本文主要是介绍说好不哭,但是再次听到你的新歌还是没忍住,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
谈到周董,说他是我们的青春也不为过吧。从最开始的龙卷风,黑色幽默,我记得那个时候我才四五岁听着姐姐的mp3,疯狂循环这些歌。到后来的安静,搁浅,就天天扯着嗓子飙高音。当时的我们根本不懂歌中的心酸,现在慢慢经历过,体验过才发现成人的世界真的有太多的苦涩。昨天他发布新歌不到三分钟,各大音乐平台就被席卷了,qq音乐卡都上了热搜头条,真的只能说周董牛逼!!!
作为程序猿的我,能做的也只有敲点代码来表示对偶像的崇拜了。

开始爬取超话
这是我们使用了高级搜索功能之后的网页,可以看到
url='https://s.weibo.com/weibo/?q=%E5%91%A8%E6%9D%B0%E4%BC%A6&scope=ori&suball=1×cope=custom:2019-09-16:2019-09-17&Refer=g'
然后仔细分析这个url,发现q=后面接的字符串其实就是周杰伦,timescope=custom:后面接的是时间,所以我们就需要自己设置关键词和时间这两个参数构造合适的url。(** 或者把之前的网页url中q=后面的字符串直接复制过去就是搜索周董了**)
得到了url剩下的就是防止反爬和网页解析了
我们还是检查元素然后找到了每篇超话的内容的提取标签,接下来就是提取内容
# 2、解析数据r_json = json.loads(r.text)cards = r_json['data']['cards']# 2.1、第一次请求cards包含微博和头部信息,以后请求返回只有微博信息if len(cards) > 1:card_group = cards[2]['card_group'] #if len(cards) > 1 else cards[0]['card_group']else:card_group =cards[0]['card_group']for card in card_group:# 创建保存数据的列表,最后将它写入csv文件sina_columns = []mblog = card['mblog']# 2.2、解析用户信息user = mblog['user']# 爬取用户信息,微博有反扒机制,频率太快就请求就返回418try:basic_infos = spider_user_info(user['id'])except:print('用户信息爬取失败!id=%s' % user['id'])continue# 把用户信息放入列表sina_columns.append(user['id'])sina_columns.extend(basic_infos)# 2.3、解析微博内容r_since_id = mblog['id']# 过滤标签sina_text = re.compile(r'<[^>]+>', re.S).sub(' ', mblog['text'])# 除去开头信息sina_text = sina_text.replace('周杰伦超话', '').strip()# 将微博内容放入列表sina_columns.append(r_since_id)sina_columns.append(sina_text)print(sina_columns)# sina_columns数据格式:['用户id', '用户名', '性别', '地区', '生日', '微博id', '微博内容']
然后我们得到了数据,大概是这个亚子

