本文主要是介绍号外!论文查重必杀技之图文混编,快编不下去了。。,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
最近作者去图文上自习,忙着写论文,像我这么渣渣的还面临着写毕业论文的困扰的时候,别人已经都论文查重了,跟我一起上自习的基友,在那捣鼓,捣鼓啥呢? 把论文中的字截图,然后粘进原文,做到鱼龙混珠。他说这样做是为了减少查重率。纳尼?窝草,这样!也行??重复率降低先不说,但是一个字一个字用QQ截图再插入论文方法太土了吧,这样做的效率太低了吧。程序员的第一反应就是我能用java来实现, 一个 idea ocurred on me 。
缕一缕
先需求分析一下,输入一段文字,让其自动的转换成图文混编的形式,看上去就好像都是一句话,其实实际上里边惨杂着好多字的图片形式。
如果使用java来实现的话需要用到文字转换图片的技术,还有就是写入doc的技术。
原理
大概已经知道了什么情况,使用两个手段就能实现这个小小的需求。
1.验证码生成技术
2.java操作doc技术
验证码笔者了解,而且会做,java操作doc技术还是第一玩,于是查了一下,感觉实现不是很难。
效果
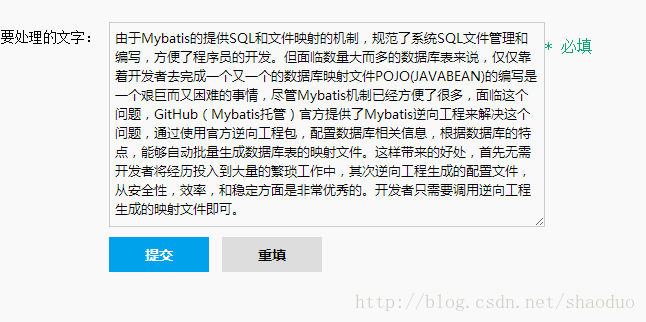
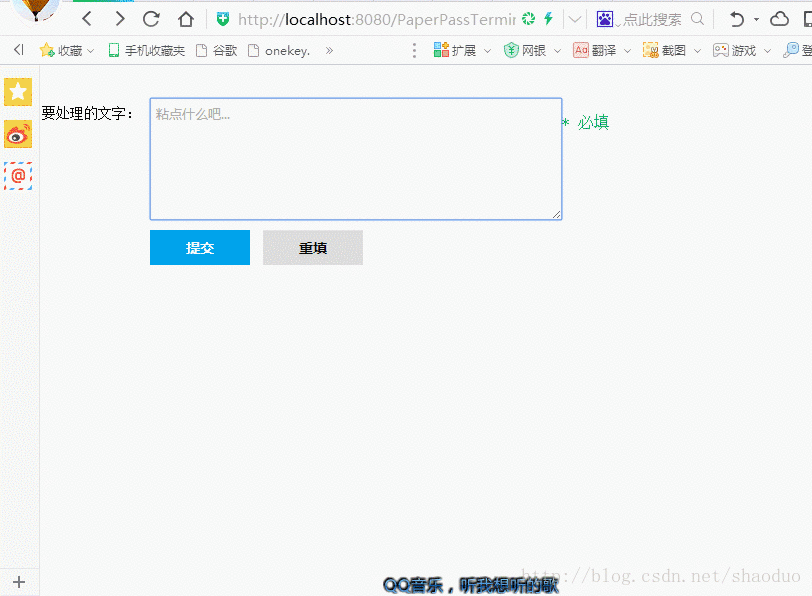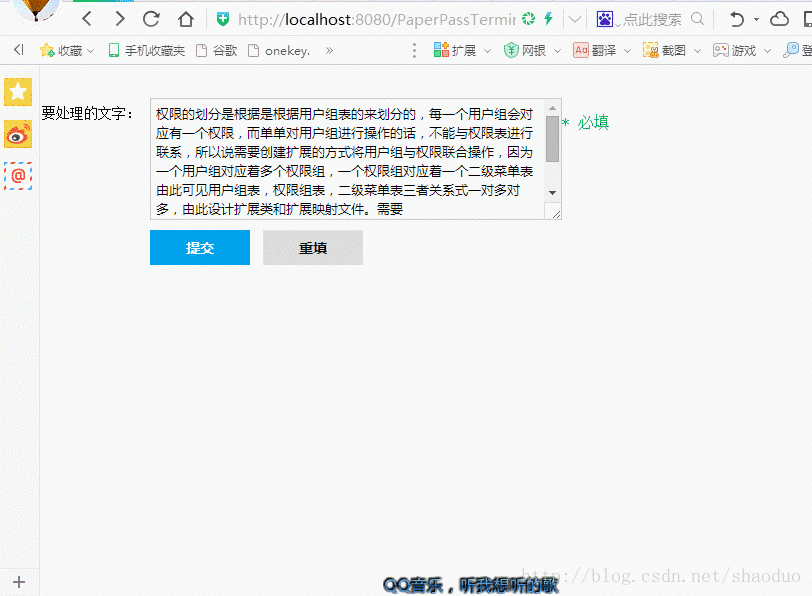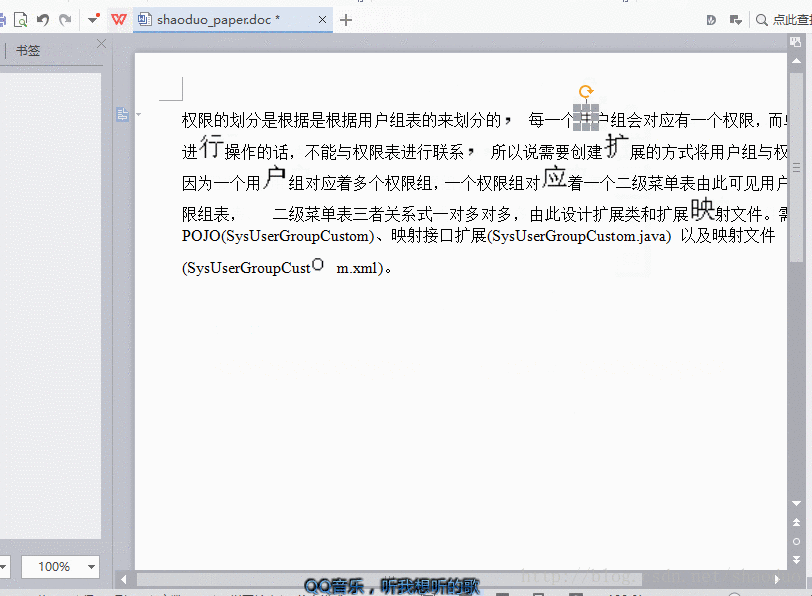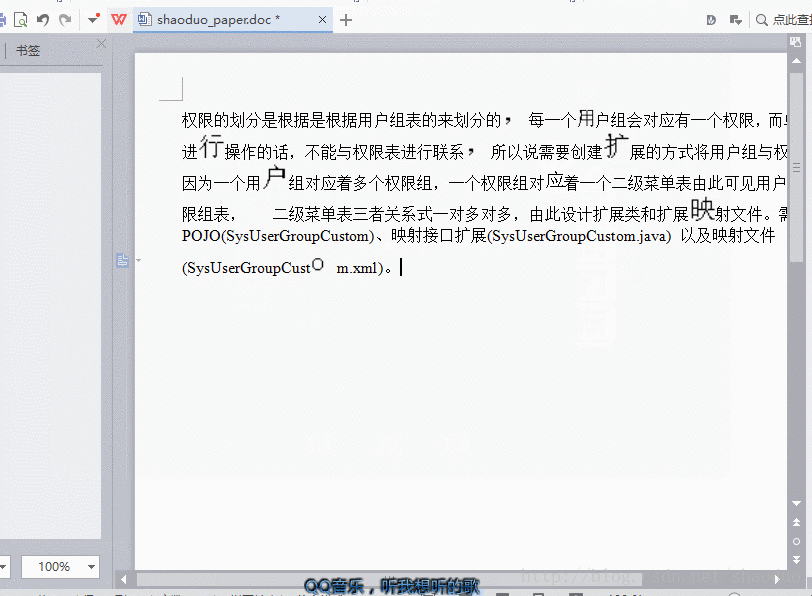
实现
文字转成图片
将文字转换成图片的图片生成代码
使用了Graphics2D 生成图片,代码很简单。
public ByteArrayOutputStream makeOne(String word,Params param) throws Exception {//创建内存图像image = new BufferedImage(params.getWidth(), height, BufferedImage.SCALE_SMOOTH) ;Graphics2D g = image.createGraphics() ;g.setColor(Color.white);g.drawRect(0,0, width, height); //画边框g.fillRect(0,0, width, height); //填充背景颜色g.setColor(param.getTextColor()); //设置字体颜色Font font = new Font("simsun",0,20) ;g.setFont(font);// 设置字体g.drawString(word,0,18);ByteArrayOutputStream bos = new ByteArrayOutputStream() ;ImageIO.write(image, "png", bos) ; //将图片格式转换成 bos数组return bos ;}有人问为什么要将图片BufferedImage对象转换为ByteArrayOutputStream 流呢? 因为在doc生成中要用到bos流的构造所以需要转换一下。
写入DOC
java操作doc有很多优秀的开源框架,其中有名的一个就是使用itext ,itext提供强大的java操控数据库,包括表格,图片,段落等等。这里我们只需要如何把图片和文字写进去就行了。
创建一个WoldHelper 类负责插入文字和图片
导入Itextjar包
IText 2.1.7 jar 包,可以利用此包来导出word文档
http://download.csdn.net/detail/ap0906230/6821411
WoldHelper.java
