本文主要是介绍postgresql_internals-14 学习笔记(六)—— 统计信息,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
不完全来自这本书,把查到的和之前的文章重新汇总整理了一把。
一、 统计信息的收集
1. 主要参数
其中最主要的是track_counts,开启才会收集统计信息。
postgres=# select name,setting,short_desc,context from pg_settings where name like 'track%'; name | setting | short_desc | context
---------------------------+---------+--------------------------------------------------------------+------------track_activities | on | Collects information about executing commands. | superusertrack_activity_query_size | 1024 | Sets the size reserved for pg_stat_activity.query, in bytes. | postmastertrack_commit_timestamp | off | Collects transaction commit time. | postmastertrack_counts | on | Collects statistics on database activity. | superusertrack_functions | none | Collects function-level statistics on database activity. | superusertrack_io_timing | off | Collects timing statistics for database I/O activity. | superusertrack_wal_io_timing | off | Collects timing statistics for WAL I/O activity. | superuser2. 相关进程
- pg 15之前,由stats collector进程负责统计信息收集
之前看文档这个进程的启动跟 /etc/hosts 配置还有关系,设置错误会导致进程起不来,可以参考:故障:autovacuum和stats collector进程未正常启动 - 墨天轮
- pg 15取消了stats collector进程
统计信息由放在临时文件改为放至共享内存,并在停库前由检查点进程写到文件系统
PostgreSQL 15: Stats Collector Gone? What's New?
3. 自动收集
由autovacuum触发。触发条件:
- autovacuum_analyze_threshold:表被修改行数阈值,默认50
- autovacuum_analyze_scale_factor:表被修改行数比例,默认0.1
- 计算公式:pg_stat_all_tables.n_mod_since_analyze (自上次analyze以来被修改的行数)> autovacuum_analyze_threshold + autovacuum_analyze_scale_factor × pg_class.reltuples
它也有对应普通表的表级同名参数,可以针对各表调整。toast表无需收集统计信息,因此没有针对它的参数。
postgresql_internals-14 学习笔记(二)常规vacuum_Hehuyi_In的博客-CSDN博客
4. 手动收集
