本文主要是介绍干货好文 | 两地三中心到异地双活演变及关键技术探讨,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
两地三中心和异地多活都是分布式系统的关键技术,用于保证系统的高可用性和容错性。其中最关键的技术无疑是数据同步、同步防环和数据冲突解决。
异地容灾 & 两地三中心
两地三中心架构是一种分布式系统的架构模式,用于保证系统的高可用性和容错性。它将整个系统划分为三个数据中心:两个位于同城,一个位于异地。其中,同城的两个数据中心分别承担主备的角色,异地数据中心则作为备份。
在两地三中心架构中,同城的两个数据中心之间通过高速网络进行数据同步,实现了主备切换和故障恢复。当主数据中心发生故障时,备份数据中心会自动接管服务,保证系统的连续性和可用性。同时,异地数据中心作为备份,可以在主备数据中心都出现故障时提供服务。
两地三中心架构具有以下优点:
-
高可用性:通过主备切换和异地备份,保证了系统的高可用性和连续性。
-
容错性:当某个数据中心或服务器出现故障时,可以快速切换到其他可用的数据中心或服务器上,保证了系统的容错性。
-
灵活性:可以根据业务需求灵活配置数据中心的数量和位置,满足不同的业务需求。
-
性能优化:可以通过负载均衡等方式优化系统的性能,提高用户体验。
-
安全性:可以通过数据同步和容灾备份等方式保证数据的安全性和完整性。
以MySQL数据库为例,可以通过同城双向复制和异地异步复制来实现两地三中心架构。
以下是两地三中心架构的部署架构:
-
主数据中心:包括一个MySQL主库和一个或多个MySQL从库,主库用于写入操作,从库用于读取操作。
-
同城备份数据中心1:包括一个MySQL主库和一个或多个MySQL从库,主库用于备份主数据中心的数据,从库用于读取操作。
-
异地备份数据中心2:包括一个MySQL主库和一个或多个MySQL从库,主库用于备份主数据中心的数据,从库用于读取操作。
尽管两地三中心架构具有很多优点,但也存在一些缺陷:
-
成本高:由于需要建设多个数据中心和进行数据同步等操作,所以成本较高。
-
配置复杂:两地三中心架构需要对系统进行详细的规划和配置,包括主备切换、数据同步、负载均衡等方面,因此配置比较复杂。
配置这么复杂,而且同城备份中心和异地备份中心基本上都用不到,造成了大量的资源浪费;并且大部分用户并不能做到每个月/季度做一次容灾演练,导致真正发生机房异常的情况下,同城或者异地容灾中心并不能派上用场,用户做两地三中心并没有什么动力。
一般企业的选择是:对部分核心业务和有监管要求的数据库才会搭建同城容灾,并且对异地容灾会尽量缩减规模,例如:主中心是一主两从,而异地容灾中心可能只有一个数据库实例,去掉了从机。
总之,两地三中心架构的部署需要对系统进行详细的规划和配置,并且需要考虑多个数据中心之间的协调和管理。
异地多活 & 单元化
上面说的两地三中心和异地容灾方案成本高、配置复杂、真正需要的时候不一定用的上,有些企业特别是业务在全国甚至全球范围需要本地化访问时会采用异地多活(或者称为单元化)的解决方案。
异地多活架构(Active-Active Architecture)是一种分布式系统架构,它允许多个数据中心同时处理用户请求,并且这些数据中心之间可以相互协作,实现数据的共享和同步。异地多活架构有以下优缺点:
优点:
-
高可用性:异地多活架构可以在多个数据中心之间进行负载均衡和故障转移,从而提高了系统的可用性和容错性。
-
低延迟:由于数据中心之间可以相互协作,因此可以将数据尽可能地靠近用户,减少网络延迟和响应时间。
-
数据共享:异地多活架构可以实现数据的共享和同步,从而提高了数据的可靠性和一致性。
-
灵活性:异地多活架构可以根据实际需求进行扩展和缩减,从而满足不同规模和复杂度的业务需求。
异地多活最大的挑战来自于数据库,最主要的来自于数据一致性:由于异地多活架构需要实现数据的共享和同步,因此需要解决数据一致性的问题,避免出现数据冲突和错误。
闲话少说,举例为证:假设你是一个MySQL DBA,你们公司有三个机房:北京、广州和上海。领导要求你提供一个解决方案:让每个地区的客户都就近访问本地的数据库,华北的客户数据存储在北京的数据库,华东的客户数据存储在上海的数据库,华南的客户数据存储在广州的数据库上。这些数据库的数据需要能相互同步,保证数据一致,以便华北的用户出差到上海以后可以就近访问上海数据库上的数据(这些数据是华北这个客户的数据从北京同步到上海的),在上海出差产生的数据同样应该同步回北京。这样客户出差回北京以后,他可以继续访问和更新“最新”的数据。
对应的,你就需要搭建一个异地多活架构来实现数据的就近访问和不同中心的数据同步。具体的方案如下:
-
在每个机房都部署一套MySQL数据库。
-
通过VPN隧道或者其他技术,打通各个机房的网络,让MySQL可以建立复制链路。
-
配置MySQL GTID复制,搭建双向复制,将不同机房之间的数据进行双向同步,保证数据的一致性和可靠性。
简单的示意图如下:

