本文主要是介绍基于Tensorflow2.x的MobileNet的病虫害分类(有界面),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文档资源:
基于Tensorflow2.x的ResNet-50的病虫害分类讲解(有界面):
基于Tensorflow2.x的CNN的病虫害分类j讲解(有界面)讲解:(39条消息) 基于Tensorflow2.x的CNN的病虫害分类(有界面)_天道酬勤者的博客-CSDN博客
基于Tensorflow2.x的MobileNet的病虫害分类(有界面)讲解:
(41条消息) 基于Tensorflow2.x的MobileNet的病虫害分类(有界面)_songyang66的博客-CSDN博客
基于Tensorflow2.x的ResNet的病虫害分类(有界面)文件下载:
基于Tensorflow2.x的CNN的病虫害分类(有界面)文件下载:(41条消息) 基于Tensorflow2.x的CNN的病虫害分类(有界面)-深度学习文档类资源-CSDN文库
基于Tensorflow2.x的mobilenet的病虫害分类(有界面)文件下载:(41条消息) 基于Tensorflow2.x的mobilenet的病虫害分类(有界面)-深度学习文档类资源-CSDN文库

datasort.py用于对数据集图片进行排序重命名,代码如下:
import osclass BatchRename():def __init__(self):self.path = "B:/BaiduNetdiskDownload/class/testing_data/Leaf-ulcer" #图片的路径def rename(self):filelist = os.listdir(self.path) filelist.sort()total_num = len(filelist)i = 0for item in filelist:item = item.lower() if item.endswith('.png'):src = os.path.join(self.path, item)s = str(i)s = s.zfill(2) #Python zfill() 方法返回指定长度的字符串,原字符串右对齐,前面填充0dst = os.path.join(os.path.abspath(self.path), s + '.png')'''概述:os.rename() 方法用于重命名文件或目录,从 src 到 dst,如果dst是一个存在的目录, 将抛出OSError语法:rename()方法语法格式如下:os.rename(src, dst)参数:src 要修改的目录名dst 修改后的目录名返回值:该方法没有返回值'''try:os.rename(src, dst)print ('converting %s to %s ...' % (src, dst))i = i + 1except Exception as e:print(e)print('rename dir fail\r\n')print ('total %d to rename & converted %d jpgs' % (total_num, i))if __name__ == '__main__':demo = BatchRename()demo.rename()
datasort.py效果如下:

data_progress.py用于对数据集进行分类,具体代码如下:
import os
import random
from shutil import copy2def data_set_split(initial_data_folder, target_data_folder, train_scale=0.8, val_scale=0.2, test_scale=0.0):'''读取源数据文件夹,生成划分好的文件夹,分为trian、val、test三个文件夹进行:param initial_data_folder: 源文件夹 E:/biye/gogogo/note_book/torch_note/data/utils_test/data_split/initial_data:param target_data_folder: 目标文件夹 E:/biye/gogogo/note_book/torch_note/data/utils_test/data_split/target_data:param train_scale: 训练集比例:param val_scale: 验证集比例:param test_scale: 测试集比例:return:'''print("开始数据集划分")class_names = os.listdir(initial_data_folder)#用于返回initial_data_folder文件夹包含的图片文件的名字的列表# 在目标目录下创建文件夹split_names = ['train', 'val', 'test']for split_name in split_names:split_path = os.path.join(target_data_folder, split_name)if os.path.isdir(split_path): #os.path.isdir()函数判断某一路径是否为目录 passelse:os.mkdir(split_path) #os.mkdir()函数创建目录(创建一级目录),其参数path 为要创建目录的路径 拓展:使用os.rmdir()函数删除目录。