analyze [verbose] [table[(column[,..])]]
- verbose:显示收集进度
- table:要收集的表名,如果不指定,则收集当前数据库中所有表的统计信息
- column:要收集的列名,如果不指定,则收集所有字段的统计信息
- analyze命令对表加4级锁,不阻塞写
5. 默认抽样数
300×default_statistics_target参数(默认100)
/* Default statistics target (GUC parameter) */
int default_statistics_target = 100;为了调整所收集的统计信息的准确度,可以增大随机抽样比例,这个参数可以在session级别设置,也可以在列级别设置。
set default_statistics_target to xxx;
alter table tab_name alter column col_name set statistics xxx;
二、 基础统计信息
基础统计信息保存在pg_class中,主要是下面3项:
- reltuples:表预估行数,也是执行计划里row=的来源之一,pg 14用-1表示没收集过统计信息,以区分于空表
- relpages:表预估页数 relpages
- relallvisible :vm(visibility map)文件中被标记的页数
SELECT reltuples::numeric, relpages, relallvisible FROM pg_class WHERE relname = 'tmp001';
未收集统计信息的表
CREATE TABLE tmp_copy(LIKE tmp001) WITH (autovacuum_enabled = false);
SELECT reltuples::numeric, relpages, relallvisible FROM pg_class WHERE relname = 'tmp_copy';
