本文主要是介绍【H.264/AVC视频编解码技术详解】十六:帧内预测编码的基本原理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
《H.264/AVC视频编解码技术详解》视频教程已经在“CSDN学院”上线,视频中详述了H.264的背景、标准协议和实现,并通过一个实战工程的形式对H.264的标准进行解析和实现,欢迎观看!
“纸上得来终觉浅,绝知此事要躬行”,只有自己按照标准文档以代码的形式操作一遍,才能对视频压缩编码标准的思想和方法有足够深刻的理解和体会!
链接地址:H.264/AVC视频编解码技术详解
GitHub代码地址:点击这里
在前面的博文中所述,视频信息中通常包含的冗余有三种:空间冗余、时间冗余和统计冗余。处理这三种冗余信息通常采用不同的方式:
- 空间冗余采用帧内预测编码压缩;
- 时间冗余采用运动搜索和运动补偿压缩;
- 统计冗余采用熵编码压缩。
在上述的各种编码技术中,帧内预测是非常重要的一种。因为在各种视频帧类型中,I帧(包括IDR帧等)全部采用帧内预测,I帧的压缩比率通常比P和B帧更低,因此帧内预测编码的效率对视频整体平均码率具有较大影响。另一方面,I帧通常都会作为P/B帧解码过程中的参考帧,如果I帧的编码出现了错误,那么不仅仅是该I帧出现错误,参考该I帧的P/B帧也同样不能正确解码。
1. MPEG-1/MPEG-2帧内编码
在早期的视频编码标准中就已经存在了帧内编码的方法。如MPEG-1/MPEG-2等早期的标准中,帧的类型已经定义了I/P/B三种类型,分别表示帧内编码帧、预测编码帧和双向预测编码帧。然而在H.264/AVC之前的标准中,编码I帧时并未采用预测编码,只有编码P/B帧时采用了帧间预测编码。在MPEG-1/MPEG-2等编码标准中,I帧的编码采用的是DCT-RLC的方法进行编码。I帧编码的主要流程如下图:
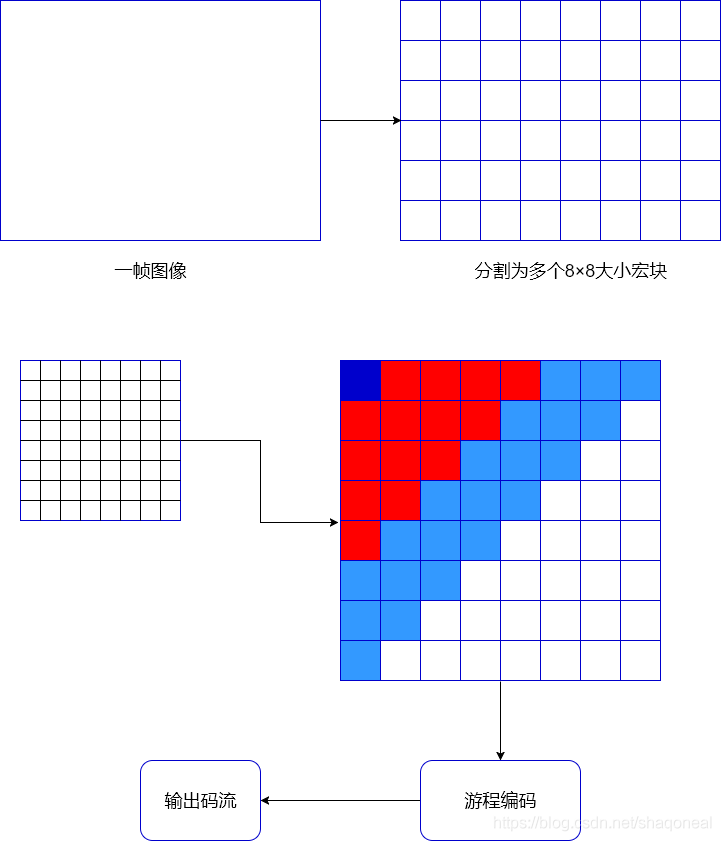
由于未采用预测算法,这种帧内编码的压缩效率相对较低,后期已经不能适应整体提升压缩比率的要求。
2. 预测编码的基本原理
对于存在前后相关性的信息,预测编码是一种非常简便且有效的方法。此时预测编码输出的不再是原始的信号值,而是信号的预测值与实际值的差。预测编码如此设计的出发点在于,由于前后存在相关性,相邻信号存在大量相同或相近的现象,通过计算其差值,可以减少大量保存与传输原始信息的数据体积。
我们用几个简单的例子来说明这个问题。假设有下面的一串数字:
