本文主要是介绍python获取处理自然保护区属性数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
写在前面
[本文只用于python技术交流,不作任何其它延伸用途,数据下载后仅做科学研究,服务国家自然保护区科学研究工作,数据不外泄不传播,保障国家数据安全,人人有责。]
作者:海岸云鹤
中国自然保护区标本资源共享平台内的地理信息库有3398个保护区数据,保护区类型多样,级别分为国家级、省级、市级,二级详情页有编号、级别、类型、行政区域等详细信息,大部分保护区有kmz空间范围数据下载后可在QGIS中打开(图1-4)。
任务目标
批量下载中国各省份、各级别、所有类型的自然保护区二级详情页的属性数据,如有kmz空间范围数据一并下载。
网址:地理信息库 - 中国自然保护区生物标本资源共享平台![]() http://www.papc.cn/html/folder/946895-1.htm
http://www.papc.cn/html/folder/946895-1.htm
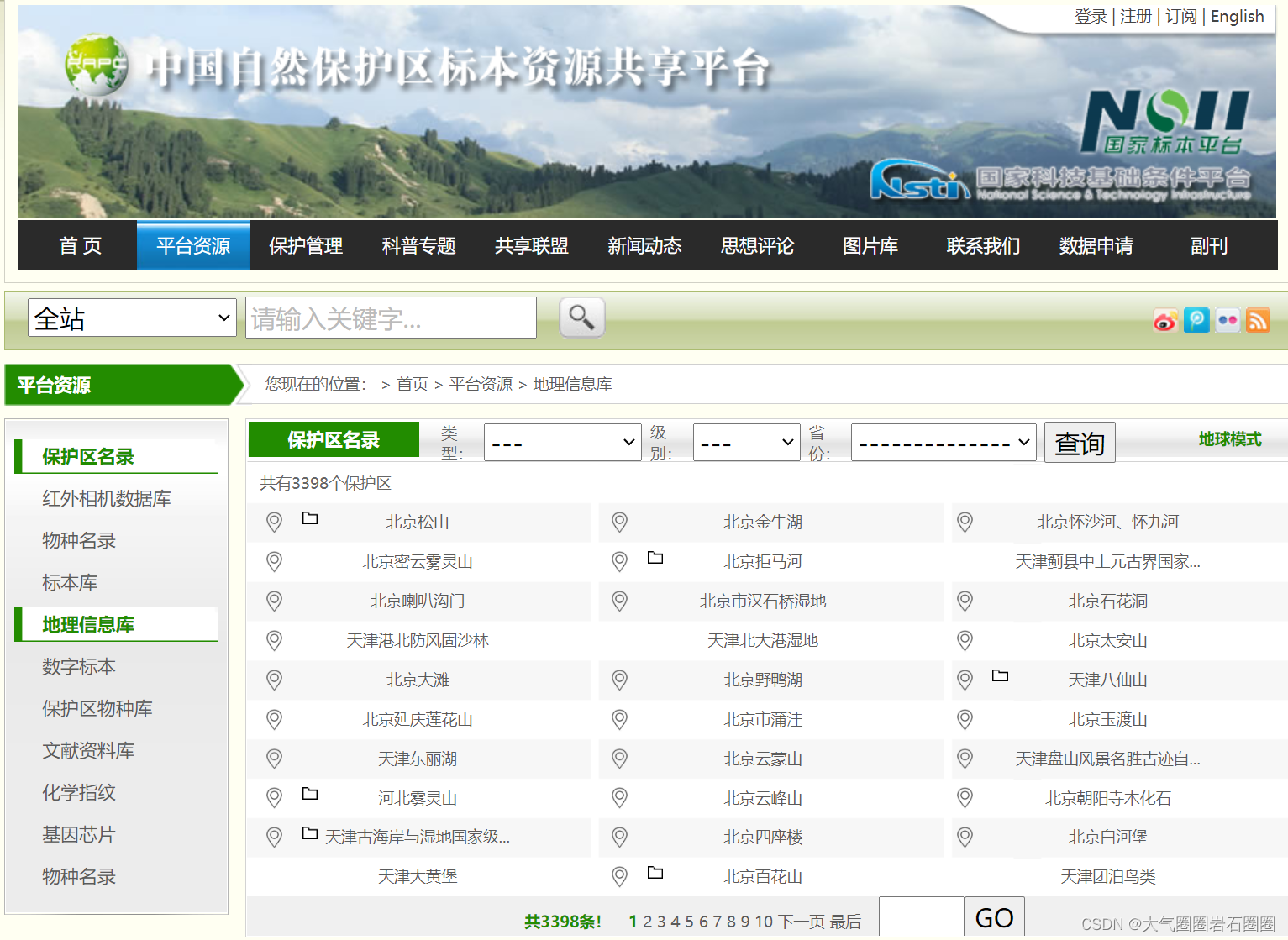
图1
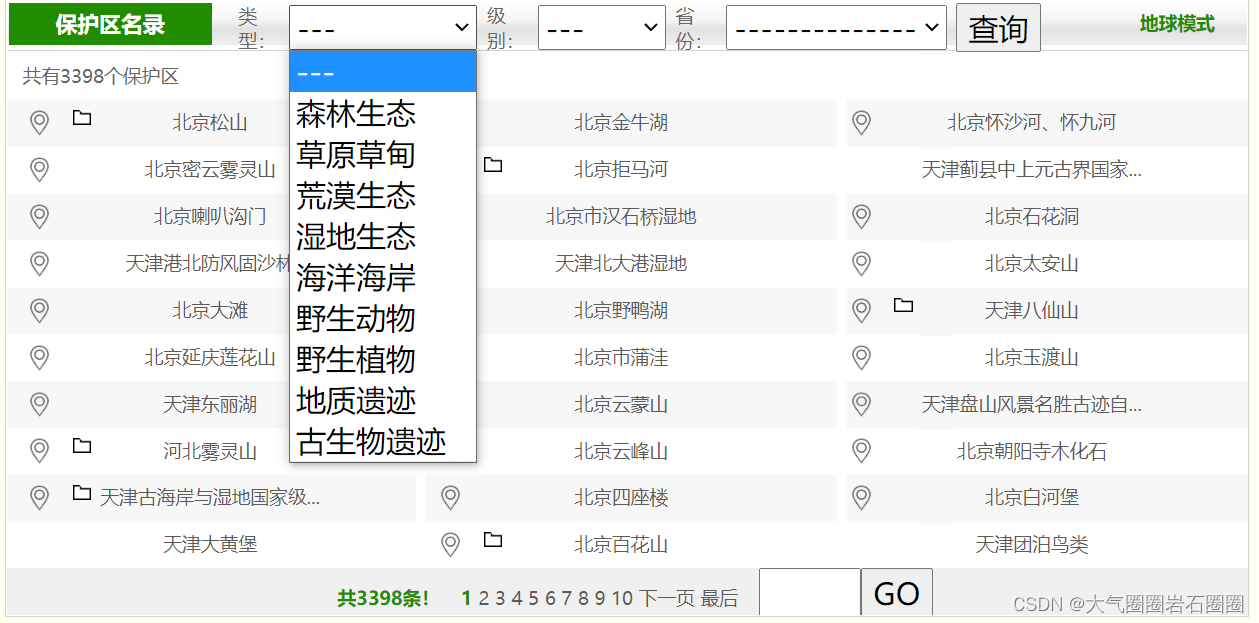
图2
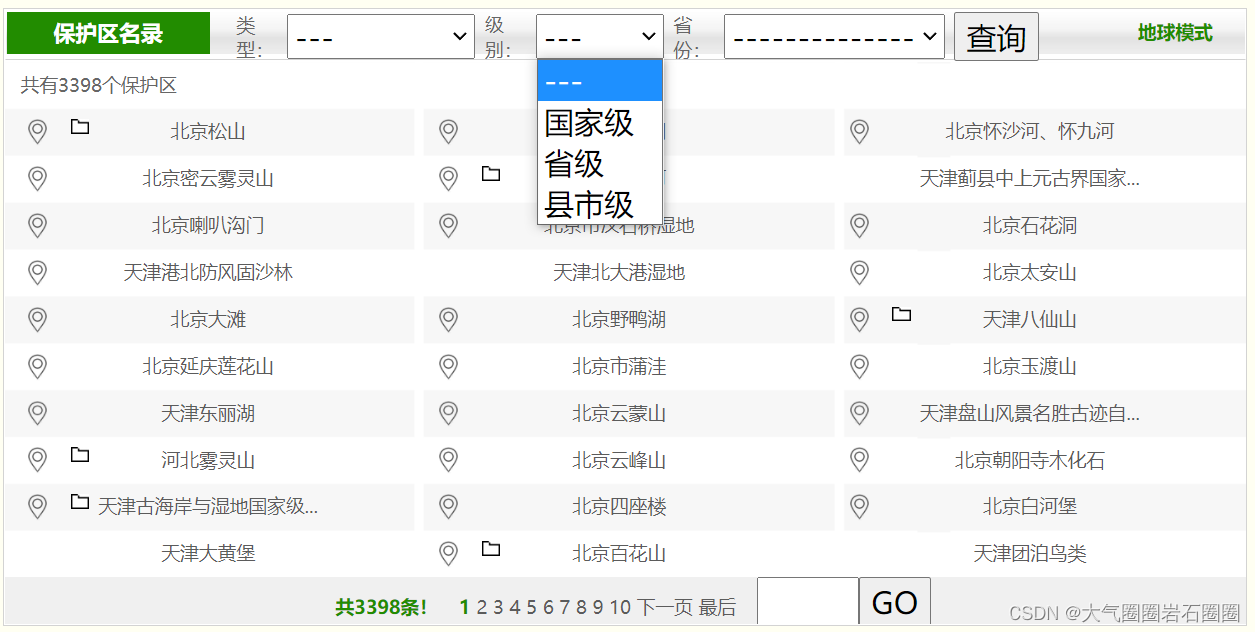
图3
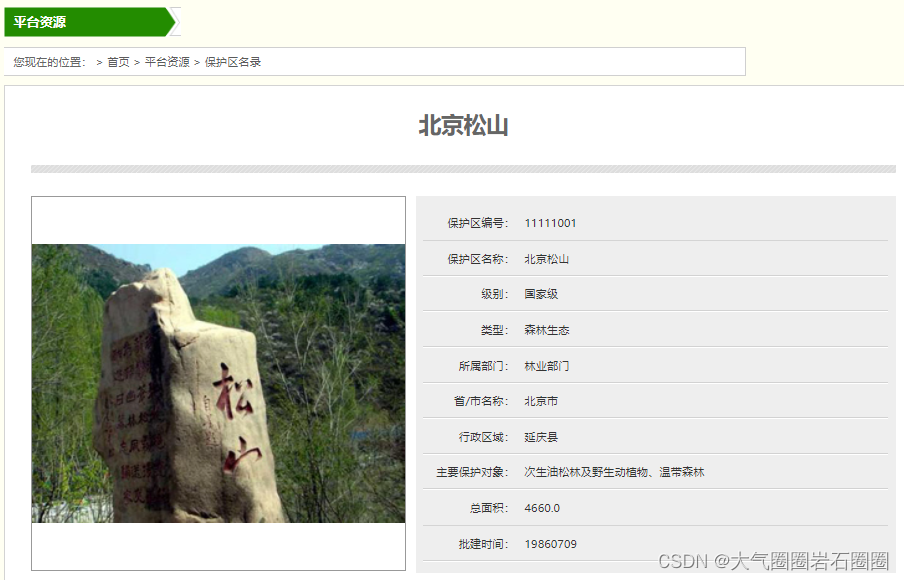
图4
编写代码
通过大量详细解析网页结构、构建爬取规则,编写以下代码进行爬取
#coding:utf-8
import requests
import json
import numpy as np
import pandas as pd
import bs4
import csv
import re
import math# 获取相应数据
def open_url(url,data2):#设置请求头 输入自己的headersheaders = {"Cookie":XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX,
# "Content-Type":"application/x-www-form-urlencoded","User-Agent": SSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSS}response=requests.post(url,headers=headers,data=data2, timeout=(3,7))#time为设置间隔时间,保证网页有相应的反应时间,保障连接res = response.textreturn res
# 获取相应数据def findReserveI(res):df = pd.DataFrame(columns = ["ReserveID", "Reserve_name", "Reserve_IDlevel", "Reserve_IDtype",'Reserve_IDdept','Reserve_IDcity','Reserve_IDadminarea','Reserve_IDprotect','Reserve_IDarea','Reserve_IDyears'])soup = bs4.BeautifulSoup(res,'lxml')#html.parsertargets =soup.find_all(id='19')#寻找存放网址的地方
# print (targets)for