然后我们还可以用pyecharts做一下数据可视化
数据可视化部分
dic = read_csv_to_dict(2)# 生成二维数组gender_count_list = [list(z) for z in zip(dic.keys(), dic.values())]print(gender_count_list)pie = (Pie().add("", gender_count_list).set_colors(["red", "blue"]).set_global_opts(title_opts=opts.TitleOpts(title="性别分析")).set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}")))pie.render('gender.html')def analysis_age():"""分析年龄:return:"""dic = read_csv_to_dict(4)# 生成柱状图sorted_dic = {}for key in sorted(dic):sorted_dic[key] = dic[key]print(sorted_dic)bar = (Bar().add_xaxis(list(sorted_dic.keys())).add_yaxis("周杰伦打榜粉丝年龄分析", list(sorted_dic.values())).set_global_opts(yaxis_opts=opts.AxisOpts(name="数量"),xaxis_opts=opts.AxisOpts(name="年龄"),))bar.render('age_bar.html')# 生成饼图age_count_list = [list(z) for z in zip(dic.keys(), dic.values())]pie = (Pie().add("", age_count_list).set_global_opts(title_opts=opts.TitleOpts(title="周杰伦打榜粉丝年龄分析")).set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}")))pie.render('age-pie.html')def analysis_area():"""分析地区:return:"""dic = read_csv_to_dict(3)area_count_list = [list(z) for z in zip(dic.keys(), dic.values())]print(area_count_list)map = (Map().add("周杰伦打榜粉丝地区分析", area_count_list, "china").set_global_opts(visualmap_opts=opts.VisualMapOpts(max_=200),))map.render('area.html')def analysis_sina_content():"""分析微博内容:return:"""# 读取内容列dic = read_csv_to_dict(6)# 数据清洗,去掉无效词jieba.analyse.set_stop_words(STOP_WORDS_FILE_PATH)# 词数统计words_count_list = jieba.analyse.textrank(' '.join(dic.keys()), topK=50, withWeight=True)print(words_count_list)# 生成词云word_cloud = (WordCloud().add("", words_count_list, word_size_range=[20, 100], shape=SymbolType.DIAMOND).set_global_opts(title_opts=opts.TitleOpts(title="周杰伦打榜微博内容分析")))word_cloud.render('word_cloud.html')成果图
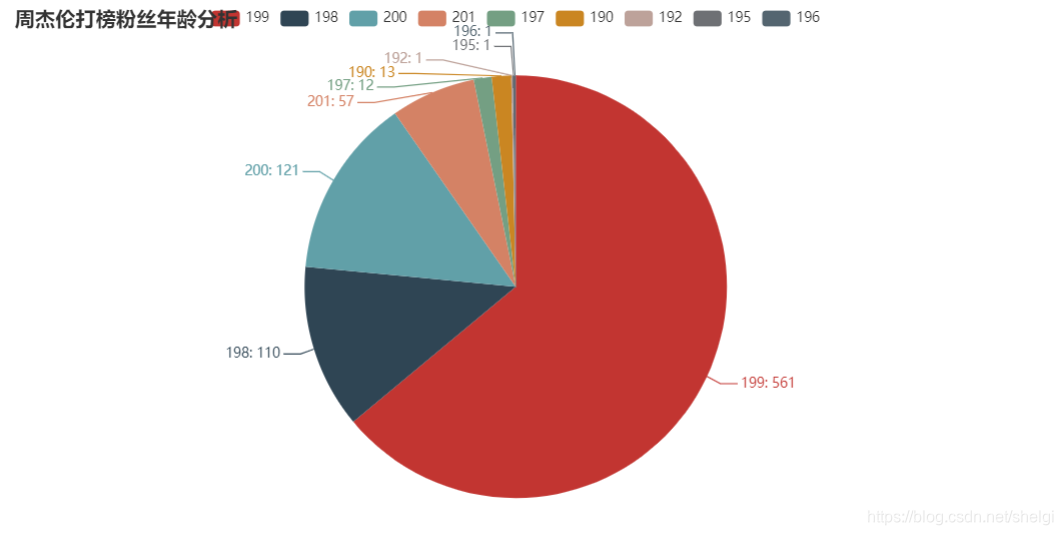
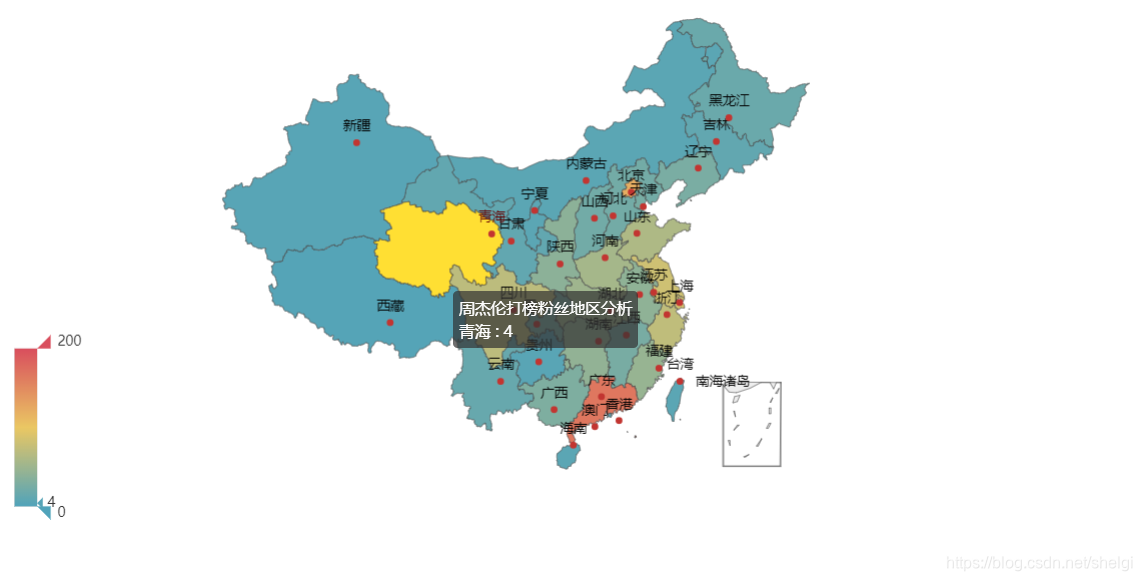
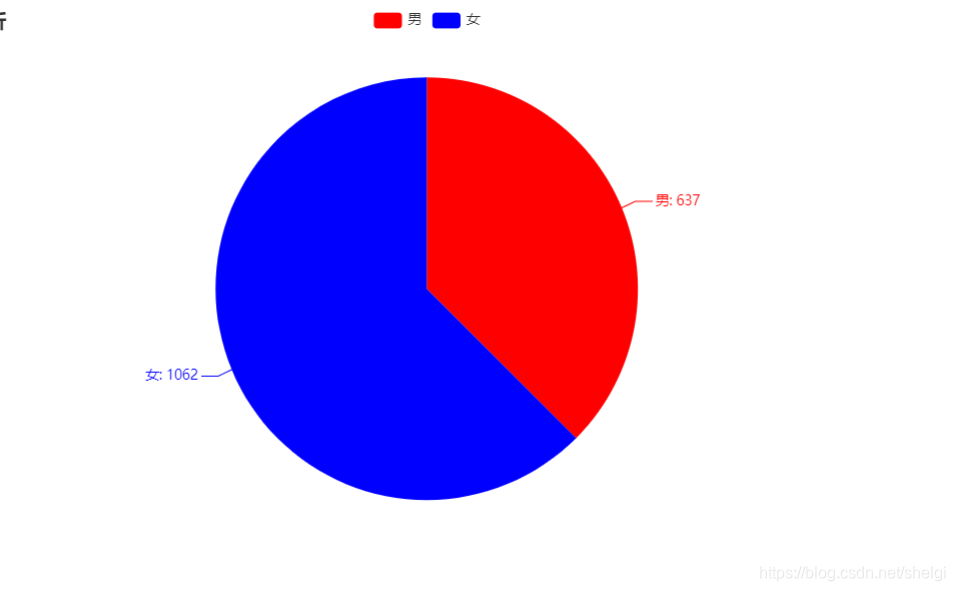

这篇关于说好不哭,但是再次听到你的新歌还是没忍住的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