1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 3
我们可以用如下的信息来表示这串数字信息:
Pred = 1;
Residual = { (1, 5), (2, 11) };
这些信息表示,目标信号的预测值为1,在第5和12个元素的位置存在残差,分别为1和2。
我们举另外一个例子,假设有下面一串数字:
0, 1, 2, 3, 5, 5, 6, 7, 8, 9, 10, 9, 12
对于这部分信号,可以如下表示:
Pred = n;
Residual = {(4, 1), (-2, 11)};
其表示的含义类似于前例。
从另一方面考虑,视频信息在输出码流之前需要经过量化操作。量化完成后的信息用数字化表示,其所需要的位数与表示信息的范围与方差有关。对于取值范围小、方差较小的信息,量化器所需要的比特范围就更小,每个像素数的比特位数便更小。统计表明,相比于原始的图像像素,预测残差的方差与动态范围远小于原始图像像素。通过预测编码,不仅降低了表示像素信息所需要的比特数,还可以保留视频图像的画面质量不至于降低。
3. H.264的帧内编码
在H.264/AVC中,帧内编码采用了全新的、更复杂的算法,相比早期标准的压缩比率大大提高。在H.264中采用的算法主要可分为预测编码模式和PCM编码模式。
2.1 H.264帧内预测编码
预测编码并非H.264最先采用的技术。在早期的压缩编码技术中便采用了预测数据+残差的方法来表示待编码的像素。然而在这些标准中预测编码仅仅用于帧间预测来去除空间冗余,对于帧内编码仍然采用直接DCT+熵编码的方法,压缩效率难以满足多媒体领域的新需求。H.264标准深入分析了I帧中空间域的信息相关性,采用了多种预测编码模式,进一步压缩了I帧中的空间冗余信息,极大提升了I帧的编码效率,为H.264的压缩比取得突破奠定了基础。
H.264的帧内预测算法通常可以分为三种情况讨论:4×4的亮度分量预测、16×16的亮度分量预测、色度分量预测。我们分别讨论这三种情况的算法原理。
2.1.1 4×4亮度分量预测
对于每一个帧内预测宏块,其编码模式可以分为I_4x4和I_16x16两种。对于I_4x4模式,该宏块的亮度分量被分为16个4×4大小的子块,每一个4×4大小的子块作为一个帧内预测的基本单元,针对每一个4×4像素块进行过预测与编码。
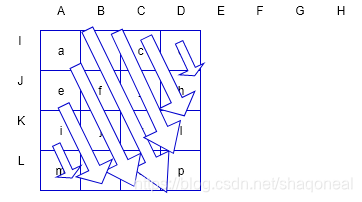
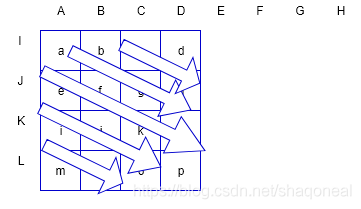