在生成执行计划时,会按照表大小及字段宽度等预估行数,所以rows不会是0。并且如果表增大,预估的rows会相应增加(但如果delete删除表数据而表大小没有变化,则不会生效)。

具体可以参考:postgresql源码学习(56)—— explain是如何快速估算pg表行数的_Hehuyi_In的博客-CSDN博客
三、 详细统计信息
这部分内容存在pg_statistic系统表中,但里面的内容很难看懂,因此通常我们会看pg_stats视图。
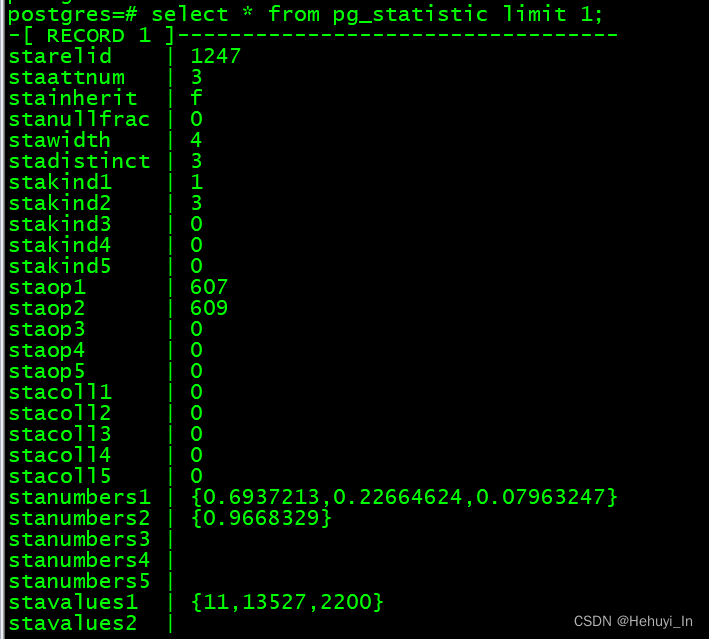
pg_stats视图内容

下面是主要字段含义
1. null_frac 空值比率
执行计划预估空值行数时,会用 reltuples * null_frac
insert into tmp001 select null from tmp001 limit 1000;
explain select * from tmp001 where aid is null;SELECT round(reltuples * s.null_frac) AS rows
FROM pg_class JOIN pg_stats s ON s.tablename = relname
WHERE s.tablename = 'tmp001' AND s.attname = 'aid';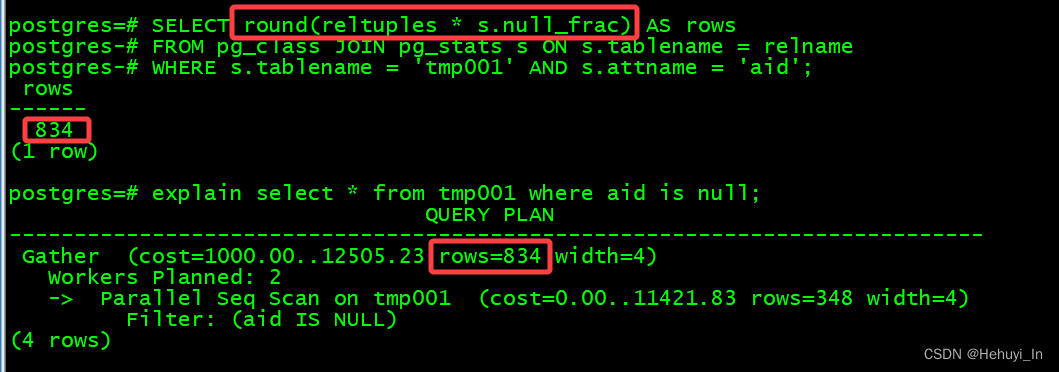
也可以明显看出来,是有误差的。
2. n_distinct 非重复值
- 如果值为负数,其绝对值代表非重复值在列中占比(总行数/非重复值)
例如-1表示所有值均不重复(总行数/非重复值=1),-3表示非重复值占0.3(总行数/非重复值=3)。
- 非重复值占比超过10%时会用比例表示,否则使用具体数字
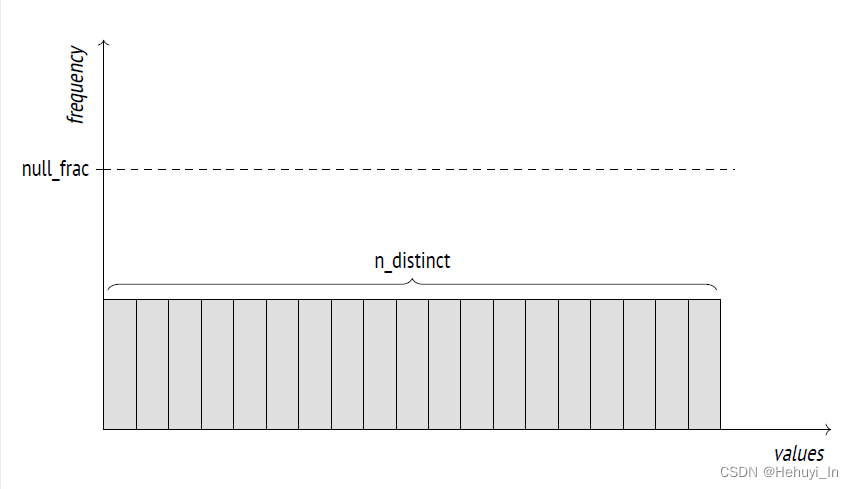