# 然后在split_path的目录下创建类别文件夹,生成Fruit-anthrax等五个文件夹for class_name in class_names:class_split_path = os.path.join(split_path, class_name)if os.path.isdir(class_split_path):passelse:os.mkdir(class_split_path)# 按照比例划分数据集,并进行数据图片的复制# 首先进行分类遍历for class_name in class_names:current_class_data_path = os.path.join(initial_data_folder, class_name)current_all_data = os.listdir(current_class_data_path)#用于返回current_class_data_path文件夹包含的图片文件的名字的列表current_data_length = len(current_all_data)current_data_index_list = list(range(current_data_length))random.shuffle(current_data_index_list)train_folder = os.path.join(os.path.join(target_data_folder, 'train'), class_name)val_folder = os.path.join(os.path.join(target_data_folder, 'val'), class_name)test_folder = os.path.join(os.path.join(target_data_folder, 'test'), class_name)train_stop_flag = current_data_length * train_scaleval_stop_flag = current_data_length * (train_scale + val_scale)current_idx = 0train_num = 0val_num = 0test_num = 0for i in current_data_index_list:initial_img_path = os.path.join(current_class_data_path, current_all_data[i])if current_idx <= train_stop_flag:copy2(initial_img_path, train_folder)train_num = train_num + 1elif (current_idx > train_stop_flag) and (current_idx <= val_stop_flag):copy2(initial_img_path, val_folder)val_num = val_num + 1else:copy2(initial_img_path, test_folder)test_num = test_num + 1current_idx = current_idx + 1print("*********************************{}*************************************".format(class_name))print("{}类按照{}:{}:{}的比例划分完成,一共{}张图片".format(class_name, train_scale, val_scale, test_scale, current_data_length))print("训练集{}:{}张".format(train_folder, train_num))print("验证集{}:{}张".format(val_folder, val_num))print("测试集{}:{}张".format(test_folder, test_num))if __name__ == '__main__':initial_data_folder = "training_data" # 原始数据集路径target_data_folder = "split_data" # 目标存放的路径data_set_split(initial_data_folder, target_data_folder)data_progress.py效果展示:

train_cnn.py用于训练cnn网络
import tensorflow as tf
import matplotlib.pyplot as plt
from time import *# 数据集加载函数,指明数据集的位置并统一处理为imgheight*imgwidth的大小,同时设置batch
def data_load(data_dir, test_data_dir, img_height, img_width, batch_size):# 加载训练集train_ds = tf.keras.preprocessing.image_dataset_from_directory(data_dir,label_mode='categorical',seed=123,image_size=(img_height, img_width),batch_size=batch_size)# 加载测试集val_ds = tf.keras.preprocessing.image_dataset_from_directory(test_data_dir,label_mode='categorical',seed=123,image_size=(img_height, img_width),batch_size=batch_size)class_names = train_ds.class_names# 返回处理之后的训练集、验证集和类名return train_ds, val_ds, class_names# 构建mobilenet模型