帧内预测会参考每一个像素块的相邻像素来构建预测数据。对于某一个4×4的子块而言,该子块上方4个、右上方4个、左侧4个以及左上方顶点的1个像素,共13个像素会作为参考数据构建预测块。预测块同参考像素的位置关系如下图所示:
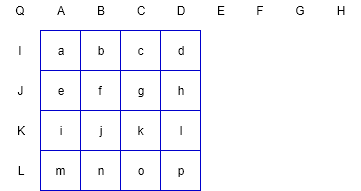
在上图中,a~p表示预测块中的像素,A/B/C/D表示上方参考像素,E/F/G/H表示右上方的参考像素,I/J/K/L表示左方参考像素,Q表示左上方的参考像素。对于4×4亮度分量的帧内预测,共定义了9种不同预测模式。
模式0:垂直模式
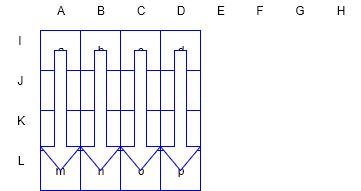
在该模式下,每一个预测块的预测值由上方相邻的4个像素预测得到;
模式1:水平模式

在该模式下,每一个预测块的预测值由左方相邻的4个像素预测得到;
模式2:DC模式
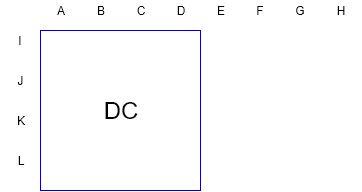
该模式下,用上方和左方相邻像素的均值表示整个预测块;
模式3:左下模式
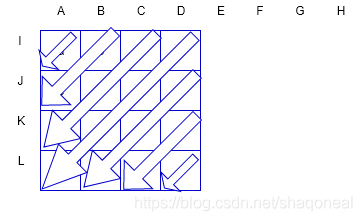
模式4:右下模式
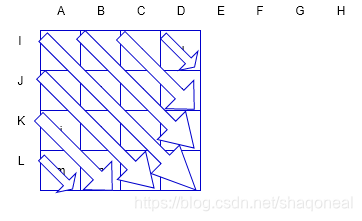
模式5::右垂直模式
模式6:下水平模式
模式7:左垂直模式
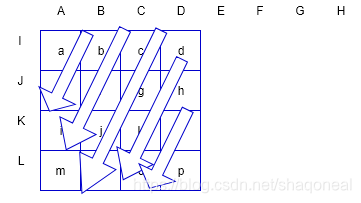
模式8:上水平模式
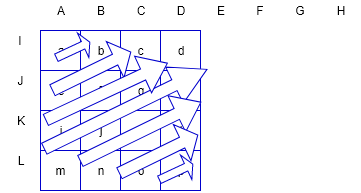
2.1.2 色度分量与16×16亮度分量
模式0:垂直模式
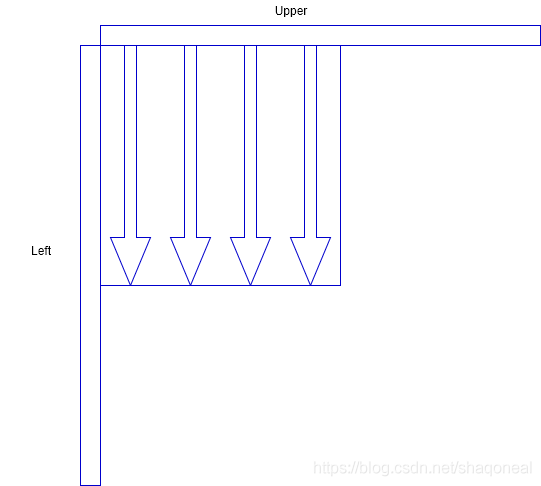
模式1:水平模式
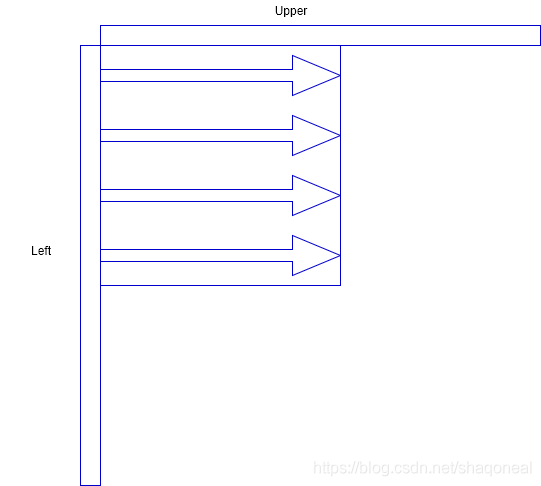
模式2:均值模式
模式3:平面模式

2.2 H.264的I_PCM编码模式
除了帧内预测编码之外,H.264还定义了一种特殊的编码模式,即为I_PCM模式。I_PCM模式不对像素块进行预测-变换-量化操作,而是直接传输图像的像素值。在有些时候(如传输图像的不规则纹理信息,或低量化参数条件下),该模式比预测编码模式效率更高
这篇关于【H.264/AVC视频编解码技术详解】十六:帧内预测编码的基本原理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





