本文主要是介绍8.Alertmanager监控报警,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- Alertmanager 概述
- 部署Alertmanager组件
- 1.下载 alertmanager
- 2.systemd 管理
- 3.新建alertmanager.yml报警通知文件
- 4.创建企业微信的消息模版
- 5.配置报警规则
- 主机监控规则文件
- 容器监控规则文件
- redis监控规则文件
- 服务停止监控规则
- 6.修改prometheus
alertmanager 下载地址:https://github.com/prometheus/alertmanager/releases
Alertmanager 概述
Alertmanager处理客户端应用程序(如Prometheus服务器)发送的告警。它负责对它们进行重复数据删除,分组和路由,以及正确的接收器集成,例如电子邮件,PagerDuty或OpsGenie。它还负责警报的静默和抑制。
以下描述了Alertmanager实现的核心概念。请参阅配置文档以了解如何更详细地使用它们。
分组(Grouping)
分组将类似性质的告警分类为单个通知。这在大型中断期间尤其有用,因为许多系统一次失败,并且可能同时发射数百到数千个警报。
示例:发生网络分区时,群集中正在运行数十或数百个服务实例。一半的服务实例无法再访问数据库。Prometheus中的告警规则配置为在每个服务实例无法与数据库通信时发送告警。结果,数百个告警被发送到Alertmanager。
作为用户,只能想要获得单个页面,同时仍能够确切地看到哪些服务实例受到影响。因此,可以将Alertmanager配置为按群集和alertname对警报进行分组,以便发送单个紧凑通知。
这些通知的接收器通过配置文件中的路由树配置告警的分组,定时的进行分组通知。 抑制(Inhibition)
如果某些特定的告警已经触发,则某些告警需要被抑制。
示例:如果某个告警触发,通知无法访问整个集群。Alertmanager可以配置为在该特定告警触发时将与该集群有关的所有其他告警静音。这可以防止通知数百或数千个与实际问题无关的告警触发。
静默(SILENCES)
静默是在给定时间内简单地静音告警的方法。基于匹配器配置静默,就像路由树一样。检查告警是否匹配或者正则表达式匹配静默。如果匹配,则不会发送该告警的通知。在Alertmanager的Web界面中可以配置静默。
客户端行为(Client behavior)
Alertmanager对其客户的行为有特殊要求。这些仅适用于不使用Prometheus发送警报的高级用例。
设置警报和通知的主要步骤如下:
设置并配置Alertmanager;
配置Prometheus对Alertmanager访问;
在普罗米修斯创建警报规则;
部署Alertmanager组件
首先需要创建Alertmanager的报警通知文件,我这里使用企业微信报警,其中企业微信需要申请账号认证,方式如下:
访问网站注册企业微信账号(不需要企业认证)。
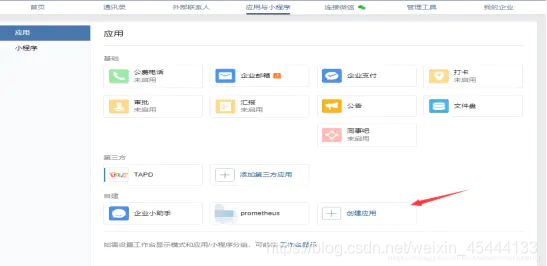
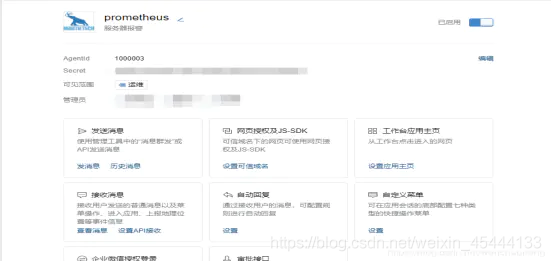
访问apps创建第三方应用,点击创建应用按钮 -> 填写应用信息:
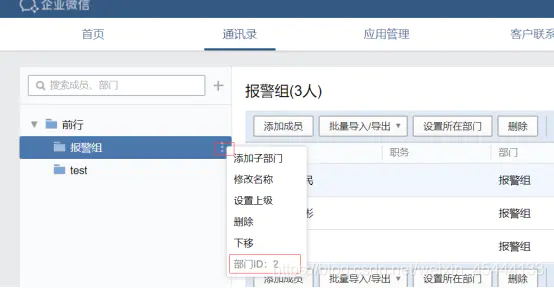
创建报警组,获取组ID:
1.下载 alertmanager
cd /opt/plg/tools
wget https://github.com/prometheus/alertmanager/releases/download/v0.21.0/alertmanager-0.21.0.linux-amd64.tar.gz
tar -xvf alertmanager-0.21.0.linux-amd64.tar.gz
mv alertmanager-0.21.0.linux-amd64 ../alertmanager
cd ../alertmanager
2.systemd 管理
cat >/usr/lib/systemd/system/alertmanager.service <<EOF
[Unit]
Description=alertmanager
Documentation=https://github.com/prometheus/alertmanager
After=network.target
[Service]
Type=simple
ExecStart=/opt/plg/alertmanager/alertmanager --config.file=/opt/plg/alertmanager/alertmanager.yml
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
3.新建alertmanager.yml报警通知文件
vim alertmanager.yml
global:resolve_timeout: 2msmtp_smarthost: smtp.163.com:25smtp_from: 15xxx@163.comsmtp_auth_username: 15xxxx@163.comsmtp_auth_password: zxxxtemplates:- '/data/alertmanager/conf/template/wechat.tmpl'
route:group_by: ['alertname_wechat']group_wait: 1sgroup_interval: 1sreceiver: 'wechat'repeat_interval: 1hroutes:- receiver: wechatmatch_re:serverity: wechat
receivers:
- name: 'email'email_configs:- to: '8xxxxx@qq.com'send_resolved: true
- name: 'wechat'wechat_configs:- corp_id: 'wwd402ce40b4720f24'to_party: '2'agent_id: '1000002'api_secret: '9nmYa4p12OkToCbh_oNc'send_resolved: true ## 发送已解决通知
参数说明:
corp_id: 企业微信账号唯一 ID, 可以在我的企业中查看。
to_party: 需要发送的组。
agent_id: 第三方企业应用的ID,可以在自己创建的第三方企业应用详情页面查看。
api_secret:第三方企业应用的密钥,可以在自己创建的第三方企业应用详情页面查看。