这一项由于仅抽样部分行,有时可能很不准确,可以手工指定列有多少非重复值
alter table tab_name alter column col_name set (n_distinct=xxx);如果表是有继承关系的其他子表的父表,还可以设置n_distinct_inherited,这样子表会继续使用这个父表的设置值。
alter table tab_name alter column col_name set (n_distinct_inherited=xxx);3. 最频繁值 Most Common Values
pg_stats视图的most_common_vals 和 most_common_freqs字段。
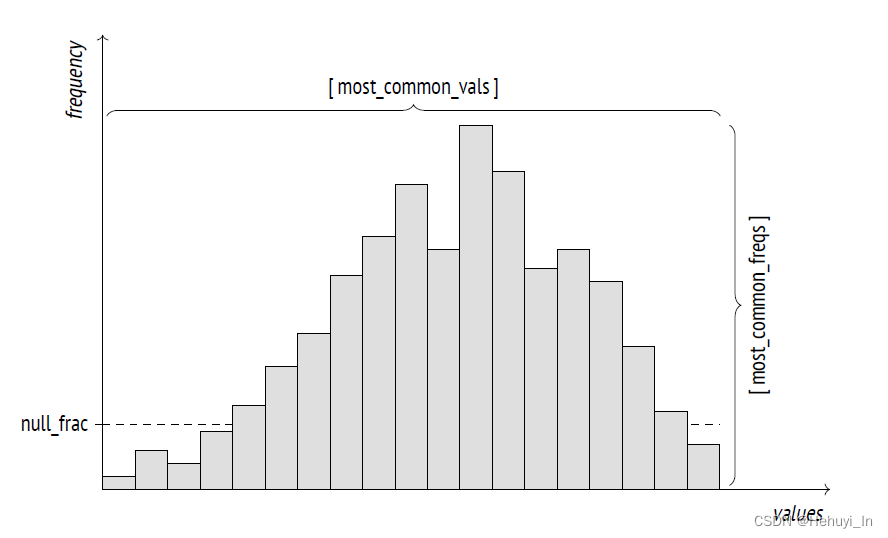
SELECT most_common_vals AS mcv,left(most_common_freqs::text,60) || '...' AS mcf
FROM pg_stats
WHERE tablename = 'pgbench_branches' and attname='bbalance';select bbalance,count(*) from pgbench_branches group by bbalance;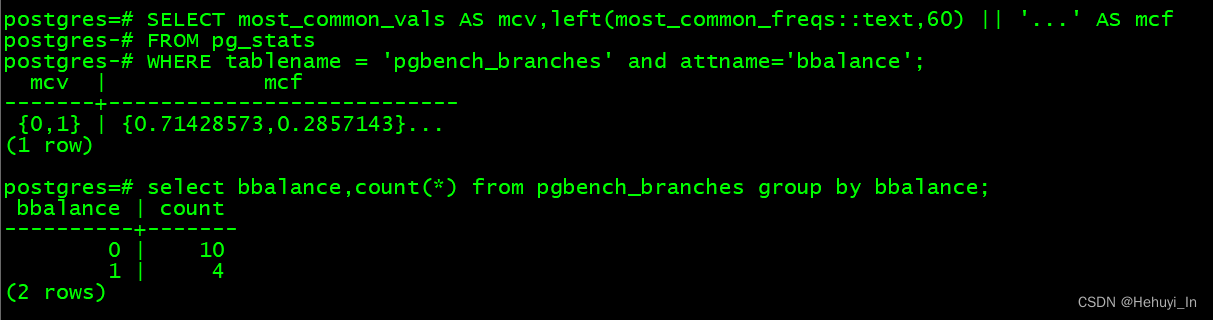
表示bbalance字段最频繁值是0和1,出现比率一个约71%,一个约28%
这个最常用于 column = value 的条件,例如
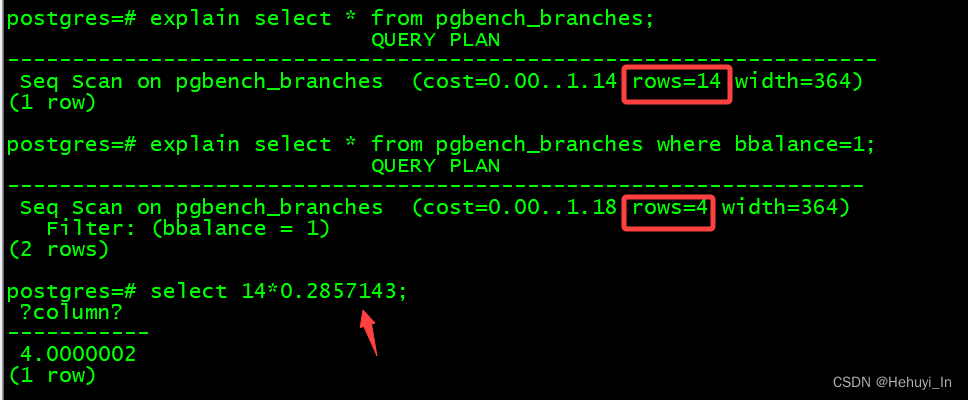
也适用于范围查询行数预估,本质上是一样的

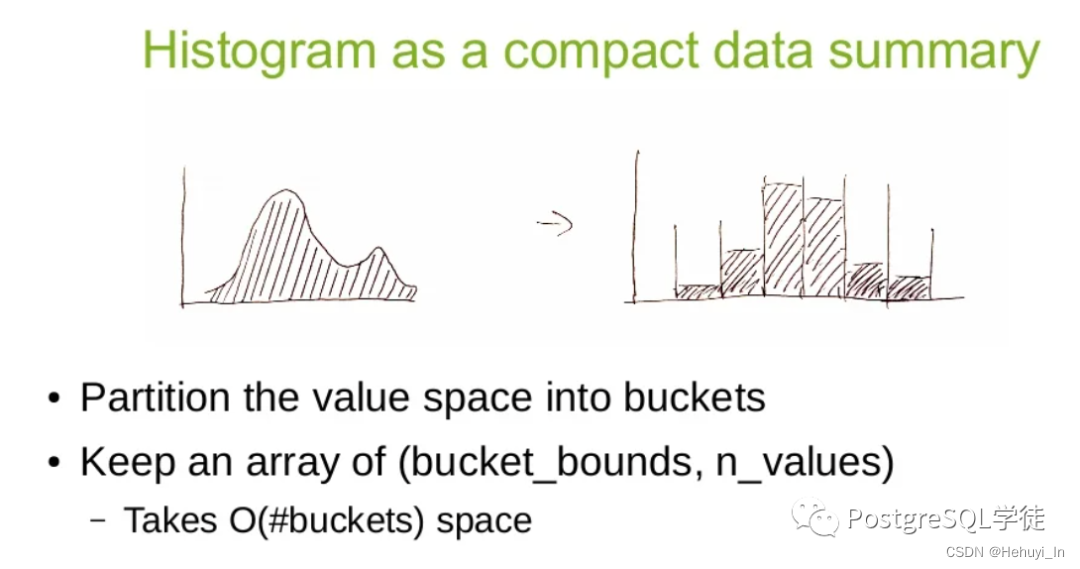
4. 直方图