# 模型加载,指定图片处理的大小和是否进行迁移学习
def model_load(IMG_SHAPE=(224, 224, 3), class_num=5):# 微调的过程中不需要进行归一化的处理# 加载预训练的mobilenet模型base_model = tf.keras.applications.MobileNetV2(input_shape=IMG_SHAPE,include_top=False,weights='imagenet')# 将模型的主干参数进行冻结base_model.trainable = Falsemodel = tf.keras.models.Sequential([# 进行归一化的处理tf.keras.layers.experimental.preprocessing.Rescaling(1. / 127.5, offset=-1, input_shape=IMG_SHAPE),# 设置主干模型base_model,# 对主干模型的输出进行全局平均池化tf.keras.layers.GlobalAveragePooling2D(),# 通过全连接层映射到最后的分类数目上tf.keras.layers.Dense(class_num, activation='softmax')])model.summary()# 模型训练的优化器为adam优化器,模型的损失函数为交叉熵损失函数model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])return model# 展示训练过程的曲线
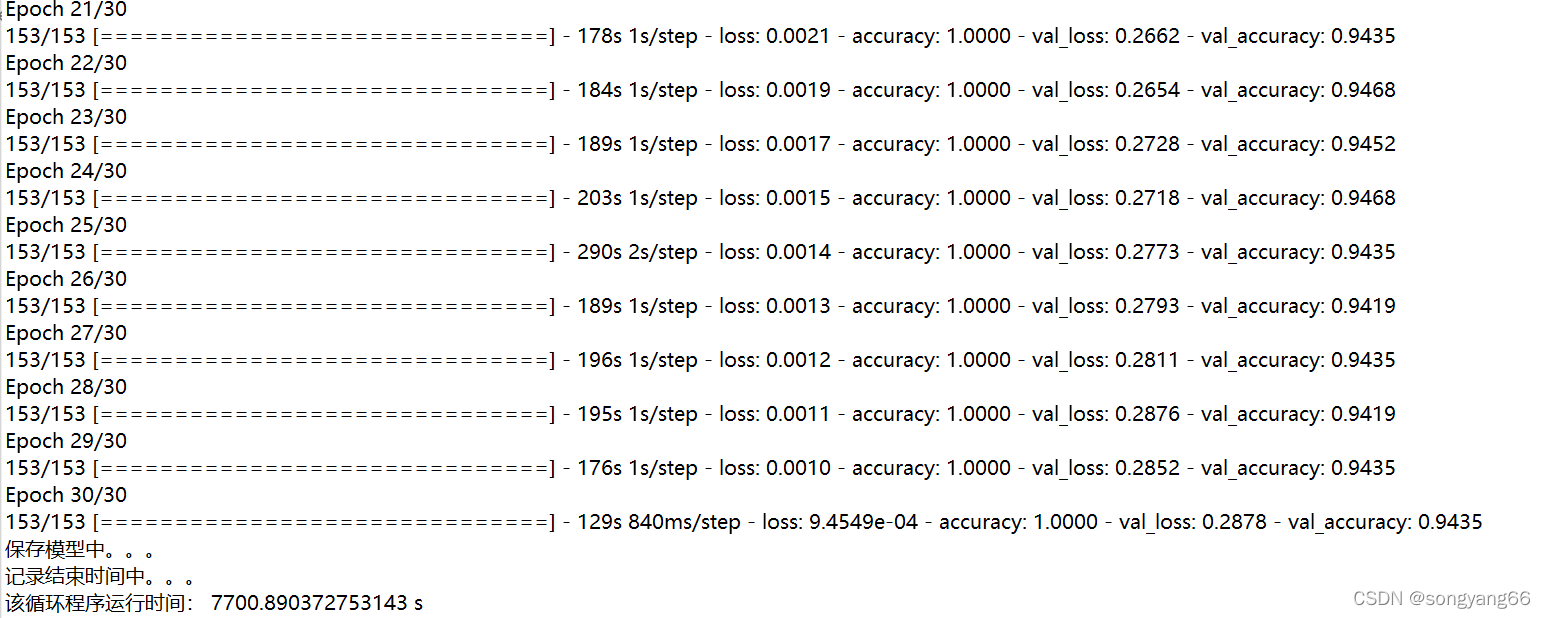
def show_loss_acc(history):# 从history中提取模型训练集和验证集准确率信息和误差信息acc = history.history['accuracy']val_acc = history.history['val_accuracy']loss = history.history['loss']val_loss = history.history['val_loss']# 按照上下结构将图画输出plt.figure(figsize=(8, 8))plt.subplot(2, 1, 1)plt.plot(acc, label='Training Accuracy')plt.plot(val_acc, label='Validation Accuracy')plt.legend(loc='lower right')plt.ylabel('Accuracy')plt.ylim([min(plt.ylim()), 1])plt.title('Training and Validation Accuracy')plt.subplot(2, 1, 2)plt.plot(loss, label='Training Loss')plt.plot(val_loss, label='Validation Loss')plt.legend(loc='upper right')plt.ylabel('Cross Entropy')plt.title('Training and Validation Loss')plt.xlabel('epoch')plt.savefig('results/results_mobilenet.png', dpi=100)plt.show()def train(epochs):print("开始训练,记录开始时间。。。")# 开始训练,记录开始时间begin_time = time()# todo 加载数据集, 修改为你的数据集的路径print("加载数据集中。。。")train_ds, val_ds, class_names = data_load("split_data/train","split_data/val", 224, 224, 16)print(class_names)print("加载模型中。。。")# 加载模型model = model_load(class_num=len(class_names))# 指明训练的轮数epoch,开始训练print("指明训练的轮数epoch,开始训练中。。。")history = model.fit(train_ds, validation_data=val_ds, epochs=epochs)# todo 保存模型, 修改为你要保存的模型的名称print("保存模型中。。。")model.save("results/mobilenet_orange.h5")print("记录结束时间中。。。")# 记录结束时间end_time = time()run_time = end_time - begin_timeprint('该循环程序运行时间:', run_time, "s") # 该循环程序运行时间: 1.4201874732# 绘制模型训练过程图show_loss_acc(history)if __name__ == '__main__':train(epochs=30)train_cnn.py训练结果:
model_test.py用于用测试集图片对cnn模型进行预测,并观察准确率
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
#测试之后在命令行中会输出每个模型的准确率,并且会在results目录下生成相应的热力图
plt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['font.sans-serif'] = ['SimHei']# 数据加载,分别从训练的数据集的文件夹和测试的文件夹中加载训练集和验证集