public class WordHelper {private Document document ;private BaseFont bfChinese ; private Paragraph context ;public WordHelper(Document document,Paragraph context) {this.document = document ;this.context = context ;}public void openDocument(String filePath) throws DocumentException, IOException {
// 建立一个书写器(Writer)与document对象关联,通过书写器(Writer)可以将文档写入到磁盘中 RtfWriter2.getInstance(this.document, new FileOutputStream(filePath)); this.document.open();
// 设置中文字体
/* this.bfChinese = BaseFont.createFont("STSongStd-Light", "UniGB-UCS2-H", BaseFont.NOT_EMBEDDED);*/}/** * @param contextStr 内容 * @param fontsize 字体大小 * @param fontStyle 字体样式 * @param elementAlign 对齐方式 * @throws com.lowagie.text.DocumentException*/ public void insertContext(String contextStr,int fontsize) throws DocumentException{ // 正文字体风格 Font contextFont = new Font(fontsize); // context = new Paragraph(contextStr) ;//设置行距 context.setLeading(3f);// 正文格式左对齐 // context.setAlignment(elementAlign);context.setFont(contextFont); // 离上一段落(标题)空的行数 // context.setSpacingBefore(1);// 设置第一行空的列数 // context.setFirstLineIndent(20); context.add(contextStr) ;}/*** * @param os 图片os流* @param param 格式参数*/public void insertPhoto(ByteArrayOutputStream os,Params param){ byte [] b = os.toByteArray() ;Image img = null;try {img = Image.getInstance(b);// img.setAbsolutePosition(0, 0);//设置图片的绝对位置img.setAlignment(Image.MIDDLE);// 设置图片显示位置// img.scaleAbsolute(param.getWidth(), param.getHeight());// 直接设定显示尺寸// img.scalePercent(70);// 表示显示的大小为原尺寸的20%} catch (BadElementException e) {// TODO Auto-generated catch blocke.printStackTrace();} catch (MalformedURLException e) {// TODO Auto-generated catch blocke.printStackTrace();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}try {context.add(img) ; //加上图片} catch (Exception e) {// TODO Auto-generated catch blocke.printStackTrace();}}
}
控制写入
