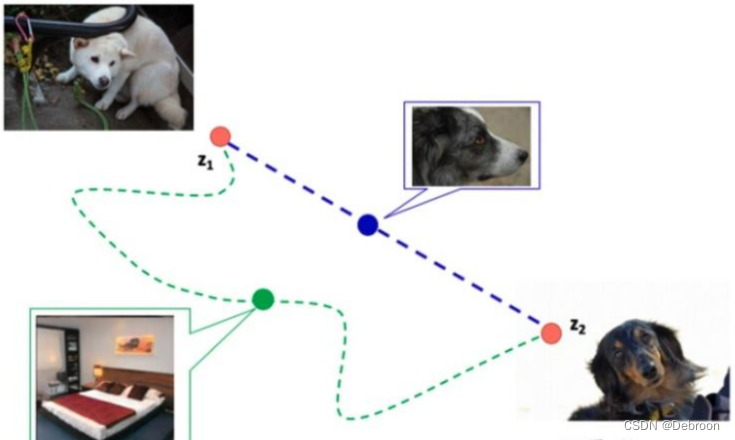
怎么评估这个路径长度呢?
在训练过程中,我们可以选择相邻的时间节点,并计算它们生成的图像之间的路径长度,最后得这些距离的平均值。
较小的路径长度表示生成图像之间更加相似,而较大的路径长度则表示它们之间存在较大的差异。
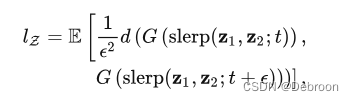
- t :某一时间点
- d :空间距离
- skerp :采样方法
- E :平均值
解耦:让映射空间实现线性可分性
假设我们有一个人脸生成模型,可以根据输入的随机向量生成逼真的人脸图像。使用传统的生成模型,如果我们想要生成特定属性的人脸,比如男性或女性,通常需要在随机向量的某些维度上进行微调。但是这种方式不够直观,而且可能需要花费大量时间来搜索合适的向量。
而解耦的思想则可以改善这个问题。通过解耦,我们可以将生成模型的随机向量分为多个独立的部分,每个部分对应于一个特定的属性,比如年龄、性别、发色等。这样,我们可以直接在这些特定属性的部分进行调整,而不会影响其他属性。例如,如果我们想要生成一个年轻女性的人脸,我们只需要在性别和年龄属性的部分进行调整,而不需要关心其他属性。这使得我们能够更直观地控制生成的人脸属性,同时减少了搜索的时间和计算量。
总而言之,解耦的思想通过将生成模型的随机向量分为多个独立的部分,让我们能够更直观地控制生成的属性,提高了生成模型的可操作性和效率。
StyleGAN-v2
StyleGAN-v3
StyleGAN-XL
StyleGAN-T
项目代码
StyleGAN:https://github.com/NVlabs/stylegan
StyleGAN2:https://github.com/NVlabs/stylegan2
StyleGAN3:https://github.com/NVlabs/stylegan3
Stylegan-xl:https://github.com/autonomousvision/stylegan-xl
Stylegan-t:https://github.com/autonomousvision/stylegan-t
这篇关于StyleGAN 使用指南:生成更逼真的图片的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





