本文主要是介绍如何用 Python 选出好用又便宜的手机?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!


9月13日发布的iPhone Xs算是手机界的大新闻了,新款iPhone的价格也再度刷新了手机定价的记录。看完发布会,相信很多人的心情是这样的......

笔者之前用的iPhone 6,最近准备换手机。经济形势严峻,换iPhone是换不起了,只能消费降级,投奔安卓阵营。
1500元的预算,连个二手的iPhone都买不了,但是在安卓机里却有不少选择。本文我们就来看看怎样用数据分析选购手机。

分析思路
思路很简单,上京东商城把所有手机的数据爬下来,然后根据配置、价格过滤出符合条件的手机,在过滤出来的手机里选择一部性价比最高的。画成流程图,大致是这样的:
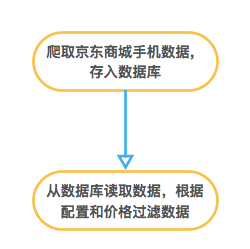

爬取数据
第一步,我们先从京东商城爬取所有在售的手机数据。这里我们关心的主要是价格和配置信息,商品页面上的价格和配置信息像下面两张图所示:
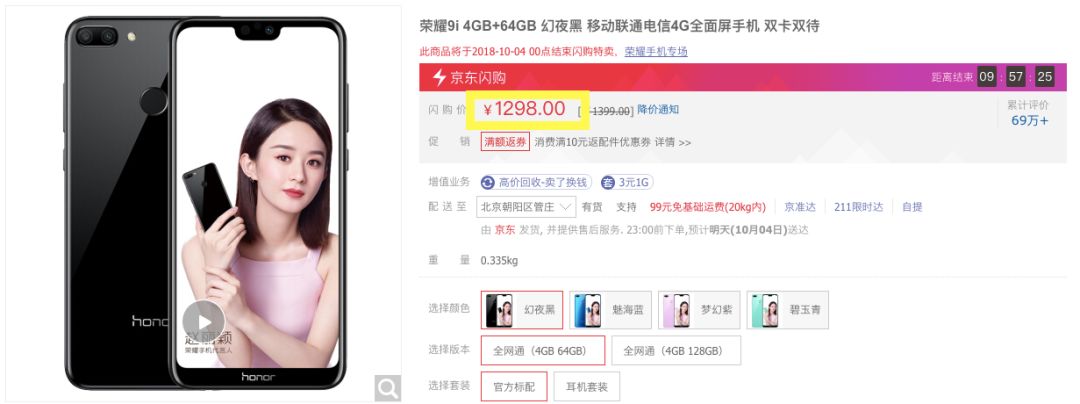
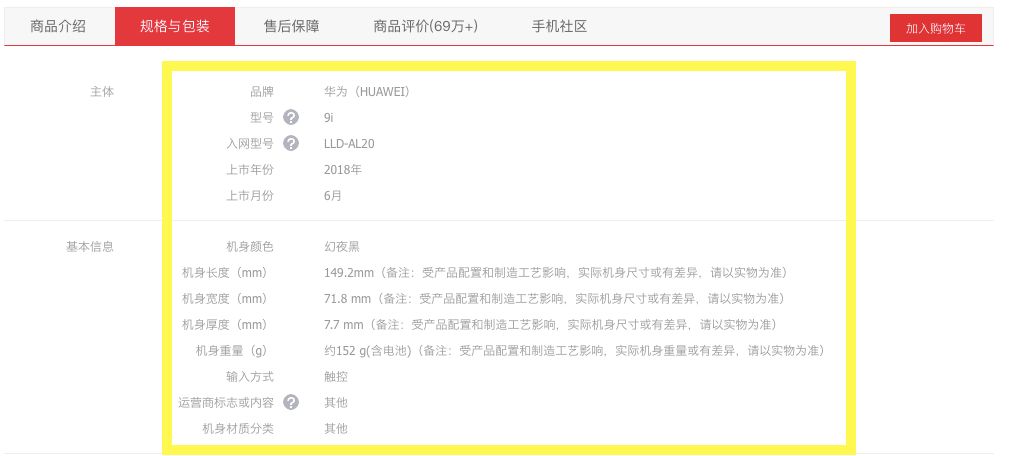
我们编写代码爬取所有手机的价格和配置信息,爬虫的核心代码如下:
# 获取手机单品的价格
def get_price(skuid):
url = "https://c0.3.cn/stock?skuId=" + str(skuid) + "&area=1_72_4137_0&venderId=1000004123&cat=9987,653,655&buyNum=1&choseSuitSkuIds=&extraParam={%22originid%22:%221%22}&ch=1&fqsp=0&pduid=15379228074621272760279&pdpin=&detailedAdd=null&callback=jQuery3285040"
r = requests.get(url, verify=False)
content = r.content.decode('GBK')
matched = re.search(r'jQueryd+((.*))', content, re.M)
if matched:
data = json.loads(matched.group(1))
price = float(data["stock"]["jdPrice"]["p"])
return price
return 0
# 获取手机的配置信息
def get_item(skuid, url):
price = get_price(skuid)