如果distinct值太多,pg不可能一个个存起来,就会使用直方图保存。直方图的基本原理是将数据排序后分成若干个桶(bucket),并记录每个桶中数据的最大值、最小值、出现频次占比等信息。

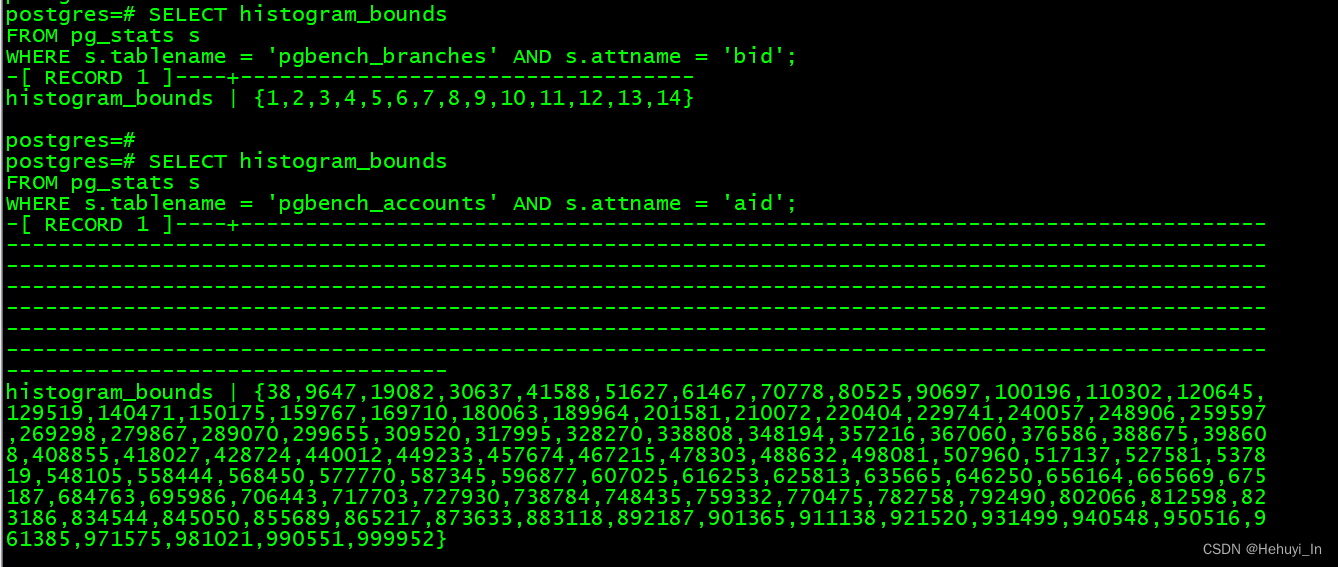
上面的bid是存了所有唯一值,下面aid就只用直方图存了部分值
最常见的直方图分为两类
- 等宽直方图 Equi-width Histogram
将数据按最大、小值区间等分为N份,即所谓"等宽"。
假设某一列各个值的分布如下
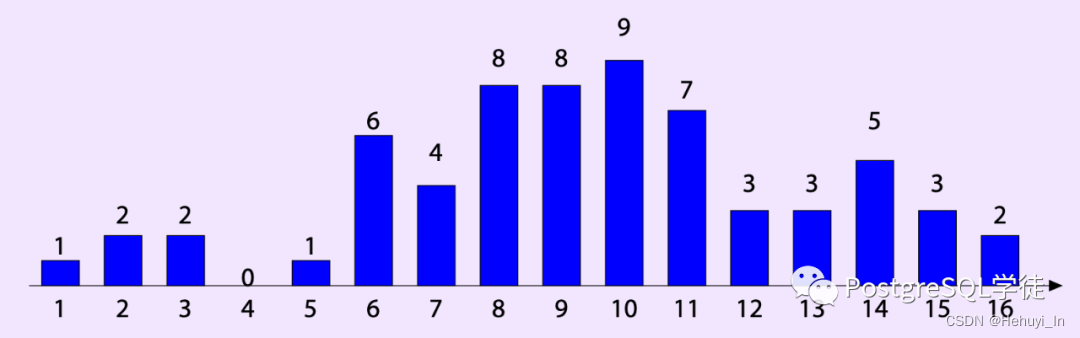
划分为4个桶,则等宽直方图为
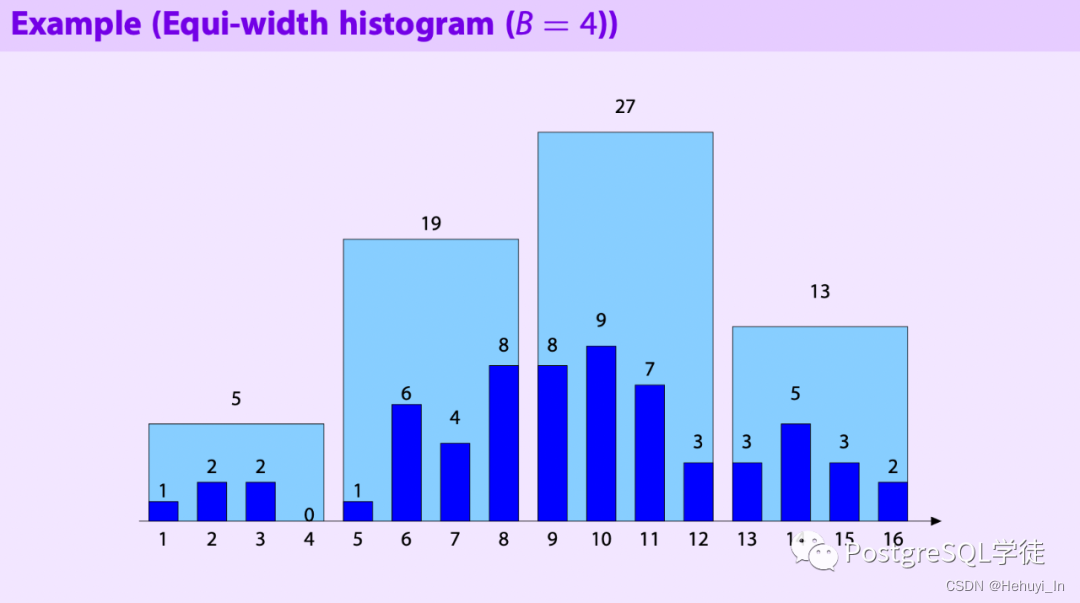
优点是简洁清晰,缺点则是无法根据各值出现频率进行统计。如果桶中值偏差度过高,预估的返回行数可能差距会很大。
-
等高直方图 Equi-depth Histogram
将数据按总频次等分为N份,每个桶中数值的频次之和为总行数的 1/N,即所谓"等高"。
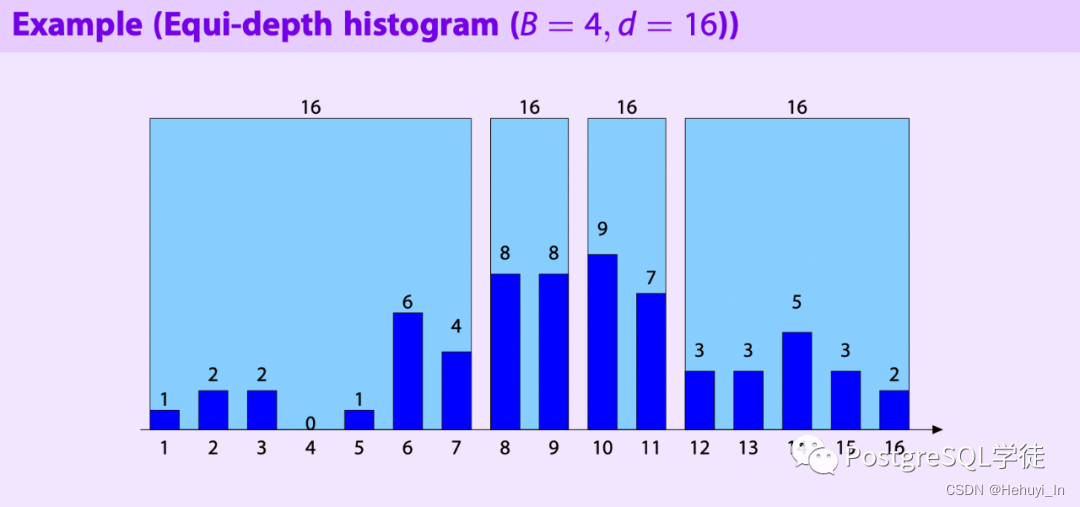
优点是增加选择率估算的准确性;且数据分散的区间内每个桶中的数值跨度更大,有利于减小储存直方图所消耗的内存。缺点是如果某个值占比极高,会导致它自己占很多个桶,其他大量值挤在一个桶中。
5. 非标准类型的统计信息
most_common_elems,most_common_elem_freqs,elem_count_histogram 会显示非标准类型的元素的mcv,mcf,直方图信息,通常适用于数组、向量、范围等数据类型。
6. 平均宽度 avg_width
顾名思义,列中存储值的平均宽度,通常对变长的字符串类型比较有意义。
select avg_width FROM pg_stats where tablename='tmp002';
7. 相关度 Correlation
元组顺序与物理存储顺序。1表示完全一致,-1表示完全相反,越一致通常性能越好。
postgres=# create table test2(id int);
CREATE TABLE
postgres=# insert into test2 SELECT ceil(random() * 5) AS num FROM generate_series(1,5);
INSERT 0 5
postgres=# select * from test2;id
----52143
(5 rows)postgres=# analyze test2;
ANALYZE
postgres=# select correlation from pg_stats where tablename = 'test2';correlation
--------------0.2
(1 row)cluster命令可以对表进行进行聚簇,不过只对存量数据有效,增量数据无法保证,并且是8级锁,通常不会这样来用。
postgres=# create index on test2(id);
CREATE INDEX
postgres=# cluster test2 USING test2_id_idx ;
CLUSTER
postgres=# select * from test2;id
----12345
(5 rows)postgres=# analyze test2;
ANALYZE
postgres=# select correlation from pg_stats where tablename = 'test2';correlation
-------------1
(1 row)四、 表达式统计信息
1. 直接为表达式收集统计信息
当条件是表达式时(function-call = constant),pg给它预估的返回行占比总是0.5%,这可能会非常不准确。例如下面这个例子,条件是month,而最多只有12个月,因此占比预估约为1/12.