有了生成图片,有了写入图片和文字的方法。如何控制哪些字体是文字哪些字体是图片,这里我使用了将字符串分割,使用随机方法的方式去挑选一些文字作为图片。组织有规律的写入doc。
public class Converter {private Document document ;private BaseFont bfChinese ; private WordHelper wordHelper ;private String contnet ; private Params param ;private Paragraph context ;//组织转换方法。public int convert(List<StringBuilder> sbList,Params param) throws Exception{int flag = 0 ;StringBuilder sb = new StringBuilder() ;Document document = new Document() ;Paragraph context = new Paragraph();wordHelper = new WordHelper(document,context) ;wordHelper.openDocument("E:\\shaoduo_paper.doc"); //存到的路径if(sbList!=null||sbList.toString().length()!=0){for(int i = 0 ;i<sbList.size(); i++){Random r = new Random() ;String detail[] = sbList.get(i).toString().split(""); int position = r.nextInt(detail.length) ;for(int j = 0 ; j<detail.length ;j++){if(position==j){PhotoMaker maker = new PhotoMaker(param);ByteArrayOutputStream os =maker.makeOne(detail[position], param) ;wordHelper.insertPhoto(os, param);}else{wordHelper.insertContext(detail[j], 20);}}}document.add(context); document.close(); //更改文档完成flag = 1 ;}return flag ;}// 通过,分割语句public List<StringBuilder> splitWordsToArry(String str){ String strArry[] = str.split("") ;StringBuilder sb = new StringBuilder() ;List<StringBuilder> sbList =new ArrayList<StringBuilder>();for(int i=0 ;i<strArry.length;i++){if(!strArry[i].equals(",")&&!strArry[i].equals("。")&&i!=strArry.length-1){sb.append(strArry[i]) ;}else{sb.append(strArry[i]) ; // 只为把逗号加上不然就落下了sbList.add(sb);sb = new StringBuilder() ;}}return sbList;}}
总结
以上代码只是核心代码,源代码附上。
http://pan.baidu.com/s/1slk8Rq1
版权声明
author :shaoduo
原文来自:http://blog.csdn.net/shaoduo/article/details/72829724
其他出处均为转载,原创作品,欢迎读者批评指正。
这篇关于号外!论文查重必杀技之图文混编,快编不下去了。。的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