each in targets:# print(each)# reserve_name= each.get_text()web_number=str(each['href']).split('/')[-1][:-6]#得到每个保护区的网站编号# print(web_number)url2='http://www.papc.cn/html/reserve/'+web_number+'-1.htm#p=1'#构建每个保护区详情页网址,用于获取完整的自然保护区名称,后续进行详情提取# print(url2)headers = {"Cookie":XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX,"User-Agent":SSSSSSSSSSSSSSSSSSSSSSSSSSSSSSSS}response2=requests.get(url2,headers=headers, timeout=(3,7))res2=response2.textif '该页不存在' in res2:Reserve_name= each.get_text()dicts = [{ "Reserve_name":Reserve_name}]df=df.append(dicts, ignore_index=True, sort=False)continueelse:soup2 = bs4.BeautifulSoup(res2,'lxml')targets2 =soup2.find_all(id="ReserveIDcode")# print(targets2)for each2 in targets2:ReserveID=each2.get_text().strip()# print(ReserveID)targets3=soup2.find_all(id="ReserveIDsubject")# print(targets3)for each3 in targets3:Reserve_name=each3.get_text().strip()print(Reserve_name)targets4=soup2.find_all(id="ReserveIDlevel")# print(targets4)for each4 in targets4:Reserve_IDlevel=each4.get_text().strip()# print(Reserve_IDlevel)targets5=soup2.find_all(id="ReserveIDtype")# print(targets5)for each5 in targets5:Reserve_IDtype=each5.get_text().strip()# print(Reserve_IDtype)targets6=soup2.find_all(id="ReserveIDdept")# print(targets6)for each6 in targets6:Reserve_IDdept=each6.get_text().strip()# print(Reserve_IDdept)targets7=soup2.find_all(id="ReserveIDcity")# print(targets7)for each7 in targets7:Reserve_IDcity=each7.get_text().strip()# print(Reserve_IDcity)targets8=soup2.find_all(id="ReserveIDadminarea")# print(targets8)for