4.创建企业微信的消息模版
vim template/wechat.tmpl
{{ define "wechat.default.message" }}
{{ range $i, $alert :=.Alerts }}
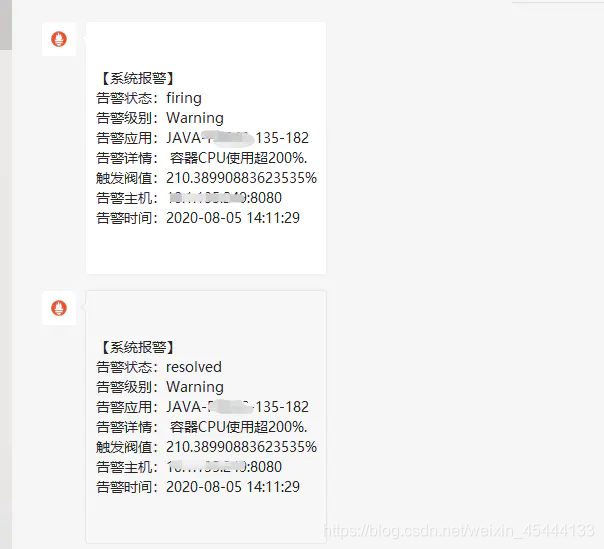
【系统报警】
告警状态:{{ .Status }}
告警级别:{{ $alert.Labels.severity }}
告警应用:{{ $alert.Annotations.summary }}
告警详情:{{ $alert.Annotations.description }}
触发阀值:{{ $alert.Annotations.value }}
告警主机:{{ $alert.Labels.instance }}
告警时间:{{ $alert.StartsAt.Format "2006-01-02 15:04:05" }}
{{ end }}
{{ end }}
这个报警的模板其中的值是在Prometheus触发的报警信息中提取的,所以你可以根据自己的定义进行修改。
5.配置报警规则
主机监控规则文件
vim rules/host_sys.yml
groups:
- name: Hostrules:- alert: HostMemory Usageexpr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100 > 90for: 1mlabels:name: Memoryseverity: Warningannotations:summary: " {{ $labels.appname }} "description: "宿主机内存使用率超过90%."value: "{{ $value }}"- alert: HostCPU Usageexpr: sum(avg without (cpu)(irate(node_cpu_seconds_total{mode!='idle'}[5m]))) by (instance,appname) > 0.8for: 1mlabels:name: CPUseverity: Warningannotations:summary: " {{ $labels.appname }} "description: "宿主机CPU使用率超过80%."value: "{{ $value }}"- alert: HostLoadexpr: node_load5 > 20for: 1mlabels:name: Loadseverity: Warningannotations:summary: "{{ $labels.appname }} "description: " 主机负载5分钟超过20."value: "{{ $value }}"- alert: HostFilesystem Usageexpr: (node_filesystem_size_bytes-node_filesystem_free_bytes)/node_filesystem_size_bytes*100>80for: 1mlabels:name: Diskseverity: Warningannotations:summary: " {{ $labels.appname }} "description: " 宿主机 [ {{ $labels.mountpoint }} ]分区使用超过80%."value: "{{ $value }}%"- alert: HostDiskio writesexpr: irate(node_disk_writes_completed_total{job=~"Host"}[1m]) > 10for: 1mlabels:name: Diskioseverity: Warningannotations:summary: " {{ $labels.appname }} "description: " 宿主机 [{{ $labels.device }}]磁盘1分钟平均写入IO负载较高."value: "{{ $value }}iops"- alert: HostDiskio readsexpr: irate(node_disk_reads_completed_total{job=~"Host"}[1m]) > 10for: 1mlabels:name: Diskioseverity: Warningannotations:summary: " {{ $labels.appname }} "description: " 宿机 [{{ $labels.device }}]磁盘1分钟平均读取IO负载较高."value: "{{ $value }}iops"- alert: HostNetwork_receiveexpr: irate(node_network_receive_bytes_total{device!~"lo|bond[0-9]|cbr[0-9]|veth.*|virbr.*|ovs-system"}[5m]) / 1048576 > 10for: 1mlabels:name: Network_receiveseverity: Warningannotations:summary: " {{ $labels.appname }} "description: " 宿主机 [{{ $labels.device }}] 网卡5分钟平均接收流量超过10Mbps."value: "{{ $value }}3Mbps"- alert: hostNetwork_transmitexpr: irate(node_network_transmit_bytes_total{device!~"lo|bond[0-9]|cbr[0-9]|veth.*|virbr.*|ovs-system"}[5m]) / 1048576 > 10for: 1mlabels:name: Network_transmitseverity: Warningannotations:summary: " {{ $labels.appname }} "description: " 宿主机 [{{ $labels.device }}] 网卡5分钟内平均发送流量超过10Mbps."value: "{{ $value }}3Mbps"
容器监控规则文件
vim rules/container_sys.yml
groups:
- name: Containerrules:- alert: ContainerCPUexpr: (sum by(name,instance) (rate(container_cpu_usage_seconds_total{image!=""}[5m]))*100) > 200for: 1mlabels:name: CPU_Usageseverity: Warningannotations:summary: "{{ $labels.name }} "description: " 容器CPU使用超200%."value: "{{ $value }}%"- alert: Memory Usageexpr: (container_memory_usage_bytes{name=~".+"} - container_memory_cache{name=~".+"}) / container_spec_memory_limit_bytes{name=~".+"} * 100 > 200for: 1mlabels:name: Memoryseverity: Warningannotations:summary: "{{ $labels.name }} "description: " 容器内存使用超过200%."value: "{{ $value }}%"- alert: Network_receiveexpr: irate(container_network_receive_bytes_total{name=~".+",interface=~"eth.+"}[5m]) / 1048576 > 10for: 1mlabels:name: Network_receiveseverity: Warningannotations:summary: "{{ $labels.name }} "description: "容器 [{{ $labels.device }}] 网卡5分钟平均接收流量超过10Mbps."value: "{{ $value }}Mbps"- alert: Network_transmitexpr: irate(container_network_transmit_bytes_total{name=~".+",interface=~"eth.+"}[5m]) / 1048576 > 10for: 1mlabels:name: Network_transmitseverity: Warningannotations:summary: "{{ $labels.name }} "description: "容器 [{{ $labels.device }}] 网卡5分钟平均发送流量超过10Mbps."value: "{{ $value }}Mbps"
redis监控规则文件
vim rules/redis_check.yml
groups:
- name: redisdownrules:- alert: RedisDownexpr: redis_up == 0for: 1mlabels:name: instanceseverity: Criticalannotations:summary: " {{ $labels.alias }}"description: " 服务停止运行 "value: "{{ $value }}"- alert: Redis linked too many clientsexpr: redis_connected_clients / redis_config_maxclients * 100 > 80for: 1mlabels:name: instanceseverity: Warningannotations:summary: " {{ $labels.alias }}"description: " Redis连接数超过最大连接数的80%. "value: "{{ $value }}"- alert: Redis linkedexpr: redis_connected_clients / redis_config_maxclients * 100 > 80for: 1mlabels:name: instanceseverity: Warningannotations:summary: " {{ $labels.alias }}"description: " Redis连接数超过最大连接数的80%. "value: "{{ $value }}"
服务停止监控规则
vim rules/service_down.yml- alert: ProcessDownexpr: namedprocess_namegroup_num_procs == 0for: 1mlabels:name: instanceseverity: Criticalannotations:summary: " {{ $labels.appname }}"description: " 进程停止运行 "value: "{{ $value }}"- alert: Grafana downexpr: absent(container_last_seen{name=~"grafana.+"} ) == 1for: 1mlabels:name: grafanaseverity: Criticalannotations:summary: "Grafana"description: "Grafana容器停止运行"value: "{{ $value }}"
6.修改prometheus
global:scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.# scrape_timeout is set to the global default (10s).# Alertmanager configuration
alerting:alertmanagers:- static_configs:- targets:- localhost:9093 #这里默认注释掉,修改成你alertmanagers所在服务器ip # Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:# - "first_rules.yml"# - "second_rules.yml"- " /opt/plg/rules/host_sys.yml" #主机监控规则文件- " /opt/plg/rules/container_sys.yml" #容器监控规则文件- " /opt/plg/rules/redis_check.yml" #redis监控规则文件- " /opt/plg/rules/service_down.yml" #服务停止监控规则
参考文章:https://mp.weixin.qq.com/s/bRZ4u-8aOgadGPbW4jWczQ
这篇关于8.Alertmanager监控报警的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