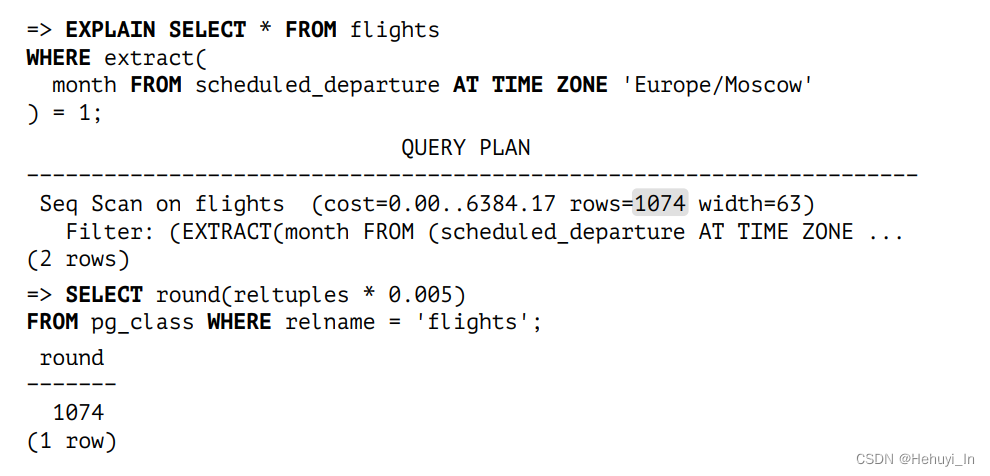
因此,pg引入了作为扩展的表达式统计信息,用法有点类似函数索引。
CREATE STATISTICS flights_expr ON (extract(
month FROM scheduled_departure AT TIME ZONE 'Europe/Moscow'
))
FROM flights;
扩展统计信息存在pg_statistic_ext系统表中,收集的数据单独存在pg_statistic_ext_data表中,而表达式统计信息可以在pg_stats_ext_exprs视图中查到。
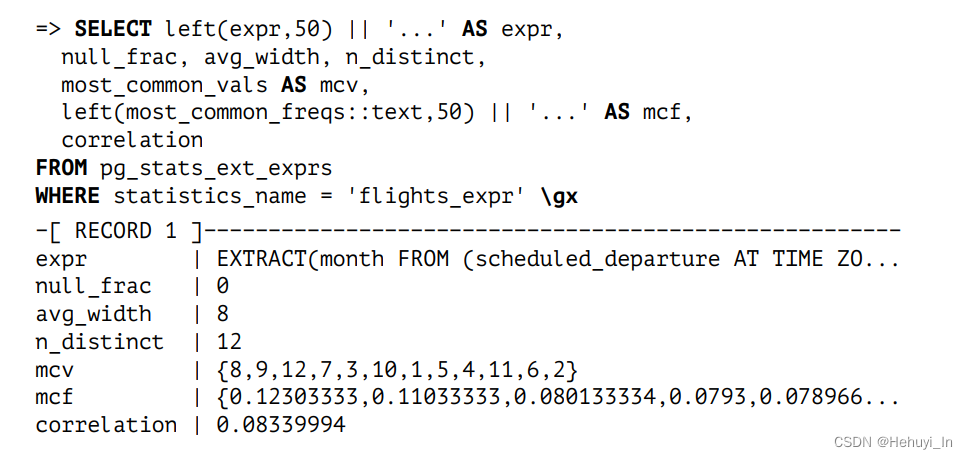
2. 为表达式索引收集统计信息
另一个方法是为表达式创建索引,并对该索引收集统计信息(在pg_stats中查询)
CREATE INDEX ON flights(extract(month FROM scheduled_departure AT TIME ZONE 'Europe/Moscow'));
ANALYZE flights;
五、 多元统计信息 multivariate statistics
类似oracle,这是为了解决列之间的相关性问题(correlated predicates)。一个经典案例是问出生在9月并且是处女座的人有多少,如果将两列当作毫无关系,预估值就会大大降低。
CREATE STATISTICS flights_dep(dependencies)
ON flight_no, departure_airport FROM flights;在pg 14中,不仅可以为多列创建扩展统计信息,还可以为多个表达式列也创建统计信息。
参考
《Postgresql修炼之道:从小工到专家(第二版)》
深度剖析PostgreSQL中的统计信息
PostgreSQL学习篇13.1 统计信息的收集_在路上-CSDN博客_postgresql 收集统计信息
PostgreSQL中的统计信息
这篇关于postgresql_internals-14 学习笔记(六)—— 统计信息的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