r = requests.get(url, verify=False)
content = r.content
root = etree.HTML(content)
nodes = root.xpath('.//div[@class="Ptable"]/div[@class="Ptable-item"]')
params = {"price": price, "skuid": skuid}
for node in nodes:
text_nodes = node.xpath('./dl')[0]
k = ""
v = ""
for text_node in text_nodes:
if text_node.tag == "dt":
k = text_node.text
elif text_node.tag == "dd" and "class" not in text_node.attrib:
v = text_node.text
params[k] = v
return params
# 获取一个页面中的所有手机信息
def get_cellphone(page):
url = "https://list.jd.com/list.html?cat=9987,653,655&page={}&sort=sort_rank_asc&trans=1&JL=6_0_0&ms=4#J_main".format(page)
r = requests.get(url, verify=False)
content = r.content.decode("utf-8")
root = etree.HTML(content)
cell_nodes = root.xpath('.//div[@class="p-img"]/a')
client = pymongo.MongoClient()
db = client[DB]
for node in cell_nodes:
item_url = fix_url(node.attrib["href"])
matched = re.search('item.jd.com/(d+).html', item_url)
skuid = int(matched.group(1))
saved = db.items.find({"skuid": skuid}).count()
if saved > 0:
print(saved)
continue
item = get_item(skuid, item_url)
# 结果存入MongoDB
db.items.insert(item)
需要注意的是,上面的get_price和get_item函数分别从两个url获取数据,这是因为配置信息可以直接从商品页面中解析得到,而价格信息需要从另外一个ajax请求里获得。爬下来的所有数据存入MongoDB。

