本文主要是介绍Java8并行流——Spliterator,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简介
什么是Spliterator
Spliterator是Java8提供的一个新接口,他的作用就是为了将顺序流执行的任务切分成无数个子任务组成的并行流,交给多线程高效完成任务。
需要了解的是,本文并不是告诉你如何使用这个接口,而是会让你通过本文示例了解Spliterator是如何工作的。因为Java8已经为每一个集合框架提供了相应的Spliterator。
工作原理
在介绍Spliterator工作原理之前,我们不妨介绍一下这个接口有哪些需要了解的方法。
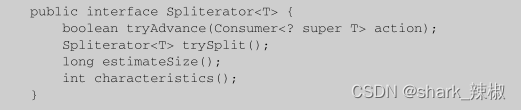
如下图所示,可以看到Spliterator主要的方法就下面,其中tryAdvance是判断当前流是否可以继续切割。trySplit则是真正执行流切割的方法。estimateSize则是估计当前流中还剩下多少个元素,注意我说的是估计因为在并行流的情况下这个数值不是很准确的。
最后一个characteristics,他是告诉开发者这个切割工具的特性,而characteristics特性的编码值如图2所示
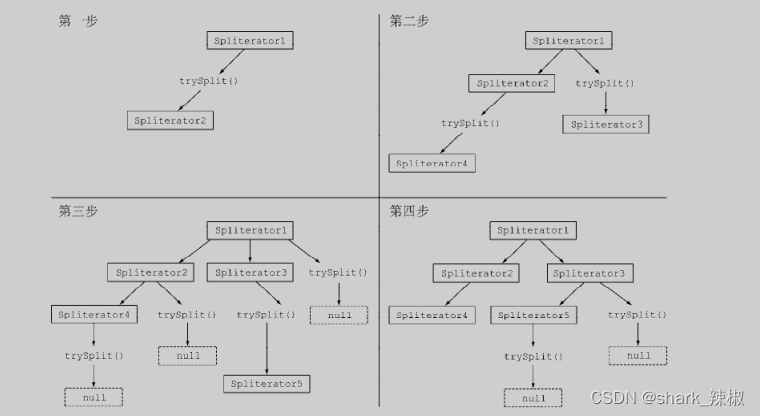
 铺垫完这些内容后,我们就可以了解Spliterator的工作原理了,上文已经说到Spliterator说白了就是为任务并行而设计的,而并行流的任务切分就是通过Spliterator不断递归切割到不可切割,在进行工作最终再合并。
铺垫完这些内容后,我们就可以了解Spliterator的工作原理了,上文已经说到Spliterator说白了就是为任务并行而设计的,而并行流的任务切分就是通过Spliterator不断递归切割到不可切割,在进行工作最终再合并。
如下图所示,第一步的时候,Spliterator拿到的是一个大的任务,Spliterator会调用trySplit试着将任务进行切割。切割成功就得到两个任务。
然后进入第二步,将两个任务分别进行切割,得到四个任务。
第三步我们某些子任务使用trySplit得到null,就说明这个任务不可在进行拆分了。
第四步则是将上一步trySplit不为null的任务再次进行切割,如此往复。当这些切割都完成后,并行流就会将切割后的多个流分配到不同线程的任务队列中不断执行。
示例
需求描述
现在我们就介绍一个需求,我们会给出下文所示的字符串,我们希望你能够统计出这个字符串中有多个单词。
" Nel mezzo del cammin di nostra vita " +
"mi ritrovai in una selva oscura" +
" ché la dritta via era smarrita ";
原始做法
可以看到我们的做法非常简单,默认lastSpace 为true,统计的counter为0,当遇到空格且上一个也为空格时,lastSpace 为true,当遇到一个不是空格且上一个字符是空格的我们的计数器就+1。
public static int countWordsIteratively(String s) {int counter = 0;boolean lastSpace = true;for (char c : s.toCharArray()) {if (Character.isWhitespace(c)) {lastSpace = true;} else {if (lastSpace) counter++;lastSpace = Character.isWhitespace(c);}}return counter;}
我们不妨写一个测试代码看看效果怎么样
首先声明一个字符串
public static String SENTENCE =" Nel mezzo del cammin di nostra vita " +"mi ritrovai in una selva oscura" +" che la dritta via era smarrita ";
测试代码
long start = System.currentTimeMillis();System.out.println("Found " + countWordsIteratively(SENTENCE) + " words");long end = System.currentTimeMillis();System.out.println("执行结束,处理时间为 " + (end - start));
输出结果
Found 19 words
执行结束,处理时间为 15
使用递归的方式实现自定义流收集器实现
很显然上文的代码是很传统的处理逻辑,我们希望能够做的更好,因为Java8为我们提供的函数式编程,所以我们需要写一个自定义收集器去优化这段代码。
我们希望有能够实现这样一个操作,通过将上文的字符串转为一个Character的流,然后通过一个自己编写的流收集器实现流数据的统计,因为是累加,所以我们使用流操作函数如下
<U> U reduce(U identity,BiFunction<U, ? super T, U> accumulator,BinaryOperator<U> combiner);
关于流收集器的原理,可以参考笔者之前写的这篇文章
java8流实战-用流收集数据实践简记
所以我们编写了这样一个单词统计器看起来就是一个流收集器,通过构造方法记录到当前为此有几个单词,以及上一个字符是不是空格。
