本文主要是介绍ALM研发管理中规则库的配置与使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.规则库简介
规则库就是描述某领域内知识的产生式规则的集合,而规则往往是由一个具体的业务逻辑具象而来,它通常是很具体的,有着明确的处理逻辑(即将输入数据经过一系列逻辑处理,输出处理后的结果)。
2.规则库的意义
有了规则库之后,我们可以根据库内的具体实现的规则,来对我们的具体业务做出更加科学、准确的决策。
这里用泽众的研发测试一体化平台(简称ALM)的规则库功能举个例子,在ALM的测试管理模块中,工程师通常需要进行测试用例的设计,特别是关系到与接口数据相关的测试项时,此时若手动设计用例则会有以下两个问题存在:①与接口数据相关的用例数量很大,手工设计很耗费时间②工程师手工设计过程中可能会漏掉某些特定条件组合,导致设计出的用例覆盖率不能达到100%。
针对以上问题,引入规则库并针对这些数据关联关系设定规则,则可以快速并且准确的自动生成用例,并且也能较大程度的避免遗漏、错漏,下面我们来具体看看ALM中规则库是怎么操作实现的。
3.ALM中规则库的使用
3.1.规则库配置
1)在规则库配置界面,需要先输入/导入对应的栏位数据

2)设定数据规则对应关系,如此处选定一组数据为固定数据

3)至此,规则库设定完成
3.2.规则库引用
1)活动图中引用规则库规则,注意:栏位需要一一对应
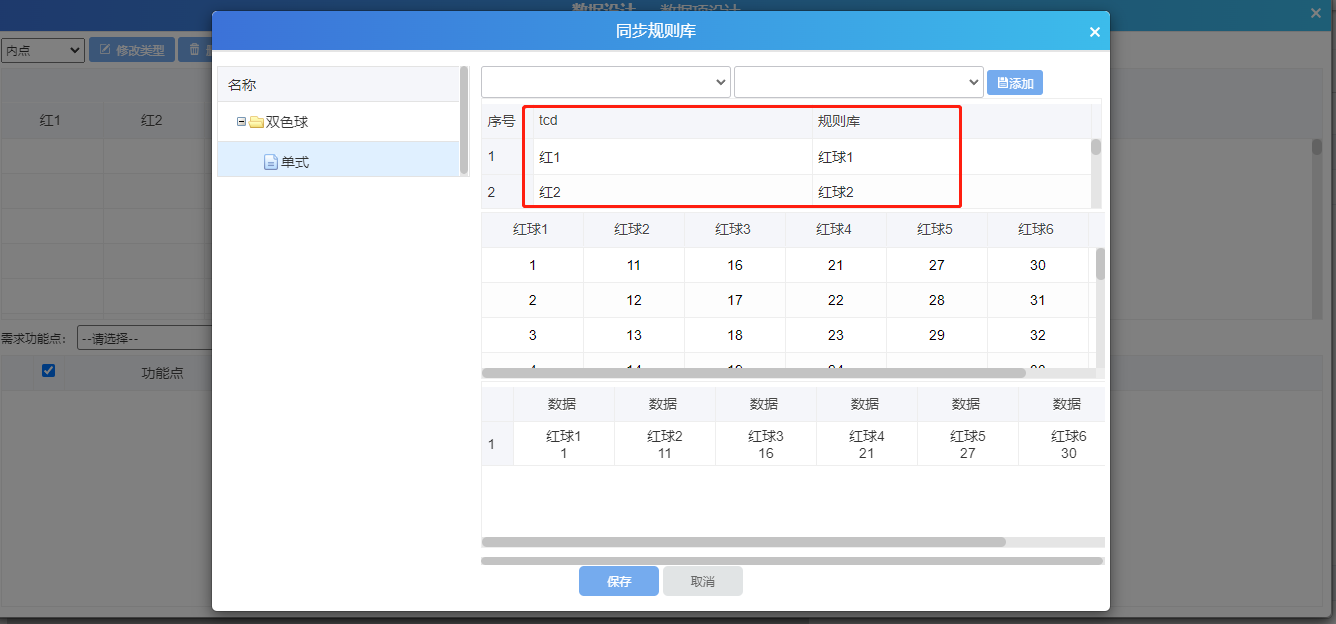
2)引用设置完成后,将自动同步规则库数据到此处数据设计中

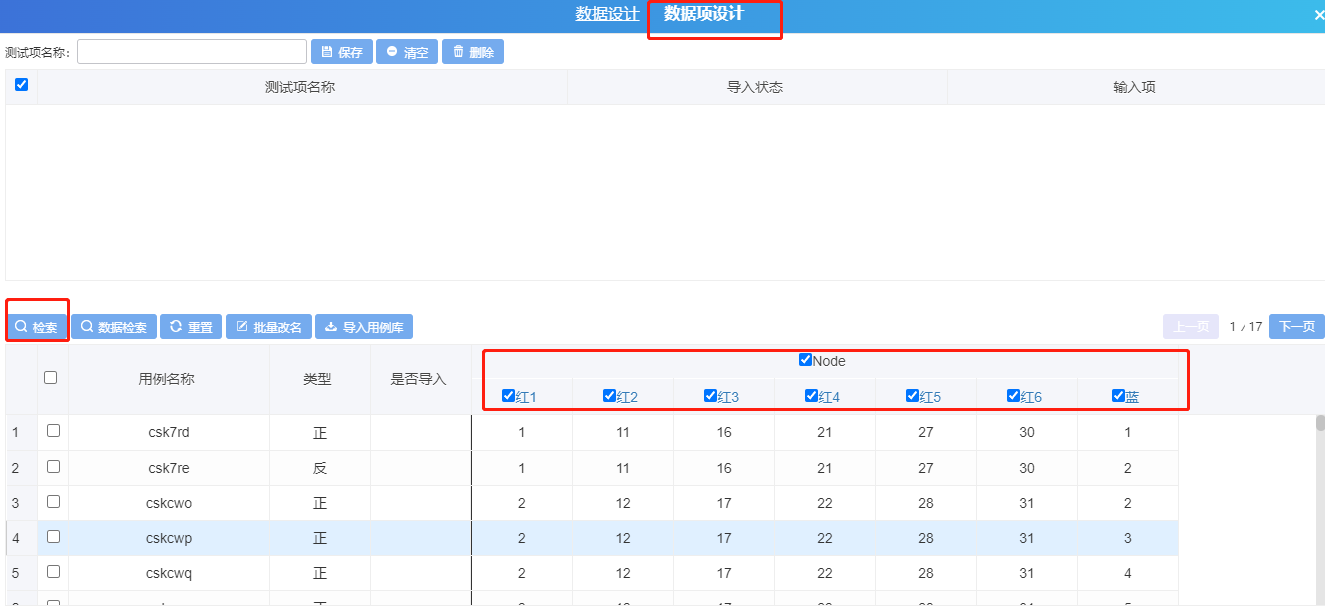
3)再切换进入数据项设计界面,选择节点,进行数据检索,此时将自动根据所设置的规则以正交法生成给数据项的组合情况,即测试用例,此处我们可以看到,因为设定了规则,(1,11,16,21,27,30)这列组合只生成了2条用例,即一条正例一条反例
以上,就是规则库在ALM中的应用了,感兴趣的小伙伴,可以自行进行操作哟,咱们下期再见。
这篇关于ALM研发管理中规则库的配置与使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