each8 in targets8:Reserve_IDadminarea=each8.get_text().strip()# print(Reserve_IDadminarea)targets9=soup2.find_all(id="ReserveIDprotect")# print(targets9)for each9 in targets9:Reserve_IDprotect=each9.get_text().strip()# print(Reserve_IDprotect)targets10=soup2.find_all(id="ReserveIDarea")# print(targets10)for each10 in targets10:Reserve_IDarea=each10.get_text().strip()# print(Reserve_IDarea)targets11=soup2.find_all(id="ReserveIDyears")# print(targets11)for each11 in targets11:Reserve_IDyears=each11.get_text().strip()# print(Reserve_IDyears)dicts = [{"ReserveID":ReserveID, "Reserve_name":Reserve_name, "Reserve_IDlevel":Reserve_IDlevel, "Reserve_IDtype":Reserve_IDtype,'Reserve_IDdept':Reserve_IDdept,'Reserve_IDcity':Reserve_IDcity,'Reserve_IDadminarea':Reserve_IDadminarea,'Reserve_IDprotect':Reserve_IDprotect,'Reserve_IDarea':Reserve_IDarea,'Reserve_IDyears': Reserve_IDyears}]print(dicts)df=df.append(dicts, ignore_index=True, sort=False)dfreturn dfdef find_depth(res):soup = bs4.BeautifulSoup(res,'lxml')#html.parserNumbers=soup.find_all(id="PageNum")
# print(Numbers)i=0for num in Numbers:Pagenum=num.get_text()# print(Pagenum)a = re.findall("\d+\.?\d*", Pagenum)sum_number=a[0]i=i+1if i ==1:breakprint(sum_number) if int(sum_number)>30:yeshu =math.ceil(int(sum_number) /30)else:yeshu=1return int(yeshu)def request_data(node,level,city):data2 = {'type':node,"level":level,'city':city}#定义Post请求数据return data2def main():host="http://www.papc.cn/html/folder/946895-1.htm" #数据存放的网址'df2 = pd.DataFrame(columns = ["ReserveID", "Reserve_name", "Reserve_IDlevel", "Reserve_IDtype",'Reserve_IDdept','Reserve_IDcity','Reserve_IDadminarea','Reserve_IDprotect','Reserve_IDarea','Reserve_IDyears'])city=[[11,'BeiJing','北京'],[12,'TianJin','天津'],[13,'HeBei','河北'],[14,'ShanXi','山西'],[15,'NeiMengGu','内蒙古'],[21,'LiaoNing','辽宁'],[22,'JiLin','吉林'],[23,'HeiLongJiang','黑龙江'],[31,'ShangHai','上海'],[32,'JiangSu','江苏'],[33,'ZheJiang','浙江'],[34,'AnHui','安徽'],[35,'FuJian','福建'],[36,'JiangXi','江西'],[37,'ShanDong','山东'],[41,'HeNan','河南'],[42,'HuBei','湖北'],[43,'HuNan','湖南'],[44,'GuangDong','广东'],[45,'GuangXi','广西'],[46,'HaiNan','海南'],[50,'ZhongQing','重庆'],[51,'SiChuan','四川'],[52,'GuiZhou','贵州'],[53,'YunNan','云南'],[54,'XiCang','西藏'],[61,'ShanXi','陕西'],[62,'GanSu','甘肃'],[63,'QingHai','青海'],[64,'NingXia','宁夏'],[65,'XinJiang','新疆'],[71,'TaiWan','台湾'],[81,'XiangGang','香港'],[82,'AoMen','澳门']]for ci in city:node=0level=1city=int(ci[0]) data2=request_data(node,level,city)res=open_url(host,data2)depth =find_depth(res)a=-1for de in range(depth):a=a+1if a<1:url=hostdf2=df2.append(findReserveI(res), ignore_index=True, sort=False)else:pos=a*30url ='http://www.papc.cn/html/folder/946895-1.htm?node={}&city={}&level={}&pos={}'.format(node,city,level,pos)res=open_url(url,data2)df2=df2.append(findReserveI(res),ignore_index=True, sort=False) print(df2)df2.to_csv('K:/searchdata/保护区kmz/excel/国家级自然保护区new.csv',index=0, na_rep='NA',encoding='utf-8-sig') #不保存行索引print('保存完毕!!!')成功运行
这篇关于python获取处理自然保护区属性数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