然后我们又编写了一个accumulate方法,这个方法会对当前传入的字符串进行判断,如果不是空格且上一个字符是空格(即lastSpace为true)则计数器+1。返回一个新的WordCounter 。最后再用combine的将传入的流和自己的流合并起来。
/*** 统计一个字符串中有多少个单词*/
public class WordCounter {/*** 上一个字符是不是空格*/private final boolean lastSpace;/*** 到当前字符位置 有多少个单词*/private final int count;public WordCounter(boolean lastSpace, int count) {this.lastSpace = lastSpace;this.count = count;}public boolean isLastSpace() {return lastSpace;}public int getCount() {return count;}public WordCounter accumulate(Character character) {
// 如果当前字符串不是空格且上一个是空格 则计数器+1if (Character.isWhitespace(character)) {return lastSpace ?this :new WordCounter(true, count);} else {return lastSpace ?new WordCounter(false, count + 1) :this;}}public WordCounter combine(WordCounter wordCounter) {return new WordCounter(lastSpace, wordCounter.getCount() + this.count);}}最终我们就可以使用流编程了
private static Integer countWords(Stream<Character> stream) {return stream.reduce(new WordCounter(true, 0),/*** * BiFunction 为 T,R->U 即可传入T,R返回U* * 对我们来说就是WorkCounter,Charter->WorkCounter* *即传入上个完成工作的wordCounter 以及一个流元素character*/
// ((wordCounter, character) -> wordCounter.accumulate(character)) ,
// 缩写为WordCounter::accumulate,WordCounter::combine).getCount();}
测试代码
start = System.currentTimeMillis();Stream<Character> stream = IntStream.range(0, SENTENCE.length()).mapToObj(SENTENCE::charAt);System.out.println("Found " + countWords(stream) + " words");end = System.currentTimeMillis();System.out.println("执行结束,处理时间为 " + (end - start));
输出结果
Found 19 words
执行结束,处理时间为 14
使用并行流引发的危机
看到上文执行时间为14毫秒,我们希望能够更高效,所以我们将这个流转为并行流
start = System.currentTimeMillis();Stream<Character> stream = IntStream.range(0, SENTENCE.length()).mapToObj(SENTENCE::charAt);System.out.println("Found " + countWords(stream.parallel()) + " words");end = System.currentTimeMillis();System.out.println("执行结束,处理时间为 " + (end - start));
输出结果出错,原因很简单,并行流把某些属于一个单词的字符串切分成两个,例如我们的字符串是Nel mezzo del cammin di nostra vita ,有7个单词。经过并行流处理后的字符串为N el me zzo del cam min di no stra vita 共11个单词。
Found 35 words
执行结束,处理时间为 13
自己造轮子,实现一个Spliterator
所以我们需要一个手写一个自定义的流切割器进行流切割,因为我们要对Character流进行切割,所以继承了Spliterator<Character>,首先是tryAdvance方法,这个方法就是判断当前流是否能够切割,所以我们方法当前传入的字符串的索引位置是否超过字符串长度即可。
tryAdvance则是字符流的具体切割逻辑了,代码很简单,使用当传入的字符串小于10就返回null,说明这个流不能在进行递归切割了。反之就是不断遍历字符串位置,遇到空格就将字符串进行切割。