总之,异地多活架构是一种高级别的分布式系统架构,具有高可用性、低延迟、数据共享和灵活性等优点,但也存在复杂性、成本较高、数据一致性和安全性等缺点,需要根据实际情况进行选择和应用。
同步防环
如前所述,不管是两地三中心还是异地多活,其中比较关键的就是双向同步(两地三中心中的同城双向同步,异地多活的多中心双向同步),保证业务在一个中心写的数据可以复制到另外一个中心。数据库原生提供的复制有些本身是可以搭建双向复制的,但是这种方式只能做到实例级别同步(无法支持where条件过滤或者做对象名映射)、无法定制化修改(需要有内核修改能力并且修改后必须停业务以升级数据库),监控和管理不直观(命令行式,操作不便)。一般使用专业的双向同步工具或者其他第三方工具来实现,以保证易用性、易维护性,提供定制化修改和监控管理功能。
沃趣科技的DBMotion实现了MySQL和openGauss的双向同步,它不依赖于数据库原生的复制,采用独立的cdc解析模块从源库中获取重做日志并解析,通过sink模块将源库中的变更并行应用到目标库。如下图所示,如果不做特殊处理,将会出现循环复制的问题。

还是以MySQL为例,上图中两个MySQL实例分别位于华东中心和华南中心,如果通过DBMotion做双向同步,那么在华东中心插入一行数据,通过DBMotion在华南回放,也会插入一行数据;但是反向的DBMotion解析到这条insert的数据,又会将它同步回华东中心。也就产生了循环复制,如果是无主键表,insert不产生唯一约束冲突,这个insert将在华东和华南永续循环复制下去。
当然,通过MySQL基于server-id是可以避免的。如图,在db1插入的数据,插入到db2的时候,在日志中也记录为server-id=1。这样dbmotion的反向复制,检查到server-id为1的日志要同步回来,就可以安全的过滤掉。

但是这种方式需要精准的控制每个中心所有数据库的server-id,下图中如果是server-id=1产生的更新,就会在华南中心的双master实例间做无限循环复制。

当然,MySQL也可以利用GTID来实现,但是GTID并不是所有的客户都开启的,如何兼容是一个问题。
上面只是以MySQL这种逻辑复制避免循环复制的方案。openGauss原生的复制目前是另外一种方案:华东中心复制写入华南中心的时候不记录日志。这样反向复制同步时,取不到正向同步的数据,也就不会形成循环复制。当然这种方式会导致华南中心的备库没有华东中心过来的数据,对于多中心数据同步也是无法级联同步数据的。
DBMotion采用的是类似于server-id打标的方式,在数据写入华南中心的时候对日志进行标记, 保证DBMotion写入的数据,在DBMotion日志解析的时候能够被认出来,避免数据被复制回华东中心。

如果扩展到多中心,还是会存在循环复制的问题,如图:在华北中心插入的数据被标识为region3,复制到华东和华南中心时,他们发现数据都不是自己发出的时候,就会出现循环复制的问题。

此时,DBMotion就需要做额外的处理,在华东中心把华北过来的数据和业务请求的数据统一标记成region1,这样在华南过来的业务数据没有标记,而从华东过去的数据都有标记,就可以将打标的更新成功过滤。