def data_load(test_data_dir, img_height, img_width, batch_size):# 加载测试集test_ds = tf.keras.preprocessing.image_dataset_from_directory(test_data_dir,label_mode='categorical',seed=123,image_size=(img_height, img_width),batch_size=batch_size)class_names = test_ds.class_names# 返回处理之后的训练集、验证集和类名return test_ds, class_names# 测试mobilenet准确率
def test_mobilenet():# todo 加载数据, 修改为你自己的数据集的路径test_ds, class_names = data_load("B:\\class\\testing_data", 224, 224, 16)# todo 加载模型,修改为你的模型名称model = tf.keras.models.load_model("results/mobilenet_orange.h5")# model.summary()# 测试loss, accuracy = model.evaluate(test_ds)# 输出结果print('Mobilenet test accuracy :', accuracy)test_real_labels = []test_pre_labels = []for test_batch_images, test_batch_labels in test_ds:test_batch_labels = test_batch_labels.numpy()test_batch_pres = model.predict(test_batch_images)# print(test_batch_pres)test_batch_labels_max = np.argmax(test_batch_labels, axis=1)test_batch_pres_max = np.argmax(test_batch_pres, axis=1)# print(test_batch_labels_max)# print(test_batch_pres_max)# 将推理对应的标签取出for i in test_batch_labels_max:test_real_labels.append(i)for i in test_batch_pres_max:test_pre_labels.append(i)# break# print(test_real_labels)# print(test_pre_labels)class_names_length = len(class_names)heat_maps = np.zeros((class_names_length, class_names_length))for test_real_label, test_pre_label in zip(test_real_labels, test_pre_labels):heat_maps[test_real_label][test_pre_label] = heat_maps[test_real_label][test_pre_label] + 1print(heat_maps)heat_maps_sum = np.sum(heat_maps, axis=1).reshape(-1, 1)# print(heat_maps_sum)print()heat_maps_float = heat_maps / heat_maps_sumprint(heat_maps_float)# title, x_labels, y_labels, harvestshow_heatmaps(title="heatmap", x_labels=class_names, y_labels=class_names, harvest=heat_maps_float,save_name="results/heatmap_mobilenet.png")def show_heatmaps(title, x_labels, y_labels, harvest, save_name):# 这里是创建一个画布fig, ax = plt.subplots()# cmap https://blog.csdn.net/ztf312/article/details/102474190im = ax.imshow(harvest, cmap="OrRd")# 这里是修改标签# We want to show all ticks...ax.set_xticks(np.arange(len(y_labels)))ax.set_yticks(np.arange(len(x_labels)))# ... and label them with the respective list entriesax.set_xticklabels(y_labels)ax.set_yticklabels(x_labels)# 因为x轴的标签太长了,需要旋转一下,更加好看# Rotate the tick labels and set their alignment.plt.setp(ax.get_xticklabels(), rotation=45, ha="right",rotation_mode="anchor")# 添加每个热力块的具体数值# Loop over data dimensions and create text annotations.for i in range(len(x_labels)):for j in range(len(y_labels)):text = ax.text(j, i, round(harvest[i, j], 2),ha="center", va="center", color="black")ax.set_xlabel("Predict label")ax.set_ylabel("Actual label")ax.set_title(title)fig.tight_layout()plt.colorbar(im)plt.savefig(save_name, dpi=100)plt.show()if __name__ == '__main__':test_mobilenet()model_test.py用于用测试集图片对cnn模型进行预测,并观察准确率