estimateSize则是返回当前流之后还剩多少元素,可以看到我们在tryAdvance返回Spliterator前设置了currentChar = spliteIdx;。这样就保证了estimateSize就能精确精算这个流切割后还剩多少字符串。
characteristics则是说明当前流的特性,ORDERED 即有序,SIZED 即传入的流大小固定, 决定estimateSize计算的大小是正确的。流元素非空。SUBSIZED同理,他决定切割出来的流元素大小固定,计算的estimateSize也是固定值。NONNULL 决定每个流元素非空。IMMUTABLE则说明这个流不能进行添加或者删除等操作。
public class WordCounterSpliterator implements Spliterator<Character> {private int currentChar = 0;private String string;public WordCounterSpliterator(String string) {this.string = string;}@Overridepublic boolean tryAdvance(Consumer<? super Character> action) {action.accept(string.charAt(currentChar++));//如果当前索引位置小于字符串长度,则可以继续切割return currentChar < string.length();}@Overridepublic Spliterator<Character> trySplit() {int length = string.length() - currentChar;
// 小于10个字符就不要切割了,直接返回nullif (length < 10) {return null;}for (int i = currentChar; i < length; i++) {/*** 我们希望出现空格后,切割出一个左闭右开的区间* 例如我们的char数组为[0,1,2,3,4,5]* 我们希望最后得到的数组是[0,1,2]* 所以我们最后subString结果为(0,3]*/int spliteIdx = currentChar + length / 2;if (Character.isWhitespace(string.charAt(spliteIdx))) {WordCounterSpliterator spliterator = new WordCounterSpliterator(string.substring(currentChar, spliteIdx));currentChar = spliteIdx;return spliterator;}}return null;}@Overridepublic long estimateSize() {return string.length() - currentChar;}@Overridepublic int characteristics() {return ORDERED + SIZED + SUBSIZED + NONNULL + IMMUTABLE;}
}
测试最终结果
start = System.currentTimeMillis();WordCounterSpliterator spliterator = new WordCounterSpliterator(SENTENCE);Stream<Character> parallelStream = StreamSupport.stream(spliterator, true);System.out.println("Found " + countWords(parallelStream) + " words");end = System.currentTimeMillis();System.out.println("执行结束,处理时间为 " + (end - start));
输出结果,可以看到既保证了效率又精确计算出结果
Found 19 words
执行结束,处理时间为 1
注意事项
可能看到这里你会认为我们后续遇到这种情况,无脑diy流切割器然后交给自定义流收集器性能就会变得很强对吧?
错,我们不妨将刚刚操作的字符串长度增加
for (int i = 0; i < 20; i++) {SENTENCE += SENTENCE;}
再使用上文的测试代码进行测试,可以看到使用自定义流切割器的代码执行了532,效率低了很多。原因很简单,笔者电脑是6核,上文中我们的字符串小于10时才停止切割,这次我们传入大长度的字符串导致切割线程过多,6个核心并行执行大量线程在进行组装,这些时间都足以顺序执行的线程跑完所有任务了,所以笔者建议,在非必要情况下还是使用jdk自带的并行流api即可。
//顺序执行输出结果
114294784
Found 19922944 words
//自定义流收集器用并行流执行结果
执行结束,处理时间为 312
Found 19922950 words
执行结束,处理时间为 296
//自定义流切割器以及自定义流收集器执行结果
Found 19922944 words
执行结束,处理时间为 532
源码地址
https://github.com/shark-ctrl/Java8InAction
参考文献
Java 8实战
这篇关于Java8并行流——Spliterator的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