当然,这种同步还是避免不了用户故意搭建的环形复制链路产生循环复制,所以DBMotion支持的异地多活,目前只能支持树形复制,类似于下图的结构。在region-id=6的数据库上插入一笔数据,通过DBMotion同步到region-id=2的节点时,会将2标记为同步到region-id为1和5的节点,并且从1和5同步回来时会自动被过滤掉,之后会依次被同步到3,4;7;8。
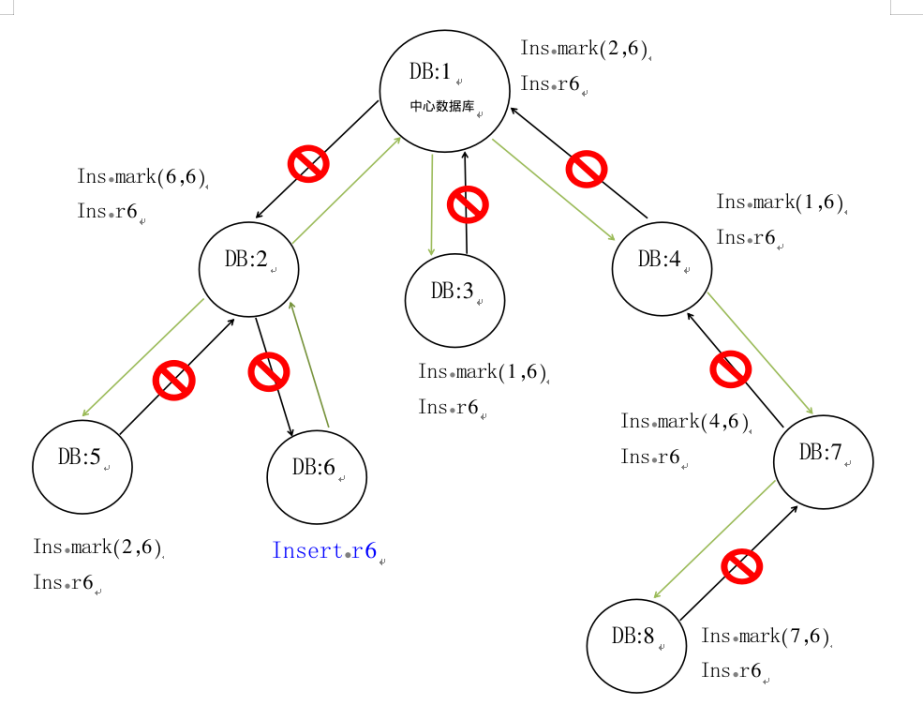
综上,“同步防环”可以解决一条更新在多个中心上循环复制的问题,异地双活的关键技术难点“循环复制”,可以通过打标忽略的方式解决。
冲突解决
异地多活又称为单元化,前提是业务可以单元化,让客户同时只在一个单元上操作。
如前文中提到的,北京的用户无论是在北京还是在上海,只会在不同的时间点更新自己的数据,不会出现在多个中心同时更新同一笔数据的情况。如果需要在同时在同一个时间点更新同一个数据,如北京和上海的用户同时汇款给广州的客户,就可能同时对广州的客户账户有两个增加余额的操作。
这种同时在多中心操作同一笔数据的方式,需要在业务上严格避免,或在业务架构上使用集中式架构,在同一个中心(或者通过同城多中心的分布式数据库)应对所有单元的更新请求;或对业务进行单元化分拆(以上面的汇款案例为例,广州的用户应该在北京和上海都有子账户,收到汇款只是在北京和上海的子账户上增加余额,对应的广州的这个用户查询余额就需要汇总所有中心的账户余额了)。
另外,复制延迟也有可能导致冲突,例如北京的客户出差到了上海来更新自己的数据,此时在北京的部分更新还没有同步到上海,那么也会出现类似于两边同时写同一份数据的冲突。
上述数据冲突的问题,都必须在业务或者说在数据库的上层解决。通过数据同步将数据已经写入到数据库后,数据冲突在“下层”是无法解决的,只能检测冲突,提醒客户有冲突发生,并提供相关的冲突解决策略去辅助客户解决这个问题。
DBMotion通过匹配前镜像和后镜像更新报错来发现冲突,目前提供两种机制来处理冲突:
-
复制链路可以指定冲突错误忽略列表,用户可以指定对部分冲突报错直接忽略报错,类似于MySQL的replica_skip_errors错误。例如:用户需要对Duplicate Key报错进行忽略,可以直接在冲突错误忽略列表中增加1062错误。
-
复制检测到冲突可以按照复制冲突策略来自动处理冲突。
DBMotion复制检测到冲突目前有三种冲突解决策略可以指定:
-
报错:DBMotion在检测到冲突以后就报错停止,配合上短信和邮件报警,用户收到报错后可以查看并手工解决冲突以后,点“继续”会让DBMotion断点续传从上次报错的位置继续同步。
-
忽略:DBMotion在检测到冲突后,只会在日志中记录冲突,忽略错误并继续同步。
-
覆盖:DBMotion会直接以主键或者唯一键对目标库进行覆盖,保证目标库和源库一致,继续同步。
总结
综上,冲突解决是异地多活和分布式数据库面临的通用问题,需要在业务架构上尽量避免。DBMotion在数据库同步的时候提供了两种机制,三种策略来辅助客户检测冲突和设置冲突解决策略。
目前DBMotion已经在Squids上上线,为客户提供异地、跨云的MySQL和openGauss多活业务访问,未来将继续支持更多的多活场景。
这篇关于干货好文 | 两地三中心到异地双活演变及关键技术探讨的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