design.py用于测试界面
import tensorflow as tf
from PyQt5.QtGui import *
from PyQt5.QtCore import *
from PyQt5.QtWidgets import *
import sys
import cv2
from PIL import Image
import numpy as np
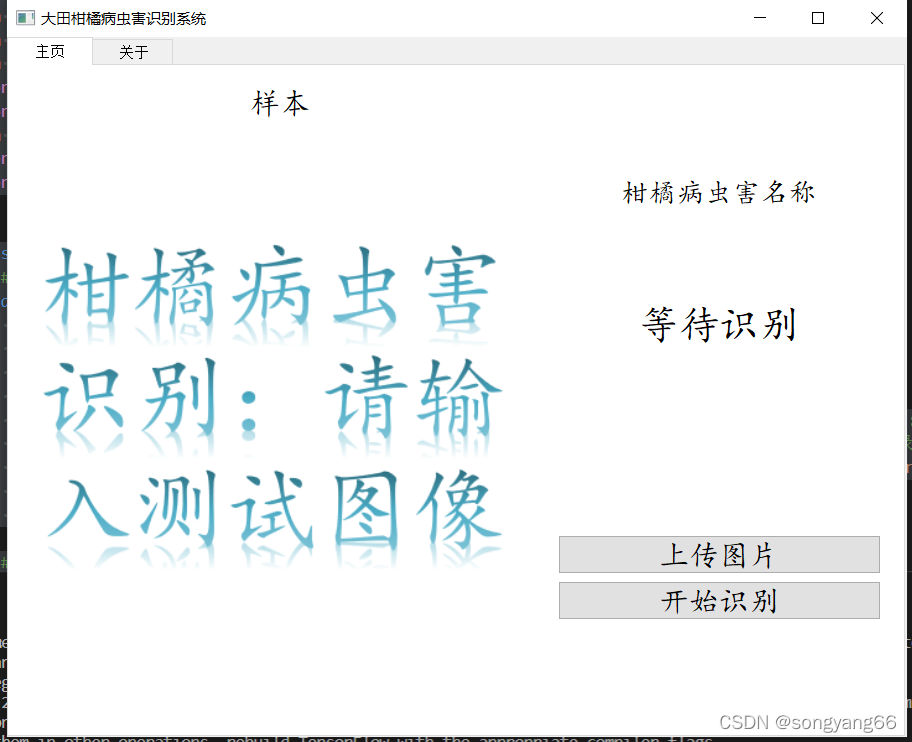
import shutilclass MainWindow(QTabWidget):# 初始化def __init__(self):super().__init__()self.setWindowIcon(QIcon('images/logo.png'))self.setWindowTitle('大田柑橘病虫害识别系统') # todo 修改系统名称# 模型初始化self.model = tf.keras.models.load_model("results/mobilenet_orange.h5") # todo 修改模型名称:cnn_orange.h5、mobilenet_orange.h5、resnet_orange.h5self.to_predict_name = "images/background.jpg" # todo 修改初始图片,这个图片要放在images目录下self.class_names = ['Fruit-anthrax', 'Fruit-ulcer', 'Leaf-anthrax','Leaf-ulcer', 'leaf_thyroid'] # todo 修改类名,这个数组在模型训练的开始会输出self.resize(900, 700)self.initUI()# 界面初始化,设置界面布局def initUI(self):main_widget = QWidget()main_layout = QHBoxLayout()font = QFont('楷体', 18)# 主页面,设置组件并在组件放在布局上left_widget = QWidget()left_layout = QVBoxLayout()img_title = QLabel("样本")img_title.setFont(font)img_title.setAlignment(Qt.AlignCenter)self.img_label = QLabel()img_init = cv2.imread(self.to_predict_name)h, w, c = img_init.shapescale = 400 / himg_show = cv2.resize(img_init, (0, 0), fx=scale, fy=scale)cv2.imwrite("images/show.png", img_show)img_init = cv2.resize(img_init, (224, 224))cv2.imwrite('images/target.png', img_init)self.img_label.setPixmap(QPixmap("images/show.png"))left_layout.addWidget(img_title)left_layout.addWidget(self.img_label, 1, Qt.AlignCenter)left_widget.setLayout(left_layout)right_widget = QWidget()right_layout = QVBoxLayout()btn_change = QPushButton(" 上传图片 ")btn_change.clicked.connect(self.change_img)btn_change.setFont(font)btn_predict = QPushButton(" 开始识别 ")btn_predict.setFont(font)btn_predict.clicked.connect(self.predict_img)label_result = QLabel(' 柑橘病虫害名称 ')self.result = QLabel("等待识别")label_result.setFont(QFont('楷体', 16))self.result.setFont(QFont('楷体', 24))right_layout.addStretch()right_layout.addWidget(label_result, 0, Qt.AlignCenter)right_layout.addStretch()right_layout.addWidget(self.result, 