过滤数据
爬下来的手机数据当中,信息完整的共有4700多条数据,这4700多部手机属于70个手机品牌。 这些品牌画成词云图是这样的:

手机的配置主要有以下这些参数:
是否双卡双待;
机身材质;
CPU型号;
内存大小;
存储容量;
电池容量;
屏幕材质;
屏幕大小;
分辨率;
摄像头。
强哥平时用手机主要是看看书、刷刷知乎微信、买买东西,所以选购新手机的时候最关心的就是速度、容量、待机时间这几项,对摄像头、屏幕材质倒不是特别在乎。考虑以上因素,在对数据做过滤的时候,我设定了以下几个条件:
CPU的品牌是高通;
内存大小大于等于6GB;
存储容量大于等于64GB;
电池容量大于3000mAh;
必须是双卡双待;
价格在1500元以内。
过滤数据的代码如下:
client = pymongo.MongoClient()
db = client[DB]
items = db.items.find({})
result = preprocess(items)
df = pd.DataFrame(result)
df_res = df[df.cpu_brand=="骁龙(Snapdragon)"][df.battery_cap >= 3000][df.rom >= 64][df.ram >= 6][df.dual_sim == True][df.price<=1500]
print(df_res[["brand", "model", "color", "cpu_brand", "cpu_freq", "cpu_core", "cpu_model", "rom", "ram", "battery_cap", "price"]].sort_values(by="price"))
首先从MongoDB里读取数据,然后创建DataFrame,对DataFrame里的数据按照上面的条件作选择。代码的最后一行将筛选出来的手机打印出来,并按价格从低到高排序。
经过了这样一轮筛选后,我们得到了下面的38款手机:
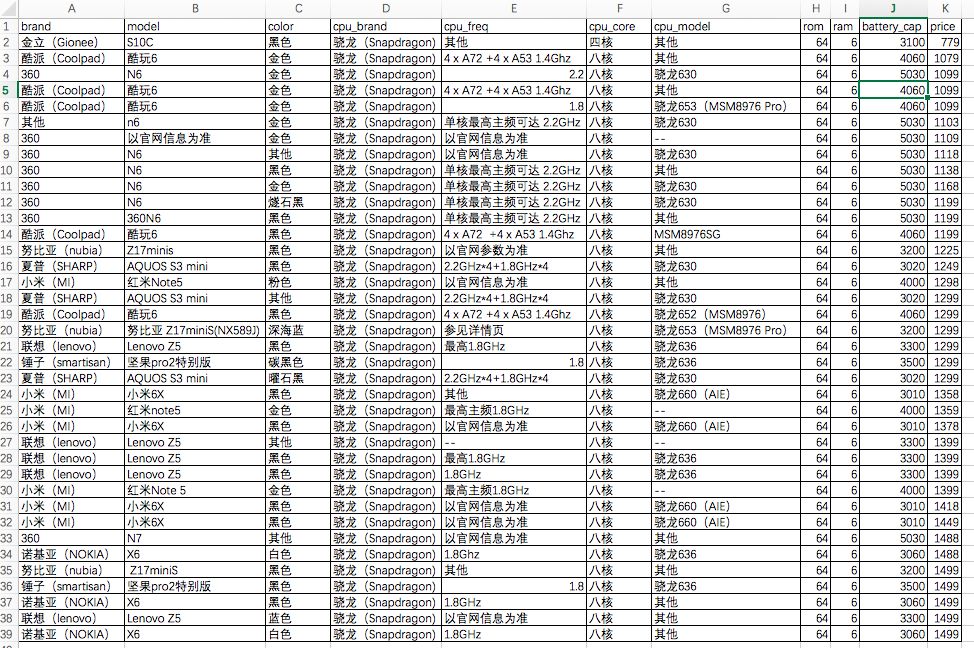
上面的几部手机配置都比较接近,但是网上对小米的评价普遍比较高,于是又在上面的列表里筛选出了所有的小米手机,得到下面7款:
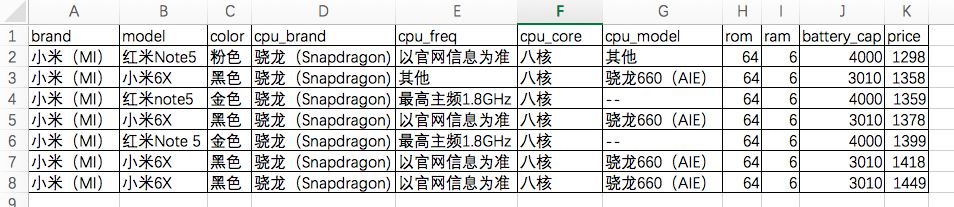
这里就变成了红米Note5和小米6X的PK了。价格上,两者不差上下。配置方面,网上查到红米Note5的cpu是骁龙636的(上面的表格里缺少红米Note5的cpu型号),相比小米6X的骁龙660,636虽然性能上不如660,但更省电,而且考虑到红米Note5 4000毫安的超大容量电池,最后决定了购买红米Note 5这一款。作为一款千元机,骁龙636八核CPU、6G大内存、64G大存储、5.99英寸大视野全面屏、前置相机+后置双摄、超长的待机时间,这款手机大概算是千元机中的机皇了。
作者:强哥,资深Python程序员,先后供职于Morgan Stanley和ebay,擅长爬虫、Web开发、数据分析。
本文系作者投稿,不代表CSDN立场。
微信改版了,
想快速看到CSDN的热乎文章,
赶快把CSDN公众号设为星标吧,
打开公众号,点击“设为星标”就可以啦!
“ 征稿啦”
CSDN 公众号秉持着「与千万技术人共成长」理念,不仅以「极客头条」、「畅言」栏目在第一时间以技术人的独特视角描述技术人关心的行业焦点事件,更有「技术头条」专栏,深度解读行业内的热门技术与场景应用,让所有的开发者紧跟技术潮流,保持警醒的技术嗅觉,对行业趋势、技术有更为全面的认知。
如果你有优质的文章,或是行业热点事件、技术趋势的真知灼见,或是深度的应用实践、场景方案等的新见解,欢迎联系 CSDN 投稿,联系方式:微信(guorui_1118,请备注投稿+姓名+公司职位),邮箱(guorui@csdn.net)。
推荐阅读:
放弃培训班自学编程,9 个月后我成为年薪 6 位数的软件工程师

这篇关于如何用 Python 选出好用又便宜的手机?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