0, Qt.AlignCenter)right_layout.addStretch()right_layout.addStretch()right_layout.addWidget(btn_change)right_layout.addWidget(btn_predict)right_layout.addStretch()right_widget.setLayout(right_layout)main_layout.addWidget(left_widget)main_layout.addWidget(right_widget)main_widget.setLayout(main_layout)# 关于页面,设置组件并把组件放在布局上about_widget = QWidget()about_layout = QVBoxLayout()about_title = QLabel('欢迎使用柑橘病虫害识别系统') # todo 修改欢迎词语about_title.setFont(QFont('楷体', 18))about_title.setAlignment(Qt.AlignCenter)about_img = QLabel()about_img.setPixmap(QPixmap('images/bj.jpg'))about_img.setAlignment(Qt.AlignCenter)label_super = QLabel("作者:宋扬") # todo 更换作者信息label_super.setFont(QFont('楷体', 15))# label_super.setOpenExternalLinks(True)label_super.setAlignment(Qt.AlignRight)about_layout.addWidget(about_title)about_layout.addStretch()about_layout.addWidget(about_img)about_layout.addStretch()about_layout.addWidget(label_super)about_widget.setLayout(about_layout)# 添加注释self.addTab(main_widget, '主页')self.addTab(about_widget, '关于')self.setTabIcon(0, QIcon('images/主页面.png'))self.setTabIcon(1, QIcon('images/关于.png'))# 上传并显示图片def change_img(self):openfile_name = QFileDialog.getOpenFileName(self, 'chose files', '','Image files(*.jpg *.png *jpeg)') # 打开文件选择框选择文件img_name = openfile_name[0] # 获取图片名称if img_name == '':passelse:target_image_name = "images/tmp_up." + img_name.split(".")[-1] # 将图片移动到当前目录shutil.copy(img_name, target_image_name)self.to_predict_name = target_image_nameimg_init = cv2.imread(self.to_predict_name) # 打开图片h, w, c = img_init.shapescale = 400 / himg_show = cv2.resize(img_init, (0, 0), fx=scale, fy=scale) # 将图片的大小统一调整到400的高,方便界面显示cv2.imwrite("images/show.png", img_show)img_init = cv2.resize(img_init, (224, 224)) # 将图片大小调整到224*224用于模型推理cv2.imwrite('images/target.png', img_init)self.img_label.setPixmap(QPixmap("images/show.png"))self.result.setText("等待识别")# 预测图片def predict_img(self):img = Image.open('images/target.png') # 读取图片img = np.asarray(img) # 将图片转化为numpy的数组outputs = self.model.predict(img.reshape(1, 224, 224, 3)) # 将图片输入模型得到结果result_index = int(np.argmax(outputs))result = self.class_names[result_index] # 获得对应的水果名称self.result.setText(result) # 在界面上做显示# 界面关闭事件,询问用户是否关闭def closeEvent(self, event):reply = QMessageBox.question(self,'退出',"是否要退出程序?",QMessageBox.Yes | QMessageBox.No,QMessageBox.No)if reply == QMessageBox.Yes:self.close()event.accept()else:event.ignore()if __name__ == "__main__":app = QApplication(sys.argv)x = MainWindow()x.show()sys.exit(app.exec_())
design.py用于测试界面
这篇关于基于Tensorflow2.x的MobileNet的病虫害分类(有界面)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







